CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
1.Long-Term Photometric Consistent Novel View Synthesis with Diffusion Models

标题:具有扩散模型的长期光度一致的新视图合成
作者:Jason J. Yu, Fereshteh Forghani, Konstantinos G. Derpanis, Marcus A. Brubaker
文章链接:https://arxiv.org/abs/2304.10700
项目代码:https://yorkucvil.github.io/Photoconsistent-NVS/

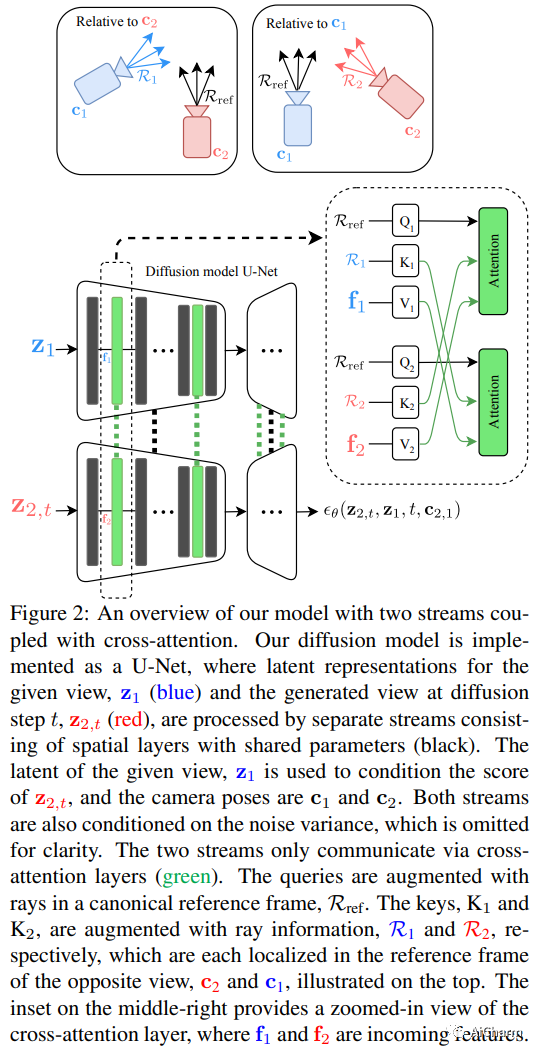
