自己实现一个哈希表
class Node
{ int data;
String val;
Node next;
public Node(int data,String val)
{ this.val=val;
this.data=data;
}
}
class myhashtable
{ Node arr1[];
Node head=null;
Node tail=null;
int count=0;
private double load=0.75;
public myhashtable() {
this.arr1 = new Node[10];
}
public void reasize()
{
Node[] arr2=new Node[2*(arr1.length)];
//新创建一个数组,长度为原来长度的二倍,这里面不可以用Arrays.Copy来进行拷贝
for(int i=0;i<arr1.length;i++)
{
Node current=arr1[i];
while(current!=null)
{ Node curentnxst=current.next;
int key=current.data%(arr2.length);//获取新的下标
current.next=arr1[key];
arr2[key].next=current;
current=curentnxst;
}
}
this.arr1=arr2;
}
public int push(int key,String str)
{ if((1.0)*(count/arr1.length)>load)
{
reasize();
}
Node node=new Node(key,str);
int index=key%arr1.length;
Node current=arr1[index];
while(current!=null)//先遍历数组下标的整个链表,发现如果key相同,那么就更新val的值
{ if(current.data==key)
{
current.val=str;
return key;
}
current=current.next;
}
node.next=arr1[index];
arr1[index]=node;
count++;
return -1;
}
}1)链表的长度不会很长,控制在常数范围内,从JDK1.8开始,当数组长度超过64况且链表长度超过8就会转化成红黑树,也就是说虽然哈希表一直在和冲突作斗争,但是我们认为哈希表的冲突概率是不高的,冲突个数是可控的,也就是说每一个桶中的链表长度是一个常数,所以我们通常情况下认为哈希表的插入删除,查找的时间复杂度是O(1)
2)对于扩容来说:采用扩容之后,原来桶中的所有数据(数组中每一个链表的每一个元素必须要进行重新哈希),要遍历原来的链表,这个一定要注意不能在原来的数组上面进行2倍扩容,假设原来数组长度是10,没扩容之前数据14是被放在4下标的,但是假设扩容之后变成2倍,数据14就被放在14下标了
3)上面我们的哈希表是整形,但如果是任意类型,怎么办,如果key是String类型,总不可以让
一个字符串来对一个数组长度求余数吧;
上代码:
class Hello{
class Node<K,V>
{
K k;
V v;
Node next;
public Node(K k, V v) {
this.k = k;
this.v = v;
}
}
public class hasntable<K,V>
{
Node arr1[];
int count=0;
public hasntable() {
Node arr2[] = (Node[])new Node[10];
}
public void reasize()
{ Node[]arr2=new Node[2*(arr1.length)];
for(int j=0;j<arr1.length;j++)
{
Node current=arr1[j];
while(current!=null)
{
Node currentnext=current.next;
int hash=current.k.hashCode();
int index=hash%arr2.length;
current.next=arr1[index];
arr1[index].next=current;
current=currentnext;
}
}
}
public void push(K k,V v)
{ if((1.0)*(count)/(arr1.length)>0.75)
{
reasize();
}
// int index=k%arr1.length;此时k为引用类型
int hash=k.hashCode();
int index=hash%arr1.length;
Node<K,V> current=arr1[index];
while(current!=null)
{
