Contents
- Introduction
- Token Merging
- Experiments
- Image Experiments
- Design choices
- Model Sweep
- Comparison to Other Works
- Visualizations
- Video Experiments
- Audio Experiments
- References
Introduction
- 作者提出了一种 token 合并方法 Token Merging (ToMe),能够在不进行额外训练的情况下提高 ViT 推理速度,做到了真正的即插即用。通过使用轻量匹配算法逐步合并相似 tokens,ToMe 在运行速度上和 token pruning 方法一样快,并且还能使得模型精度更高 (prune 会损失掉被裁减 token 的信息,但 merge 只会在合并不相似 token 时损失信息)。当然,ToMe 也可以在训练时使用,从而加速训练过程,并进一步提高 ToMe 的推理精度
- 在不进行额外训练的情况下 (i.e., Off-the-shelf),ToME 能够将 ViT-L @ 512 和 ViT-H @ 518 on images 的吞吐量加速到 2 × 2\times 2×,将 ViT-L on video 的吞吐量加速到 2.2 × 2.2\times 2.2× 并且只产生 0.2%~0.3% 的精度损失。当在训练时使用 ToMe 时,Tome 能将 ViT-B on audio 加速到 2 × 2\times 2×,并且只有 0.4% mAP 的精度损失
Token Merging
- Strategy. 在每个 block 的 attention 层之后、MLP 层之前设置 ToMe 层用于 token 合并 (之所以设置在 block 中间而非每个 block 的开始处是因为可以利用 attention 中的信息帮助计算 token 间的相似度),每个 block 合并
r
r
r 次,即减少
r
r
r 个 tokens,假设总共有
L
L
L 个 blocks,则一共减少
r
L
rL
rL 个 tokens.
r
r
r 为超参,用于控制速度和精度的平衡。如下图 a 所示,狗的毛发对应的 token 最终被合并为了相同的 token

- Token Similarity. 衡量 token 间相似度最直接的方法就是计算 token embed 间的距离,但这并不是最优的,因为 ViT 的中间特征是 overparameterized 的,例如 ViT-B/16 的特征维度完全可以编码每个 patch 的 rgb pixel value ( 16 × 16 × 3 = 768 16\times16\times3=768 16×16×3=768),也就是说,ViT 的中间特征往往存在很多噪声,直接将其用于相似度计算并不能有效反映 token 间的相似度。为了解决上述问题,作者直接使用 self-attention 中 token 的 keys (K) 计算余弦相似度来估计 token 间的相似度 (the keys (K) already summarize the information contained in each token for use in dot product similarity)
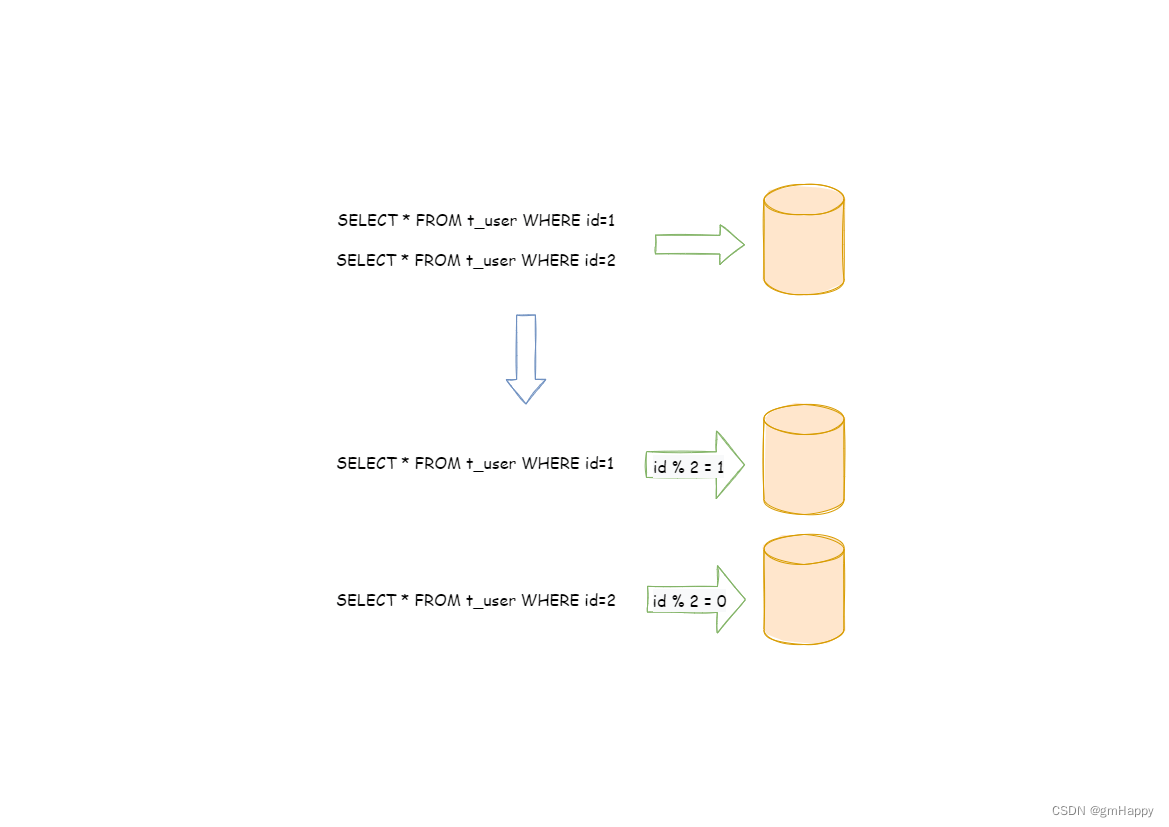
- Bipartite Soft Matching (二部图匹配). 作者提出了一种快速二部图匹配算法用于 token 合并:把所有 token 按照顺序交替分成两个集合,集合两两之间计算相似度,只保留集合
A
A
A 到集合
B
B
B 最相似的边,最终保留
r
r
r 条最相似的边,通过加权平均来合并相连的
r
r
r 对 tokens,权重为 token size
s
s
s,代表该 token 是多少个原始 patch token 合并后的结果 (number of patches the token represents).