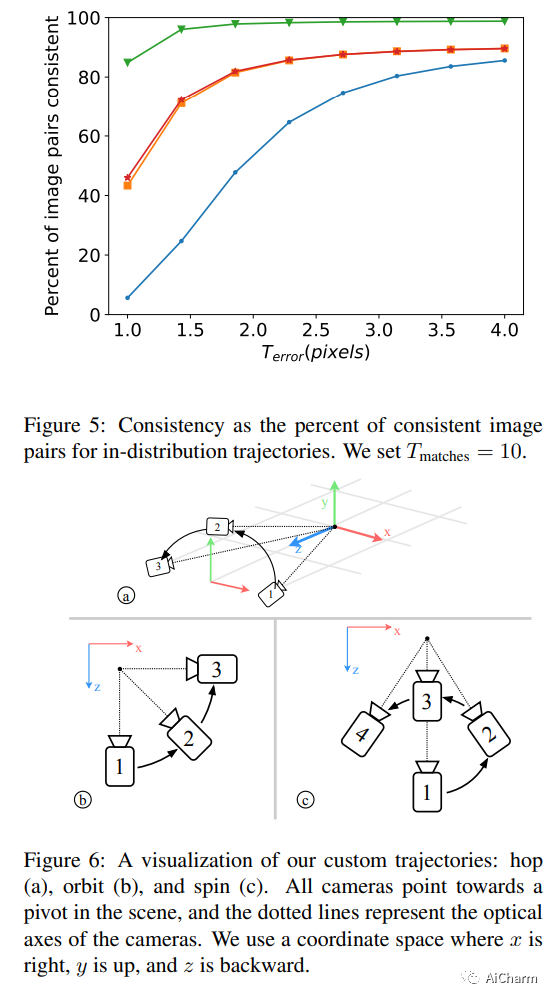
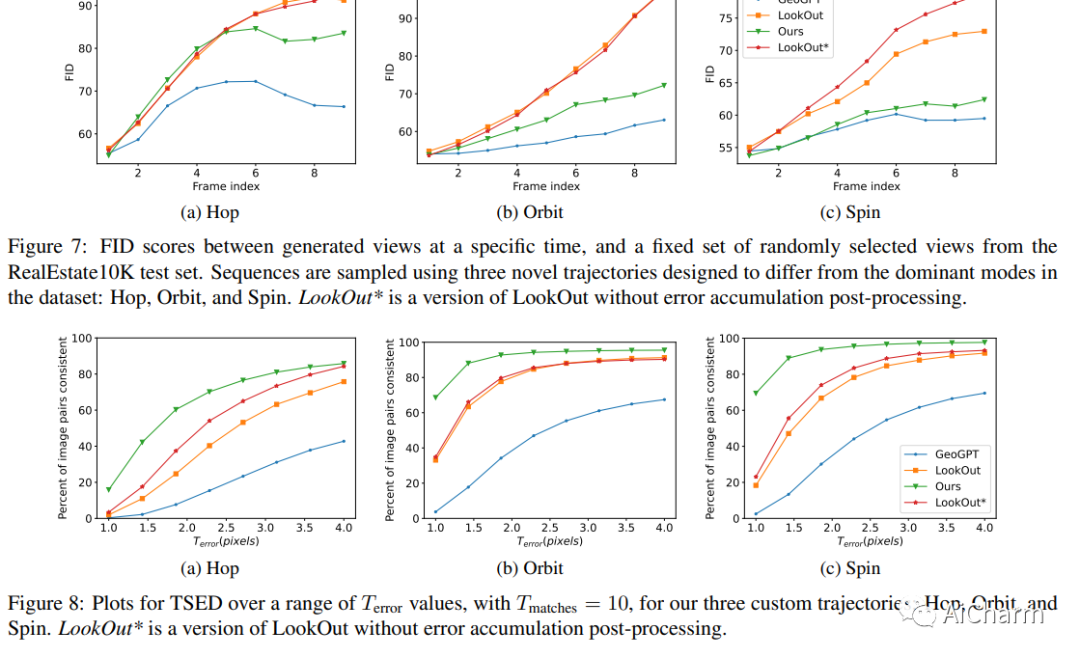
摘要:
从单个输入图像合成新的视图是一项具有挑战性的任务,其目标是从可能被大运动分开的所需相机姿势生成场景的新视图。由于场景内(即遮挡)和视野外的未观察到的元素,这种合成任务的高度不确定性使得使用生成模型来捕获各种可能的输出很有吸引力。在本文中,我们提出了一种新颖的生成模型,该模型能够生成与指定相机轨迹一致的一系列逼真图像,以及单个起始图像。我们的方法以基于自回归条件扩散的模型为中心,该模型能够以几何一致的方式内插可见场景元素,并外推视图中未观察到的区域。调节仅限于捕获单个相机视图的图像和新相机视图的(相对)姿势。