//if(current.k==k)//是引用类型不可以直接比较虽然不报错,但是比较比较的是地址,而不是自定义类型的内容
if(current.k.equals(k))
{
current.v=v;
return;
}
current=current.next;
}
Node<K,V> node=new Node<>(k,v);
node.next=arr1[index];
arr1[index]=node;
count++;
}
}1)我们在向Map中写入自定义类型的时候,一定要重写hashCode和equals方法,当HashMap<Person, String> map=new HashMap<>();我们希望把id相同的Person放到哈希表的相同位置;
2)我们是用hashcode来确定这个k的位置上,使用equals比较哪一个k和我们当前这个k是相同的
package Demo;
import java.util.Objects;
class Person{
public int age;
public String name;
public Person(String name,int age){
this.name=name;
this.age=age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return age == person.age && Objects.equals(name, person.name);
}
@Override
public int hashCode() {
return Objects.hash(age, name);
}
}
public class HelloWorld{
public static void main(String[] args) {
Person person1=new Person("李佳伟",10);
Person person2=new Person("李佳伟",10);
//我们认为person1和person2是同一个人,应该放在数组的同一个位置
按理说他们得到的hashcode%array.length应该是相同的,但是运行的时候
//发现他们的哈希值不一样,但是我们重写hashcode之后,得到的hashcode是相同的
这样我们就可以认为两个逻辑一样的人,一定会存放到同一个位置
//当自定义类型作为Key值的时候,一定要重写我们的hashcode,否则就会出现本以上两个一样的人
最终你的代码在逻辑上认为他不是一个人了
System.out.println(person1.hashCode());
System.out.println(person2.hashCode());
}
}1)hashcode一样,那么equals不一定一样,hashcode一样只能证明两个元素在数组的相同位置,但是一个数组的一个位置下面有多个元素组成的链表
2)equals相同,hashcode一定相同
package Demo;
import java.util.Objects;
class Person{
public int age;
public String name;
public Person(String name,int age){
this.name=name;
this.age=age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return age == person.age && Objects.equals(name, person.name);
}
@Override
public int hashCode() {
return Objects.hash(age, name);
}
}
class MyHashMap<K,V>{
public int UsedSize=0;
public Node<K,V>[] array=(Node<K, V>[])new Node[10];
static class Node<K,V>{
public K k;
public V v;
public Node next;
public Node(K k,V v)
{
this.k=k;
this.v=v;
}
}
public void put(K k,V v)
{
int index=k.hashCode()%array.length;//得到这个值对应的数组下标,必须重写hashcode
//否则两个逻辑上相同的值会得到不同的哈希值,就会被放到数组种不同的位置
Node current=array[index];
while(current!=null){
if(current.k.equals(k))//不能使用==
//现在k是一个引用类型,使用==默认比较的是地址,所以我们使用equals,但是直接使用equals比较的还是两个引用的地址《
//所以我们要重写equals方法,来进行比较他们具体的内容
{
current.v=v;
return;
