报错
Caused by: java.lang.RuntimeException: java.io.IOException: java.io.IOException: Too many bytes before newline: 2147483648
at org.apache.hadoop.mapred.split.TezGroupedSplitsInputFormat$TezGroupedSplitsRecordReader.initNextRecordReader(TezGroupedSplitsInputFormat.java:206)
at org.apache.hadoop.mapred.split.TezGroupedSplitsInputFormat$TezGroupedSplitsRecordReader.<init>(TezGroupedSplitsInputFormat.java:145)
at org.apache.hadoop.mapred.split.TezGroupedSplitsInputFormat.getRecordReader(TezGroupedSplitsInputFormat.java:111)
at org.apache.tez.mapreduce.lib.MRReaderMapred.setupOldRecordReader(MRReaderMapred.java:156)
at org.apache.tez.mapreduce.lib.MRReaderMapred.setSplit(MRReaderMapred.java:82)
at org.apache.tez.mapreduce.input.MRInput.initFromEventInternal(MRInput.java:703)
at org.apache.tez.mapreduce.input.MRInput.initFromEvent(MRInput.java:662)
at org.apache.tez.mapreduce.input.MRInputLegacy.checkAndAwaitRecordReaderInitialization(MRInputLegacy.java:150)
at org.apache.tez.mapreduce.input.MRInputLegacy.init(MRInputLegacy.java:114)
at org.apache.hadoop.hive.ql.exec.tez.MapRecordProcessor.getMRInput(MapRecordProcessor.java:543)
at org.apache.hadoop.hive.ql.exec.tez.MapRecordProcessor.init(MapRecordProcessor.java:189)
at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.initializeAndRunProcessor(TezProcessor.java:268)
... 16 more
Caused by: java.io.IOException: java.io.IOException: Too many bytes before newline: 2147483648
at org.apache.hadoop.hive.io.HiveIOExceptionHandlerChain.handleRecordReaderCreationException(HiveIOExceptionHandlerChain.java:97)
at org.apache.hadoop.hive.io.HiveIOExceptionHandlerUtil.handleRecordReaderCreationException(HiveIOExceptionHandlerUtil.java:57)
at org.apache.hadoop.hive.ql.io.HiveInputFormat.getRecordReader(HiveInputFormat.java:433)
at org.apache.hadoop.mapred.split.TezGroupedSplitsInputFormat$TezGroupedSplitsRecordReader.initNextRecordReader(TezGroupedSplitsInputFormat.java:203)
... 27 more
Caused by: java.io.IOException: Too many bytes before newline: 2147483648
at org.apache.hadoop.util.LineReader.readDefaultLine(LineReader.java:251)
at org.apache.hadoop.util.LineReader.readLine(LineReader.java:176)
at org.apache.hadoop.mapreduce.lib.input.UncompressedSplitLineReader.readLine(UncompressedSplitLineReader.java:94)