为了测量一系列生成视图的一致性,我们引入了一个新的度量标准,即阈值对称对极距离 (TSED),以测量序列中一致帧对的数量。虽然先前的方法已被证明可以在成对的视图中产生高质量的图像和一致的语义,但我们根据我们的指标凭经验表明它们通常与所需的相机姿势不一致。相比之下,我们证明我们的方法可以产生逼真的图像和视图一致的图像。
2.VisFusion: Visibility-aware Online 3D Scene Reconstruction from Videos(CVPR 2023)

标题:VisFusion:基于视频的可见性在线 3D 场景重建
作者:Huiyu Gao, Wei Mao, Miaomiao Liu
文章链接:https://arxiv.org/abs/2304.10687
项目代码:https://github.com/huiyu-gao/VisFusion
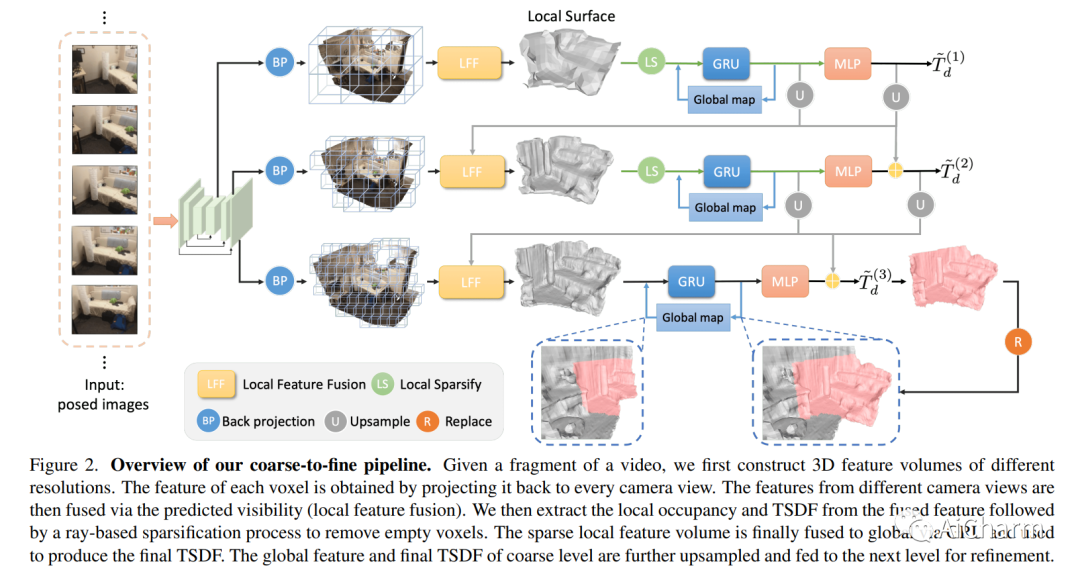
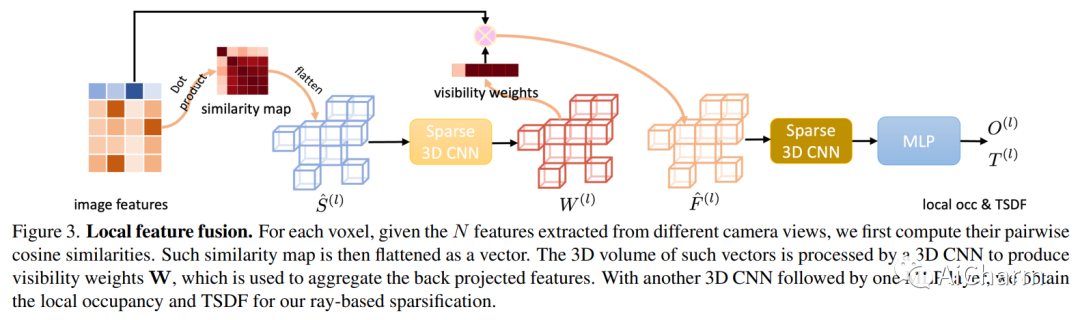
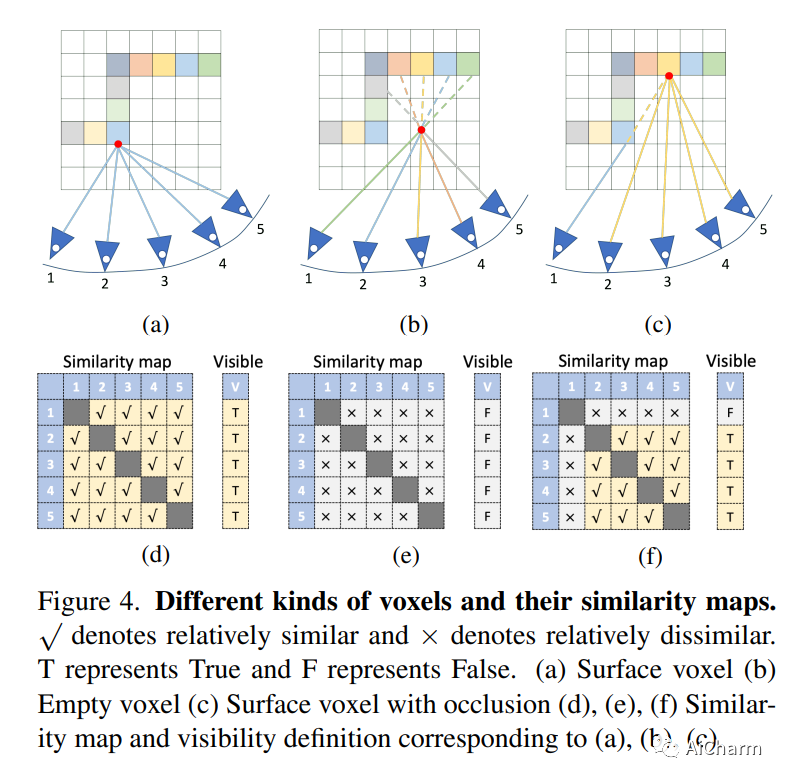
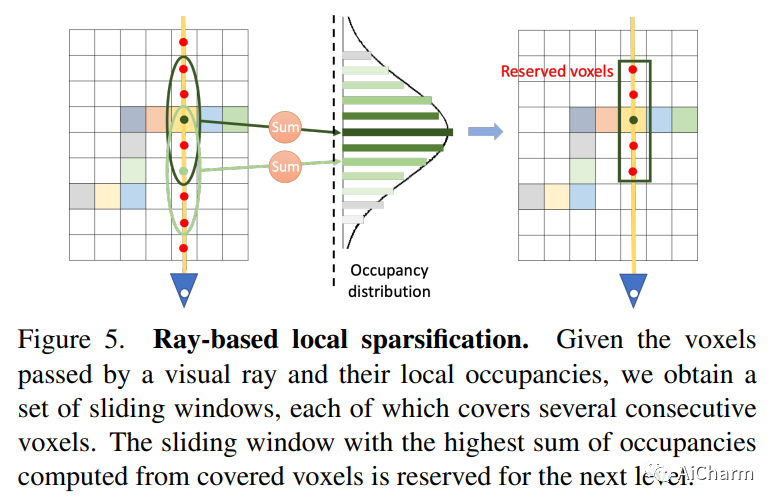
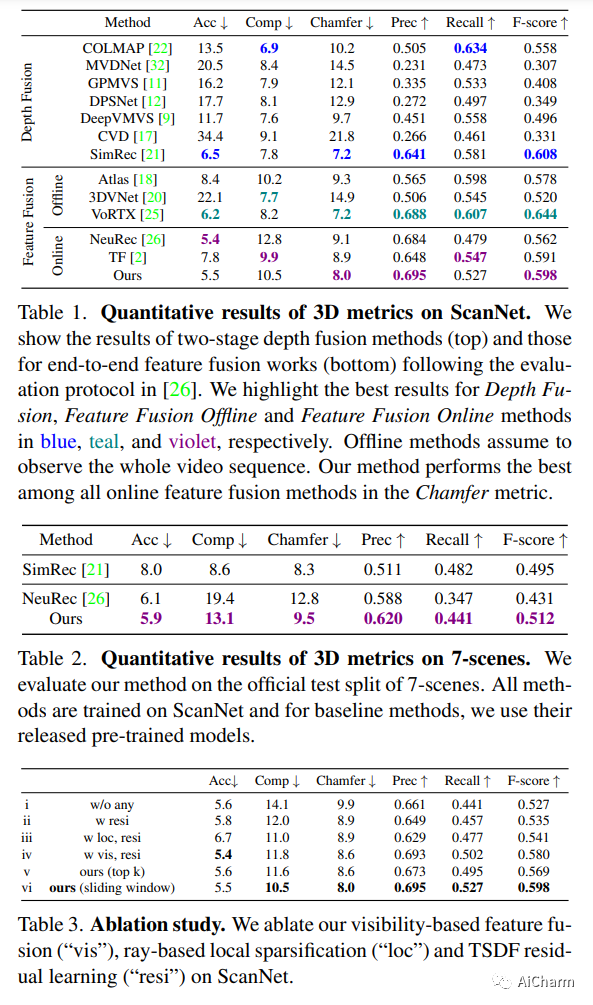
摘要:
我们提出了 VisFusion,这是一种基于姿势单眼视频的可见性感知在线 3D 场景重建方法。特别是,我们的目标是从体积特征重建场景。