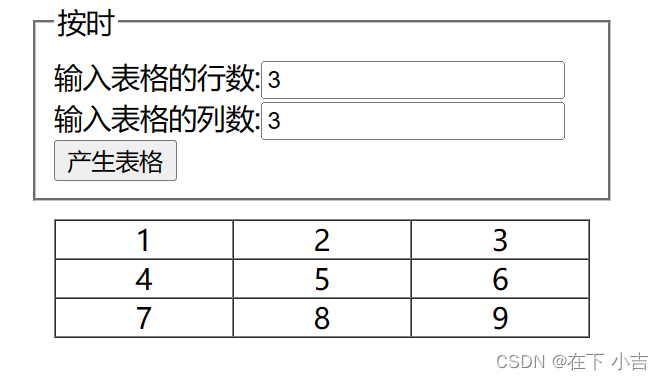
本章内容
- 文章概况
- 总体结构
- 重点结构
- self-attention distilling operation(自注意蒸馏操作)
- generative style decoder(生成式解码器)
- ProbSparse self-attention mechanism(概率稀疏自注意机制)
- 实验结果
- 主要实验结果
- 其他实验结果
- 总结
文章概况
《Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting》是2021年发表于AAAI的一篇论文。常规自注意机制和Transformer模型已达性能瓶颈,作者尝试寻找新的方法来提高Transformer模型的性能,使其在具备更高效计算、内存和架构能力的同时,又能拥有更优异的预测能力。基于此,该论文提出了一种新的时序预测思路和自注意力机制。
文章代码链接:
论文链接
代码链接
除此之外,在原先论文方法的基础上,作者更加丰富了实验内容,发表了一篇期刊论文(Artificial Intelligence)。
延伸论文链接
总体结构
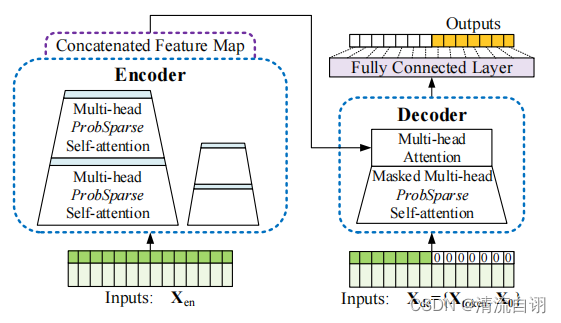
该论文的模型总体结构如上图所示,属于Encoder-Decoder结构,我们将两者分开看。
Encoder:
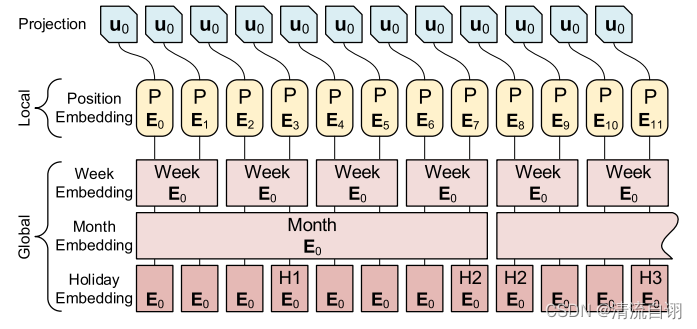
该部分输入是时序长度为seq_len的过去数据
X
e
n
X_{en}
Xen,首先进行的是编码操作(如上图所示),包含数值编码(蓝)、位置编码(黄)、时间编码(粉)。接着通过由若干个Encoder组成的Encoder Stack提取数据特征并合并所有Encoder提取到的特征图
X
f
m
X_{fm}
Xfm。
Decoder:
该部分输入一个组合值
X
d
e
X_{de}
Xde,包含
X
e
n
X_{en}
Xen的后一部分
X
t
o
k
e
