目录
- 一、数据传递语义
- 1.1、至少一次
- 1.2、最多一次
- 1.3、精确一次
- 二、幂等性
- 2.1、幂等性原理
- 2.2、重复数据的判断标准
- 2.3、如何使用幂等性
- 三、生产者 事务
- 3.1、Kafka事务原理
- 3.2、Kafka事务注意事项
- 3.3、Kafka事务的5个API
- 3.3.1、初始化事务API
- 3.3.2、开启事务API
- 3.3.3、在事务内提交已经消费的偏移量API
- 3.3.4、提交事务API
- 3.3.5、放弃事务API
- 3.4、单个 Producer,使用事务保证消息的仅一次发送的示例代码
一、数据传递语义
1.1、至少一次
- 至少一次(At Least Once )的含义
生产者发送数据到kafka集群,kafka集群至少接收到一次数据。 - 至少一次的条件:
ACK级别设置为-1 + 分区副本大于等于2 + ISR里应答的最小副本数量大于等于2
1.2、最多一次
- 最多一次(At Most Once )的含义
生产者发送数据到kafka集群,kafka集群最多接收到一次数据。 - 最多一次的条件:
ACK级别设置为0
1.3、精确一次
- 精确一次( Exactly Once )的含义
对于一些非常重要的信息,比如和钱相关的数据,要求数据既不能重复也不丢失。 - 精确一次的条件:
幂等性 + 至少一次( ack=-1 + 分区副本数>=2 + ISR 最小副本数量>=2)
二、幂等性
2.1、幂等性原理
- 幂等性:指Producer不论向Broker发送多少次重复数据,Broker端都只会持久化一条,保证了不重复。
2.2、重复数据的判断标准
- 具有<PID, Partition, SeqNumber>相同主键的消息提交时,Broker只会持久化一条。其中PID是Kafka每次重启都会分配一个新的;Partition 表示分区号;Sequence Number是单调自增的。
- 所以幂等性只能保证的是在单分区单会话内不重复。
2.3、如何使用幂等性
- 开启参数 enable.idempotence 默认为 true,false关闭。
- 官网描述如下图:

三、生产者 事务
3.1、Kafka事务原理
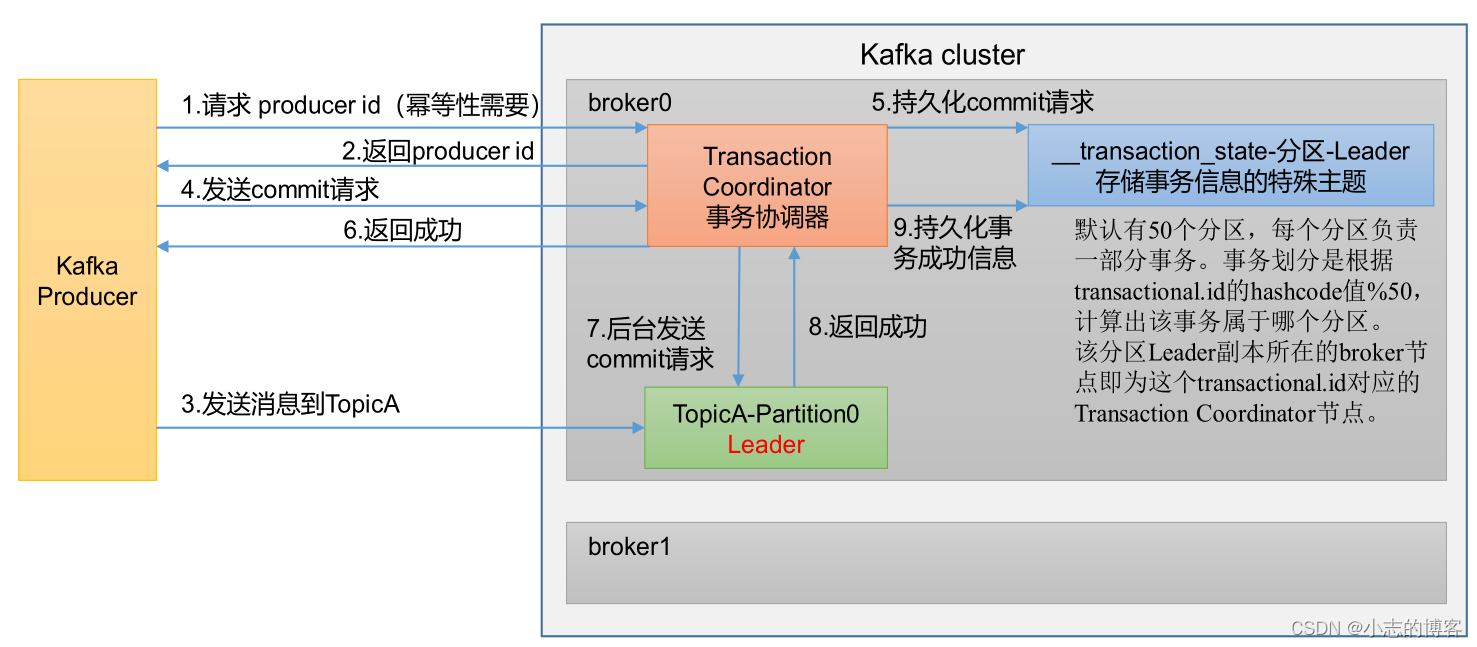
3.2、Kafka事务注意事项
- Producer 在使用事务功能前,必须先自定义一个唯一的 transactional.id。有了transactional.id,即使客户端挂掉了,它重启后也能继续处理未完成的事务
- 开启事务,必须开启幂等性 。
3.3、Kafka事务的5个API
3.3.1、初始化事务API
- 初始化事务