at org.apache.hadoop.mapred.LineRecordReader.<init>(LineRecordReader.java:149)
at org.apache.hadoop.mapred.TextInputFormat.getRecordReader(TextInputFormat.java:67)
at org.apache.hadoop.hive.ql.io.RecordReaderWrapper.create(RecordReaderWrapper.java:72)
at org.apache.hadoop.hive.ql.io.HiveInputFormat.getRecordReader(HiveInputFormat.java:430)
... 28 more
], TaskAttempt 3 failed, info=[Error: Error while running task ( failure ) : attempt_1667789273844_0742_1_00_000028_3:java.lang.RuntimeException: java.lang.RuntimeException: java.io.IOException: java.io.IOException: Too many bytes before newline: 2147483648
at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.initializeAndRunProcessor(TezProcessor.java:298)
at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.run(TezProcessor.java:252)
at org.apache.tez.runtime.LogicalIOProcessorRuntimeTask.run(LogicalIOProcessorRuntimeTask.java:374)
at org.apache.tez.runtime.task.TaskRunner2Callable$1.run(TaskRunner2Callable.java:75)
at org.apache.tez.runtime.task.TaskRunner2Callable$1.run(TaskRunner2Callable.java:62)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1898)
at org.apache.tez.runtime.task.TaskRunner2Callable.callInternal(TaskRunner2Callable.java:62)
at org.apache.tez.runtime.task.TaskRunner2Callable.callInternal(TaskRunner2Callable.java:38)
at org.apache.tez.common.CallableWithNdc.call(CallableWithNdc.java:36)
at com.google.common.util.concurrent.TrustedListenableFutureTask$TrustedFutureInterruptibleTask.runInterruptibly(TrustedListenableFutureTask.java:125)
at com.google.common.util.concurrent.InterruptibleTask.run(InterruptibleTask.java:69)
at com.google.common.util.concurrent.TrustedListenableFutureTask.run(TrustedListenableFutureTask.java:78)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.RuntimeException: java.io.IOException: java.io.IOException: Too many bytes before newline: 2147483648
at org.apache.hadoop.mapred.split.TezGroupedSplitsInputFormat$TezGroupedSplitsRecordReader.initNextRecordReader(TezGroupedSplitsInputFormat.java:206)
at org.apache.hadoop.mapred.split.TezGroupedSplitsInputFormat$TezGroupedSplitsRecordReader.<init>(TezGroupedSplitsInputFormat.java:145)
at org.apache.hadoop.mapred.split.TezGroupedSplitsInputFormat.getRecordReader(TezGroupedSplitsInputFormat.java:111)