n
X_{token}
Xtoken(其长度的选择没有固定说法,介于0到seq_len即可,可选择
X
e
n
X_{en}
Xen的后一半)和需要预测的长度为pred_len的时序数据
X
0
X_{0}
X0(因其属于预测未知值,因此数值部分使用0填充)。接着,将
X
f
m
X_{fm}
Xfm和
X
d
e
X_{de}
Xde输入Decoder后得到预测结果。
重点结构
self-attention distilling operation(自注意蒸馏操作)
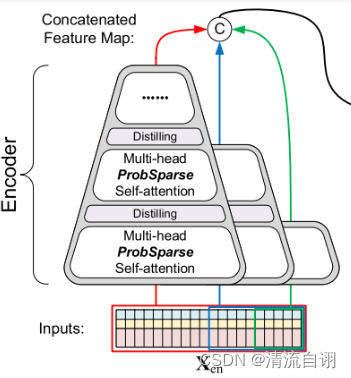
该操作本质上由若干个Encoder组成,目的是提取到稳定的长期特征。每个Encoder的网络深度逐渐递减,输入数据的长度也随之递减,最终将所有Encoder提取到的特征进行拼接。需要注意的是,为了使Encoder们有所区别,作者通过确定每个分支自注意力机制的重复次数逐渐递减每个分支的深度,同时,为了保证待合并数据的大小一致,每个分支只取前一个分支后一半的输入值作为输入。
generative style decoder(生成式解码器)
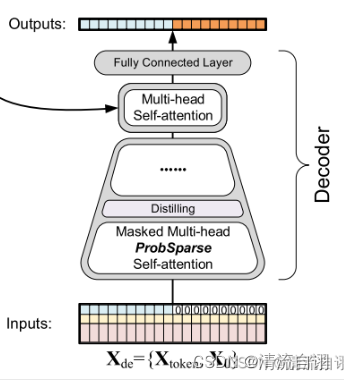
在过去的时序预测中,往往需要分别进行多步预测才能得到未来若干个时间点的预测结果。然而这种多预测方法,随着预测长度的不断增加,累积误差会越来越大,导致长期预测缺少了现实意义。本文作者提出了生成式解码器来获取序列输出,只需要一个推导过程,便可以获得所需目标长度的预测结果,有效地避免了多步预测中累积误差的扩散。
ProbSparse self-attention mechanism(概率稀疏自注意机制)
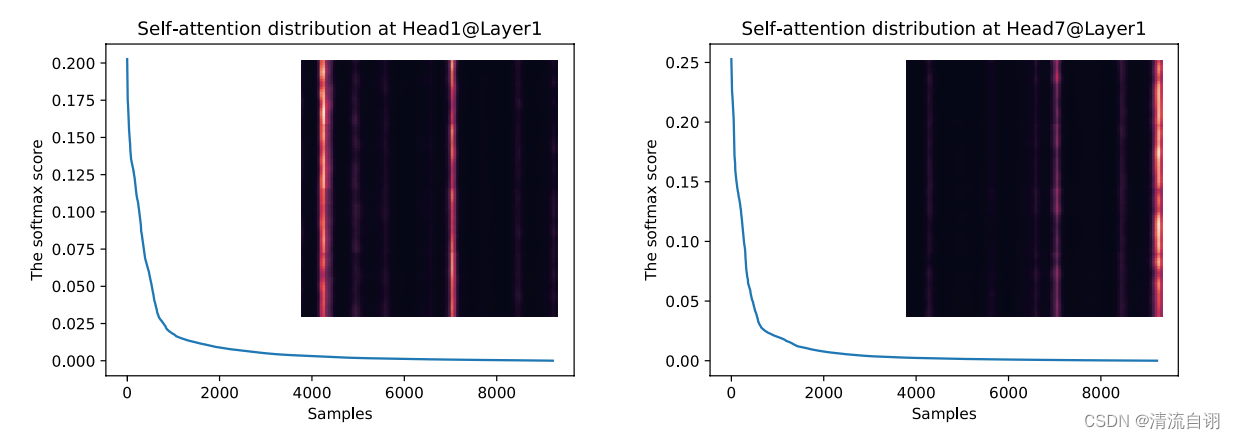
该方法的提出源于作者对自注意力机制特征图的思考。作者对第一层自注意机制的Head1和Head7进行可视化,发现特征图中仅有几道明亮条纹,同时两个头的得分少部分值较大,符合长尾数据的分布特征,如上图所示。于是得到结论:小部分点积对贡献了主要的关注,而其他的则可以忽略。根据这一特点,作者着重对高得分点积对进行关注,尝试在每次的自注意模块的运算中仅需要计算高得分的部分,从而有效减少模型的时间和空间成本。