3.3.2、开启事务API
- 开启事务

3.3.3、在事务内提交已经消费的偏移量API
- 在事务内提交已经消费的偏移量(主要用于消费者)

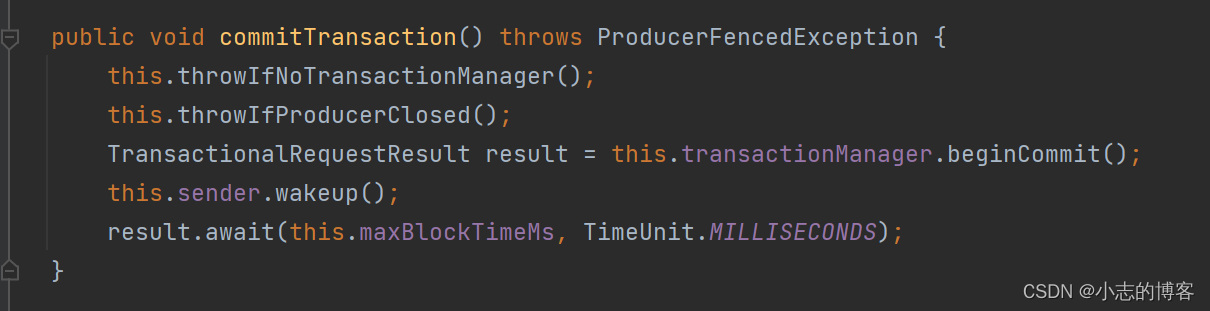
3.3.4、提交事务API
- 提交事务
3.3.5、放弃事务API
- 放弃事务(类似于回滚事务的操作)
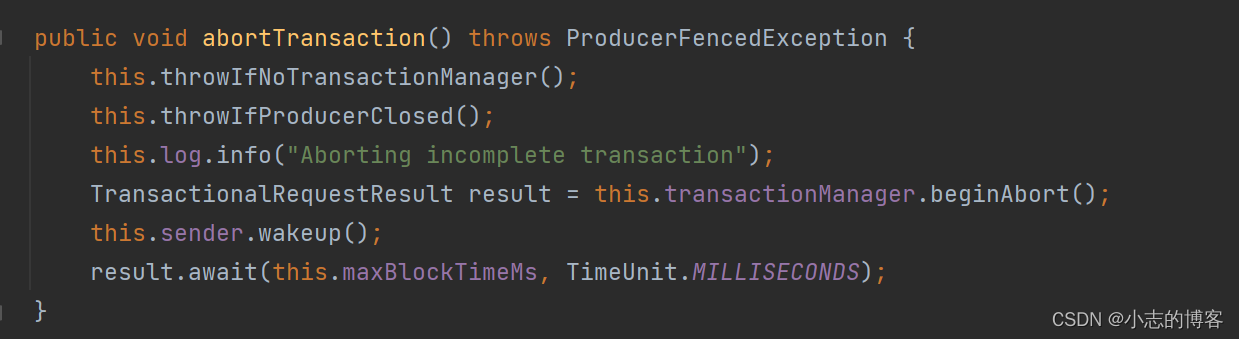
3.4、单个 Producer,使用事务保证消息的仅一次发送的示例代码
-
示例代码
package com.xz.kafka.producer; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.common.serialization.StringSerializer; import java.util.Properties; public class CustomProducerTranactions { public static void main(String[] args) { //1、创建 kafka 生产者的配置对象 Properties properties = new Properties(); //2、给 kafka 配置对象添加配置信息:bootstrap.servers properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092,hadoop103:9092"); //3、指定对应的key和value的序列化类型 key.serializer value.serializer properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); //指定事务id properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "tranactionalId_01"); //4、创建 kafka 生产者对象 KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties); //初始化事务 kafkaProducer.initTransactions(); //开启事务 kafkaProducer.beginTransaction(); try { //5、调用 send 方法,发送消息 for (int i = 0; i < 5; i++) { kafkaProducer.send(new ProducerRecord<>("news", "hello kafka" + i)); } //提交事务 kafkaProducer.commitTransaction(); } catch (Exception e) { //终止事务 kafkaProducer.abortTransaction(); } finally { //6、关闭资源 kafkaProducer.close(); } } } -
在kafka集群上开启 Kafka 消费者
[root@localhost kafka-3.0.0]# bin/kafka-console-consumer.sh --bootstrap-server 192.168.136.27:9092 --topic news -
在 IDEA 中执行代码,观察kafka集群控制台中是否接收到消息。



![[晕事]今天做了件晕事7](https://img-blog.csdnimg.cn/7d50591aee264c3dbad4bb335e5fb88e.png#pic_center)