at org.apache.tez.mapreduce.lib.MRReaderMapred.setupOldRecordReader(MRReaderMapred.java:156)
at org.apache.tez.mapreduce.lib.MRReaderMapred.setSplit(MRReaderMapred.java:82)
at org.apache.tez.mapreduce.input.MRInput.initFromEventInternal(MRInput.java:703)
at org.apache.tez.mapreduce.input.MRInput.initFromEvent(MRInput.java:662)
at org.apache.tez.mapreduce.input.MRInputLegacy.checkAndAwaitRecordReaderInitialization(MRInputLegacy.java:150)
at org.apache.tez.mapreduce.input.MRInputLegacy.init(MRInputLegacy.java:114)
at org.apache.hadoop.hive.ql.exec.tez.MapRecordProcessor.getMRInput(MapRecordProcessor.java:543)
at org.apache.hadoop.hive.ql.exec.tez.MapRecordProcessor.init(MapRecordProcessor.java:189)
at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.initializeAndRunProcessor(TezProcessor.java:268)
... 16 more
Caused by: java.io.IOException: java.io.IOException: Too many bytes before newline: 2147483648
at org.apache.hadoop.hive.io.HiveIOExceptionHandlerChain.handleRecordReaderCreationException(HiveIOExceptionHandlerChain.java:97)
at org.apache.hadoop.hive.io.HiveIOExceptionHandlerUtil.handleRecordReaderCreationException(HiveIOExceptionHandlerUtil.java:57)
at org.apache.hadoop.hive.ql.io.HiveInputFormat.getRecordReader(HiveInputFormat.java:433)
at org.apache.hadoop.mapred.split.TezGroupedSplitsInputFormat$TezGroupedSplitsRecordReader.initNextRecordReader(TezGroupedSplitsInputFormat.java:203)
... 27 more
Caused by: java.io.IOException: Too many bytes before newline: 2147483648
at org.apache.hadoop.util.LineReader.readDefaultLine(LineReader.java:251)
at org.apache.hadoop.util.LineReader.readLine(LineReader.java:176)
at org.apache.hadoop.mapreduce.lib.input.UncompressedSplitLineReader.readLine(UncompressedSplitLineReader.java:94)
at org.apache.hadoop.mapred.LineRecordReader.<init>(LineRecordReader.java:149)
at org.apache.hadoop.mapred.TextInputFormat.getRecordReader(TextInputFormat.java:67)
at org.apache.hadoop.hive.ql.io.RecordReaderWrapper.create(RecordReaderWrapper.java:72)
at org.apache.hadoop.hive.ql.io.HiveInputFormat.getRecordReader(HiveInputFormat.java:430)
... 28 more发生背景
同事采用hive的opencsv serde去load csv数据(这套我经常用没啥问题)。他也用过几次都ok,突然某天就说这个问题。
具体现象