}
}
//我们是头插法来进行插入元素
Node<K,V> node=new Node<>(k,v);
node.next=array[index];
array[index]=node;
UsedSize++;
//判断是否负载因子超过了0.75,如果超过,就进行扩容
if(UsedSize/array.length>0.75){
CreateBigSizeArray(array);
}
}
private void CreateBigSizeArray(Node<K,V>[] array) {
Node[] newArray=new Node[2* array.length];
for(int i=0;i<array.length;i++){//遍历每一个哈希桶,也就是说遍历数组的每一个元素
Node current=array[i];//遍历数组下的每一个链表
while(current!=null){
Node child=current.next;
int index=current.v.hashCode()%newArray.length;
current.next=array[index];
array[index]=current;
current=child;
}
}
}
}
public class HelloWorld{
public static void main(String[] args) {
MyHashMap<Person,String> map=new MyHashMap<>();
map.put(new Person("李佳伟",90),"bit");
map.put(new Person("李嘉欣",100),"kig");
System.out.println(map);
}
}解析HashMap源码:
1)public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>,Cloneable,Serializable(是可序列化的)
AbstractMap是一个普通的抽象类,Serializable是可序列化的,说明可以把一个对象变成字符串
2)static final int DEFAULT_INITIAL_CAPACITY=1<<4;说明他的默认容量是16,必须是2的次幂
3)static final int MAXIMUM_CAPACITY=1<<30;说明他的最大长度是2^30;
4)static final float DEFAUIT_LOAD_FACTOR=0.75f;默认的负载因子
5)static final TREEINF_THRESHOLD=8;这是树化的条件(链表长度超过8)
6)static final int UNTREEIFY_THRESHOLD=6;不树化
这是桶的链表还原阈值:即红黑树转化成链表的值,当进行扩容之后,此时的HashMap的值会进行重新计算,在进行重新计算存储位置后当原有的红黑树数量小于6之后,会将红黑树转化成链表
7)static final int min_treeinfy_capacity=64
8)Node在哈希表中是一个内部类
9)HashMap一共有三个构造方法
1))无参构造方法
2))传输一个初始容量
3))传输一个初始容量和指定负载因子
位运算算效率高
public V put(K key,V value)
{
return putVal(hash(key),key,value,false,true);//第四个参数表示是老元素的值不会保留,会进行覆盖
}
static final int hash(Object Key)
{
int h;
return (key==null?0:(h==key.hashcode())^(h>>>16);
//得到的哈希地址已经是32位了,为了混合哈希值的高位和低位,高半区和低半区做异或,混合原始哈希码的高位和地位,增加低位的随机性,掺杂了高位的部分特征,混合之后的低位核心目的是为了让hash值的散列度更高,尽可能减少hash表的hash冲突,从而提升数据查找的性能,并且混合后的值也保持了高位的特征
}
这个哈希函数的作用就是根据key的哈希值来进行计算这个元素在数组中的位置,求解这个哈希值的过程就是哈希算法,异或就是相同为0,不同为1
1)当调用没有参数的构造方法的时候
当数组长度是0或者数组的引用为空的时候,第一次put操作的时候,就会执行reasize()的方法来进行扩容,默认的初始容量是16;
2)根据哈希值来进行计算索引的时候
(在寻找数组的下标的时候,在咱们之前的代码中时使用Key的哈希值%数组长度,但是在HashMap的源码中是用数组下标=(数组长度-1)&hash)
4&15==4%16如果数组的长度是2的次幂,这样hash%n-1的值(也就是得到位置)相等,位运算的速度更快,效率更高;再会new Node;
(n-1)&hash保证n是偶数(&都为1才是1,否则就是0)