与以前的重建方法不同,它从输入视图中聚合每个体素的特征而不考虑其可见性,我们的目标是通过从每个图像对中的投影特征计算出的相似性矩阵明确推断其可见性来改进特征融合。继之前的工作之后,我们的模型是一个由粗到细的管道,包括体积稀疏化过程。与他们使用固定占用阈值全局稀疏体素的作品不同,我们沿着每条视觉射线对局部特征量执行稀疏化,以每条射线至少保留一个体素以获得更多细节。然后将稀疏局部体积与全局体积融合以进行在线重建。我们进一步建议通过跨尺度学习其残差以从粗到细的方式预测 TSDF,从而获得更好的 TSDF 预测。基准测试的实验结果表明,我们的方法可以在更多场景细节的情况下实现卓越的性能。
3.Factored Neural Representation for Scene Understanding
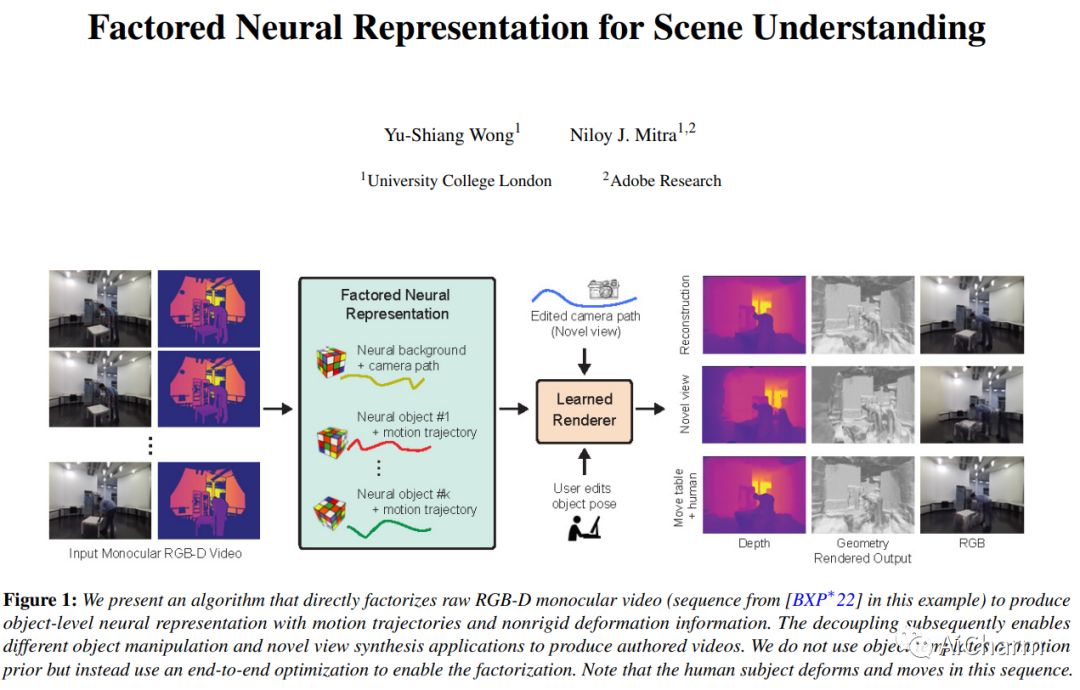