select * from odsctdata.ods_ct_order_list_csv limit 10 --ok
select count(1),max(),min() from odsctdata.ods_ct_order_list_csv --报错
错误具体为:Too many bytes before newline: 2147483648
此时看到这个错,大家第一反应是从哪里解决? 看看各位的思路,欢迎评论区留言。
1.2147483648 ,这个数值会不会偏小?就和内存一样 hive的有些参数默认是比较保守的,可以适当调大点,就避免很多报错了。 通过set -v 我查不到这个值,说明应该不是属性问题。
2.Too many bytes before newline ,这个报错可能是hive源码里有的报错信息,我们看下这个报错的具体位置,可能是有些属性需要我们额外去配置,或者其他问题,看源码总是好的。
下载了hive源码,无
3.看具体的报错信息
Caused by: java.io.IOException: Too many bytes before newline: 2147483648
at org.apache.hadoop.util.LineReader.readDefaultLine(LineReader.java:251)
at org.apache.hadoop.util.LineReader.readLine(LineReader.java:176)
这里提到了org.apache.hadoop.util.LineReader,查看源码。与之吻合。
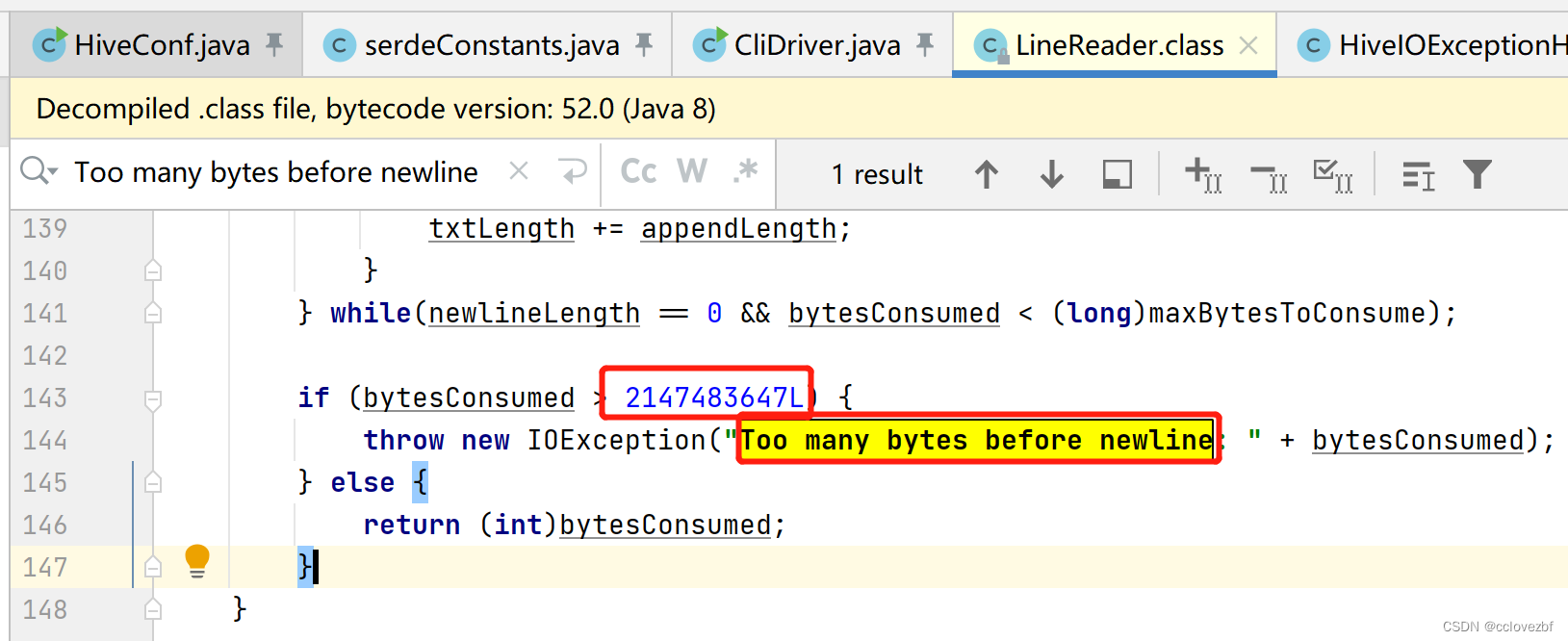
具体看下这个方法
看了下大概就是读取每一行的数据,并且获取大小,对大小有个判断。
private int readDefaultLine(Text str, int maxLineLength, int maxBytesToConsume) throws IOException {
str.clear();
int txtLength = 0;
int newlineLength = 0;
boolean prevCharCR = false;
long bytesConsumed = 0L;
do {
int startPosn = this.bufferPosn;
if (this.bufferPosn >= this.bufferLength) {
startPosn = this.bufferPosn = 0;
if (prevCharCR) {
++bytesConsumed;
}
this.bufferLength = this.fillBuffer(this.in, this.buffer, prevCharCR);
if (this.bufferLength <= 0) {
break;
}
}
while(this.bufferPosn < this.bufferLength) {
if (this.buffer[this.bufferPosn] == 10) {
newlineLength = prevCharCR ? 2 : 1;
++this.bufferPosn;
break;
}
if (prevCharCR) {
newlineLength = 1;
break;
}
prevCharCR = this.buffer[this.bufferPosn] == 13;
++this.bufferPosn;
}
int readLength = this.bufferPosn - startPosn;
if (prevCharCR && newlineLength == 0) {
--readLength;
}
bytesConsumed += (long)readLength;
int appendLength = readLength - newlineLength;
if (appendLength > maxLineLength - txtLength) {
appendLength = maxLineLength - txtLength;
}
if (appendLength > 0) {
str.append(this.buffer, startPosn, appendLength);
txtLength += appendLength;
}
} while(newlineLength == 0 && bytesConsumed < (long)maxBytesToConsume);
if (bytesConsumed > 2147483647L) {
throw new IOException("Too many bytes before newline: " + bytesConsumed);
} else {
return (int)bytesConsumed;
}
}接着我们去看csv文件。

看到这两个命令,有经验的小伙伴已经发现不对劲了。
41w条数据,足足有3.2G。有点奇奇怪怪。
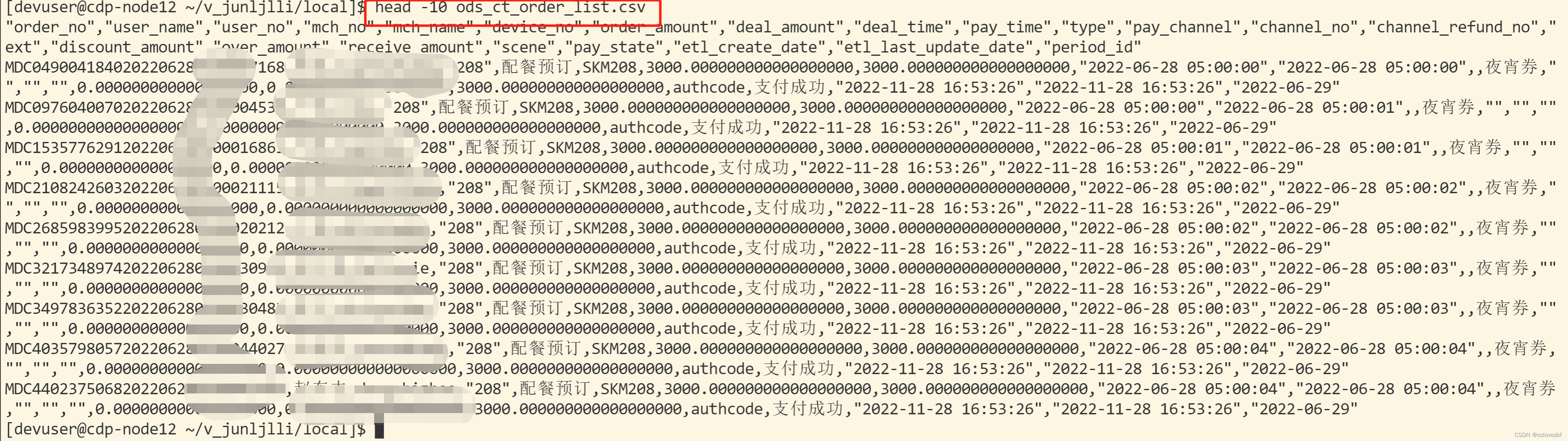 继续再看下 ,发现更加奇怪了。每一行的数据也不多,csv行数也不多,怎么会有这么大?