def bipartite_soft_matching (k: torch . Tensor , r: int ) -> torch . Tensor :
""" Input is k from attention , size [batch , tokens , channels ]. """
k = k / k. norm ( dim =-1, keepdim = True )
a, b = k[... , ::2, :], k[... , 1::2, :]
scores = a @ b. transpose (-1, -2)
scores [... , 0, :] = - math . inf # don ’t merge cls token
node_max , node_idx = scores . max ( dim =-1)
edge_idx = node_max . argsort ( dim =-1, descending = True )[... , None ]
unm_idx = edge_idx [... , r:, :] # Unmerged Tokens
src_idx = edge_idx [... , :r, :] # Merged Tokens
dst_idx = node_idx [... , None ]. gather ( dim =-2, index = src_idx )
unm_idx = unm_idx . sort (dim =-2)[0] # Sort cls token back to idx 0
def merge (x: torch . Tensor ) -> torch . Tensor :
""" Input is of shape [batch , tokens , channels ]. """
src , dst = x[... , ::2, :], x[... , 1::2, :]
n, t1 , c = src . shape
unm = src. gather ( dim=-2, index = unm_idx . expand (n, t1 - r, c))
src = src. gather ( dim=-2, index = src_idx . expand (n, r, c))
dst = dst. scatter_add (-2, dst_idx . expand (n, r, c), src )
return torch . cat([unm , dst ], dim=-2)
return merge
- Tracking Token Size. 作者认为 token size 越大,该 token 在 softmax attention 里的重要性也应该越大,为此,作者提出了 proportional attention.
 softmax 里的
log
s
\log s
logs 相当于给 attention score 乘上一个系数
s
s
s,相当于是有
s
s
s 份相同的 keys
softmax 里的
log
s
\log s
logs 相当于给 attention score 乘上一个系数
s
s
s,相当于是有
s
s
s 份相同的 keys
Experiments
Image Experiments
Design choices
- Token Similarity. 下表对比了计算 token 间相似度的不同方法,
X
pre
\text{X}_{\text{pre}}
Xpre 为输入 block 的 token feature,
X
\text{X}
X 为 attention 后的 token feature,
K,Q,V
\text{K,Q,V}
K,Q,V 分别为计算相似度使用的自注意力层特征
 下表对比了计算相似度的不同距离函数
下表对比了计算相似度的不同距离函数
 为了模型更加高效,作者选择 average
K
\text{K}
K over the attention heads instead of concatenating them
为了模型更加高效,作者选择 average
K
\text{K}
K over the attention heads instead of concatenating them

- Algorithmic Choices. 下表对比了合并 token 的不同方法
 下表对比了将所有 token 划分为两个集合的不同方法
下表对比了将所有 token 划分为两个集合的不同方法

- Proportional Attention. 作者发现 proportional attention 对 supervised models (e.g., AugReg, SWAG, DeiT) 比较有用,但对 MAE 没用,这可能是因为 MAE 在训练时就会丢弃 tokens. 因此作者对除了 off-the-shelf MAE models 之外的模型使用了 proportional attention

- Comparing Matching Algorithms.

- Selecting a Merging Schedule. 作者将每层固定合并
r
r
r 次的策略和随机采样的 1500 种合并策略进行了比较,由下图可以发现固定合并
r
r
r 次的策略是接近最优的
 此外,作者还发现 linearly decreasing schedule 和最好的随机采样的合并策略相比效果较好,并且能将模型吞吐量提高到
∼
3
×
\sim3\times
∼3×,因此作者也定义了 “decreasing” schedule. 与 constant schedule 相比,它们最终合并的 token 数一样多,但 decreasing schedule 在模型早期合并的 token 数更多,因此吞吐量更大
此外,作者还发现 linearly decreasing schedule 和最好的随机采样的合并策略相比效果较好,并且能将模型吞吐量提高到
∼
3
×
\sim3\times
∼3×,因此作者也定义了 “decreasing” schedule. 与 constant schedule 相比,它们最终合并的 token 数一样多,但 decreasing schedule 在模型早期合并的 token 数更多,因此吞吐量更大

Model Sweep

- Re-evaluating. 在 Fig. 3c 中,作者测试了使用 ToMe 进行微调后的模型精度。值得一提的是,我们并不需要给每组 r r r 都重新训练一次模型,而是只需要训练一组 r r r 然后在其他 r r r 值上重新测试模型即可,这样做相比 off-the-shelf 也能提升模型精度 (For instance, the baseline ViT-L model we train in Fig. 3c gets 85.7% accuracy. If we re-evaluate our r = 5 r = 5 r=5 trained model with r = 0 r = 0 r=0, we obtain 85.8% accuracy.)
Comparison to Other Works


Visualizations

Video Experiments
- Results.

- Throughput.

- Clip Count.

- Visualization.

Audio Experiments
- Results.

References
- Bolya, Daniel, et al. “Token Merging: Your ViT But Faster.” (ICLR 2023).
- code: https://github.com/facebookresearch/tome



![[晕事]今天做了件晕事7](https://img-blog.csdnimg.cn/7d50591aee264c3dbad4bb335e5fb88e.png#pic_center)