如果n是偶数,那么n-1的最后一位一定是1,当与hash函数(最后一位有可能是进行0也有可能是1)&运算的时候,得到的最后一位是0或者1;即有可能是奇数也有可能是偶数
如果n是奇数,那么n-1的最后一位是0,那么与hash函数进行&操作的时候,会得到的下标的最后一位为0;最后只能得到偶数下标;
就是说我们以初始容量为16来进行举例,16-1=15,那么15的二进制序列就是001111,我们可以看出一个奇数二进制最后一位必然是1,当一个hash值参与运算的时候,最后一位可能是1,也有可能是0,当一个偶数和hash值进行与运算的时候最后一位必然是0,会造成有些位置永远也无法映射上值
3)保证数组容量是偶数,才可以保证最后的下标即是奇数下标又是偶数下标
HashMap和HashTable的区别?
咱们的hashMap是允许key和value是空值的,但是hashtable这样的线程安全的集合数不允许插入空的key和value的,在咱们ConcurrentHashMap的源码当中,如果key为空,或者value为空,直接抛出空指针异常
1)两者最主要的区别在于Hashtable是线程安全,而HashMap则非线程安全
2)HashMap可以使用null作为key,不过建议还是尽量避免这样使用。HashMap以null作为key时,总是存储在table数组的第一个节点上。而Hashtable则不允许null作为key。
3)HashMap继承了AbstractMap,HashTable继承Dictionary抽象类,两者均实现Map接口。
4)HashMap的初始容量为16,Hashtable初始容量为11,两者的填充因子默认都是0.75。
5)HashMap扩容时是当前容量翻倍即:capacity*2,Hashtable扩容时是容量翻倍+1即:capacity*2+1。
6)HashMap数据结构:数组+链表+红黑树(jdk1.8里加入了红黑树的实现,当链表的长度大于8时,转换为红黑树的结构),Hashtable数据结构:数组+链表。7)HashMap和HashTable都实现了Serializable接口,因此它支持序列化,实现了Cloneable接口,能被克隆。
8)计算哈希值也是不同的:hashMap先计算出哈希值,然后无符号右移16位,然后再进行按位与操作,但是hashTable
int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length;
总结:
1)首先查看数组长度是否为空,如果为空,就进行第一次扩容
2)计算索引:通过哈希算法,找到键值对在数组中的位置
3)插入元素:
3.1)如果当前元素位置为空,直接插入数据
3.2)不为空,判断是否为红黑树,是红黑树直接插入键值对
3.3)如果他不是红黑树,接下来判断,若链表长度大于8,数组长度超过64,直接将链表转化成红黑树,然后将数据插入到树中
3.4)如果不满足这两个条件的任意一个,那么直接遍历链表,key已经存在直接覆盖value
4)再次扩容,超过负载因子,直接进行扩容,重新哈希
5)超过数组容量进行扩容
HashMap的常见问题:
HashMap的节点有hash值,key,val,next
1)程序问题:
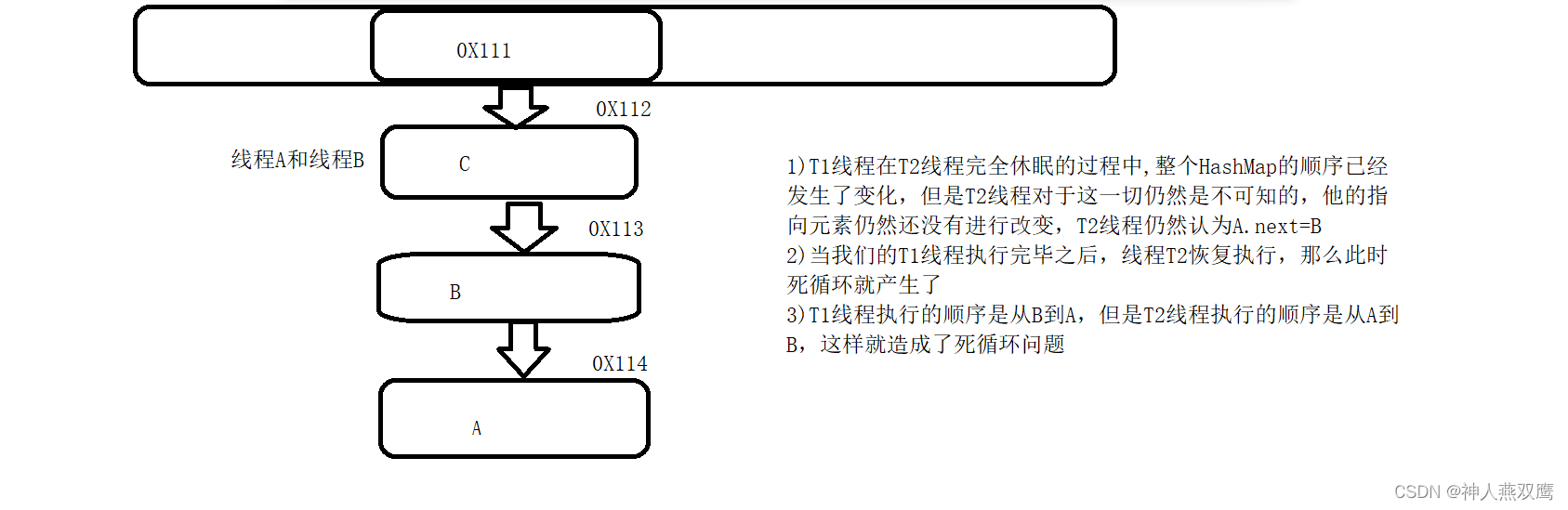
在HashMapJDK1.7的程序里面会出现死循环或者是数据覆盖的问题;死循环由于是HashMap的自身的运行机制再加上并发操作
1)比如说现在数组中的某一个元素下面挂着链表,链表中的元素从上到下的顺序是A B C ,但是JDK1.7用的是头插法,那么进行扩容之后为数据位置是C B A,这是死循环的前提,是由于HashMap并发进行扩容而导致的
2)但是线程1扩容完成之后数据的变化为
2)数据覆盖问题:
1)线程T1进行添加的时候,判断某一个位置可以进行插入元素了,但还没有真正地进行插入操作,时间片就用完了(此时线程1已经判断好这个位置是空了,刚刚要进行插入操作,就被调度器给抢走了)
2)线程2也想要进行插入操作,并且T2要进行插入的数据产生的哈希值和T1要进行插入的数据是相同的,由于此位置没有任何元素(T1只是进行判断,刚想要插入值就被调度器给抢走了),于是此时线程2就把自己的值存入到当前位置了
3)T1线程恢复执行之后,因为非空判断已经执行完了,他是无法感知当前位置已经有值了,于是就把自己的值插入到了该位置,于是T2线程插入的值就被覆盖了
3)HashMap无序性问题------换成LinkedHashMap

![[附源码]计算机毕业设计springboot港口集团仓库管理系统](https://img-blog.csdnimg.cn/6fb308034bb049abab0a85d1118d05f9.png)


![[附源码]计算机毕业设计SpringBoot海南与东北的美食文化差异及做法的研究展示平台](https://img-blog.csdnimg.cn/6bd78494217845f5821e685b27a05df8.png)