继续再看下 ,发现更加奇怪了。每一行的数据也不多,csv行数也不多,怎么会有这么大?
总共41w数据,那我split 按照10w分5个文件看下,因为怀疑有一条数据特别大
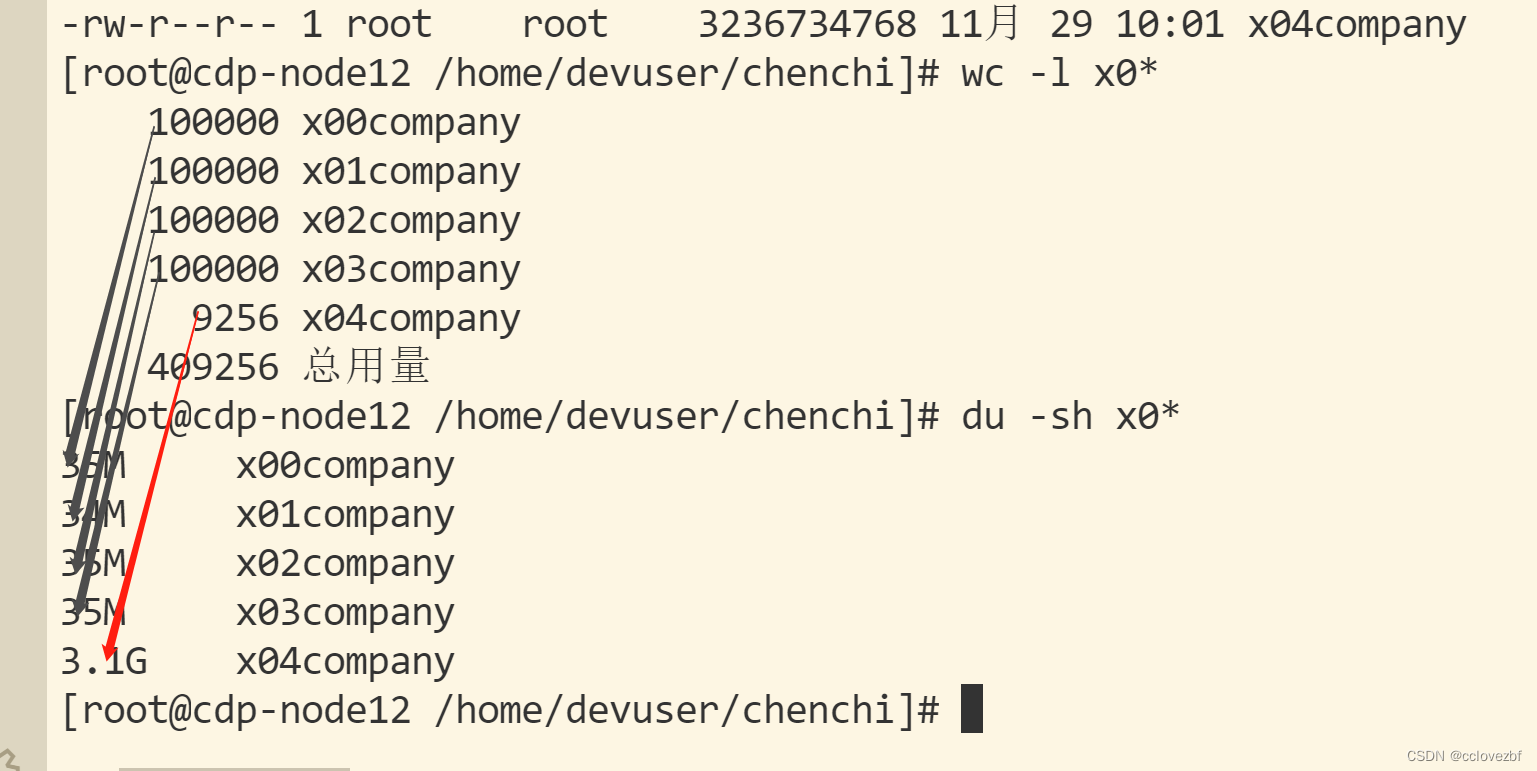
发现最后一个文件特别大。有问题。此时已经怀疑是最后一条数据有问题了,但是没证据咋办。
总行数409256 我分成2个文件409255+1就行了。
 此时问题数据已经查到。。就是最后一条。
此时问题数据已经查到。。就是最后一条。
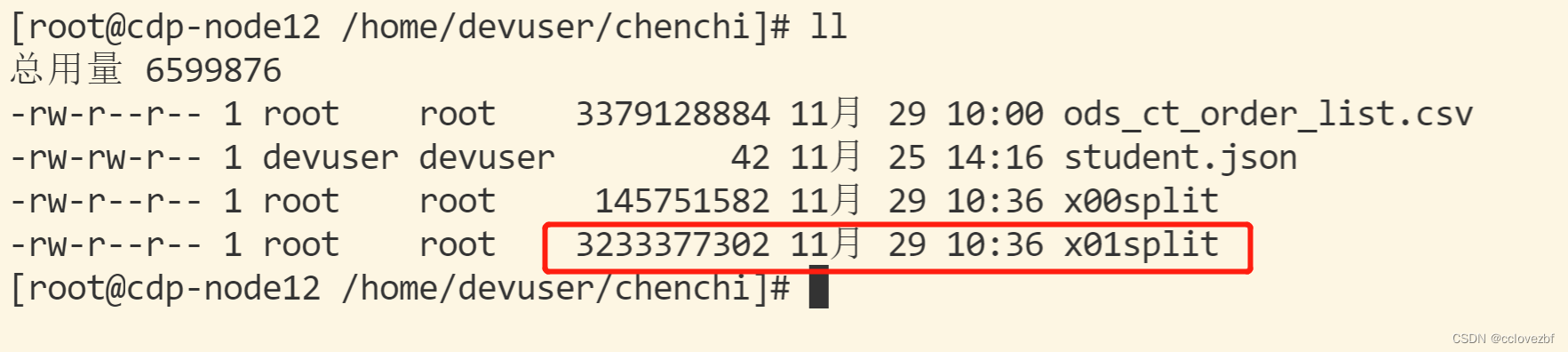
3233377302>2147483647L
再来说说这个数字。2147483647 咋一看好像啥也不是和程序员的1024好像没有任何关系