标题:用于场景理解的分解神经表示
作者:Yu-Shiang Wong, Niloy J. Mitra
文章链接:https://arxiv.org/abs/2304.10950
项目代码:https://yushiangw.github.io/factorednerf/

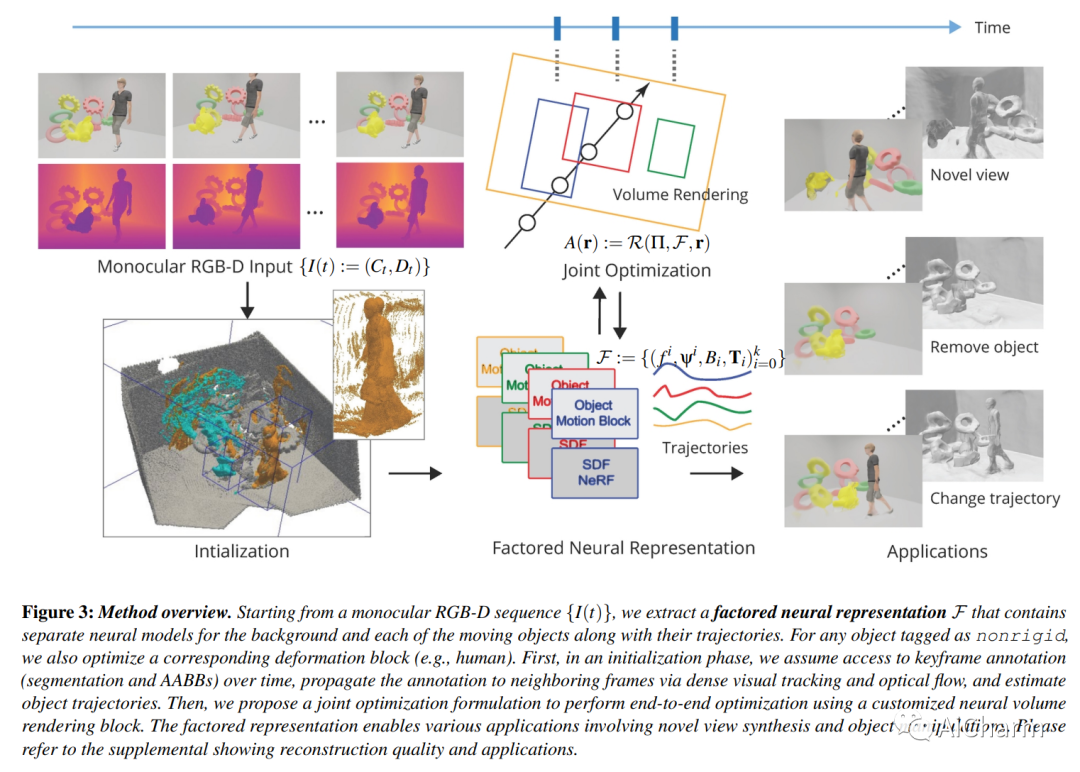
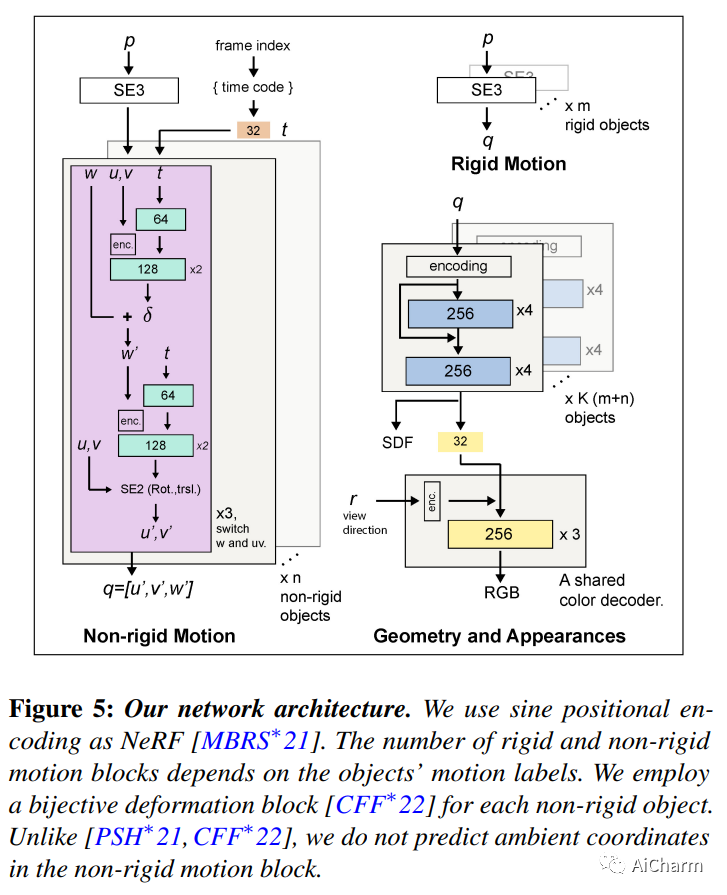
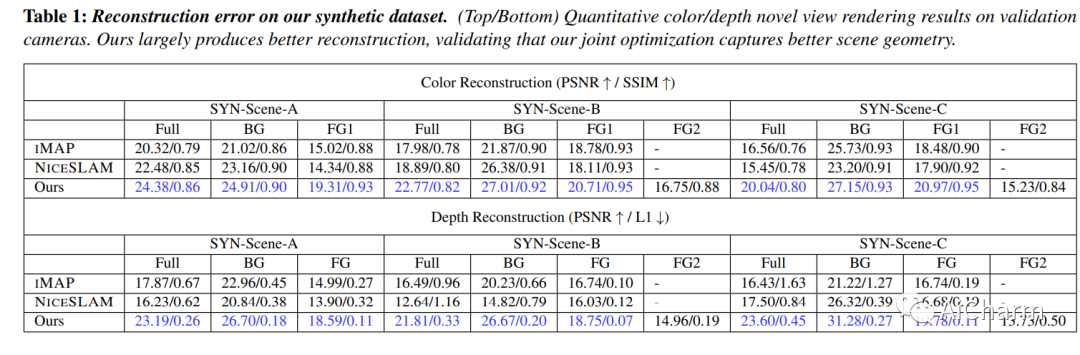
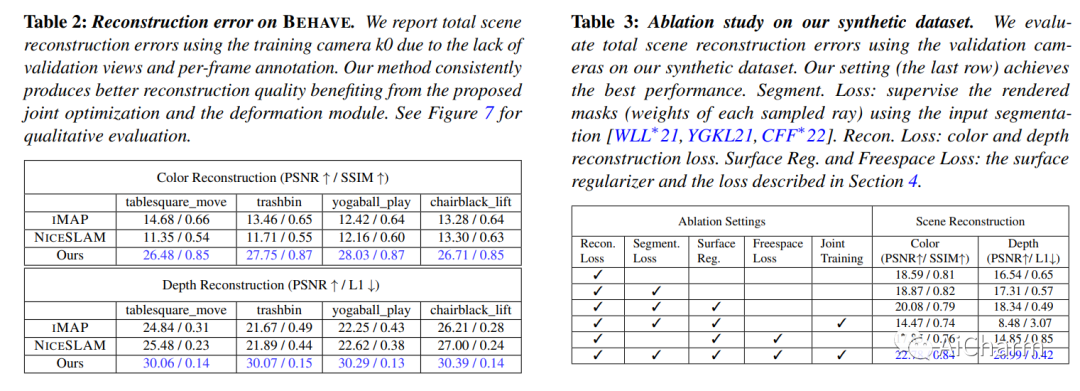
摘要:
场景理解的一个长期目标是获得可解释和可编辑的表示,这些表示可以直接从原始单目 RGB-D 视频构建,而不需要专门的硬件设置或先验。在存在多个移动和/或变形物体的情况下,该问题更具挑战性。传统方法通过混合简化、场景先验、预训练模板或已知变形模型来处理设置。神经表征的出现,尤其是神经隐式表征和辐射场,开启了端到端优化以共同捕捉几何、外观和物体运动的可能性。然而,当前的方法产生全局场景编码,假设多视图捕获在场景中有有限的或没有运动,并且不便于在新颖的视图合成之外进行简单的操作。在这项工作中,我们引入了一个分解的神经场景表示,它可以直接从单目 RGB-D 视频中学习,以生成对象级神经表示,并带有对象运动(例如,刚性轨迹)和/或变形(例如,非刚性运动)。我们针对合成数据和真实数据的一组神经方法评估我们的方法,以证明表示是有效的、可解释的和可编辑的(例如,改变对象轨迹)。
更多Ai资讯:公主号AiCharm