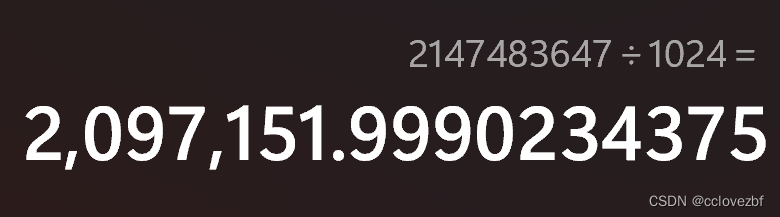
但是如果是一个年迈的程序员,一眼就可以看出这个数字很熟悉,比如我 哈哈。
2147483647+1=2147483648=1024*1024*1024*2。说明hive的一行数据不能超过2G。
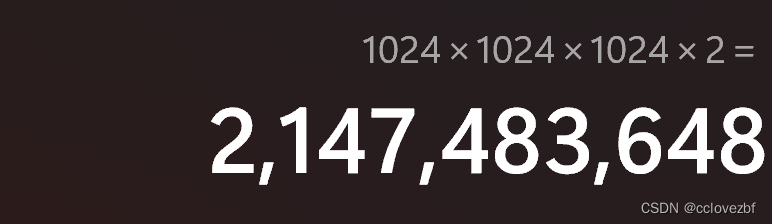
至此问题解决。等我问题解决的时候同事来了一句。他导出csv文件的时候count(1)了下有900w数据。。。。 我还忙活啥劲呢。。
如果这篇帮到你,点个赞是对我最大的支持。






![[附源码]SSM计算机毕业设计学生互评的在线作业管理系统JAVA](https://img-blog.csdnimg.cn/0b2c341d087d4c139d59f6176e478447.png)