传统自注意力机制:
z
=
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
V
z=softmax(\frac{QK^{T} }{\sqrt{d_{k} } } )V
z=softmax(dkQKT)V
ProbSparse:
1.在长尾分布中,高得分占比小,没必要全计算一遍,采用随机采样降低计算量:通过从
K
K
K中随机选择若干张量来达到对
Q
K
T
QK^{T}
QKT随机采样的目标;
2.KL散度计算分布差距,寻找突出:对于注意力得分
S
S
S,特征提取有效时,满足上图所示长尾分布的情况,特征图表现为少数明亮条纹,特征提取效果不佳时,注意力得分相近,特征图中也不存在鲜明对比的条纹,长尾分布变为均匀分布。因此可利用KL散度计算分布之间的差距,并选择分布差距最大的若干个注意力得分,并获得他们的索引
i
n
d
e
x
index
index;
3.对突出部分求值,大大降低计算量:根据
i
n
d
e
x
index
index寻找到
Q
Q
Q中对应的
Q
ˉ
\bar{Q}
Qˉ后,再进行注意力得分计算
S
=
Q
ˉ
K
T
d
k
S=\frac{\bar{Q}K^{T} }{\sqrt{d_{k} } }
S=dkQˉKT。对
V
V
V取均值并赋值给
z
z
z,取
V
V
V位于索引
i
n
d
e
x
index
index处的数值做运算
z
i
n
d
e
x
=
s
o
f
t
m
a
x
(
S
)
V
z_{index}=softmax(S)V
zindex=softmax(S)V,更新
z
z
z中对应索引位置上的值。
4.如此往复,直至训练迭代完毕。
实验结果
主要实验结果
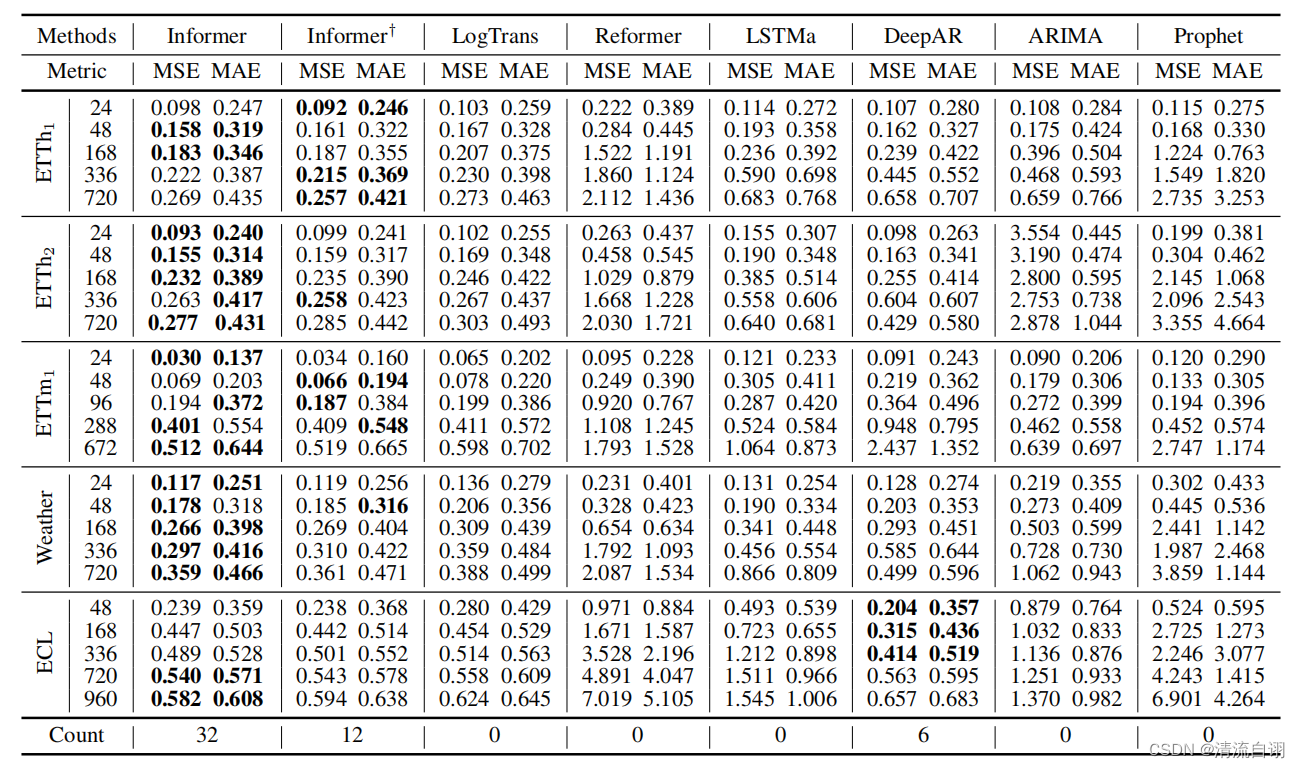
单变量长序列预测结果:
多变量长序列预测结果:
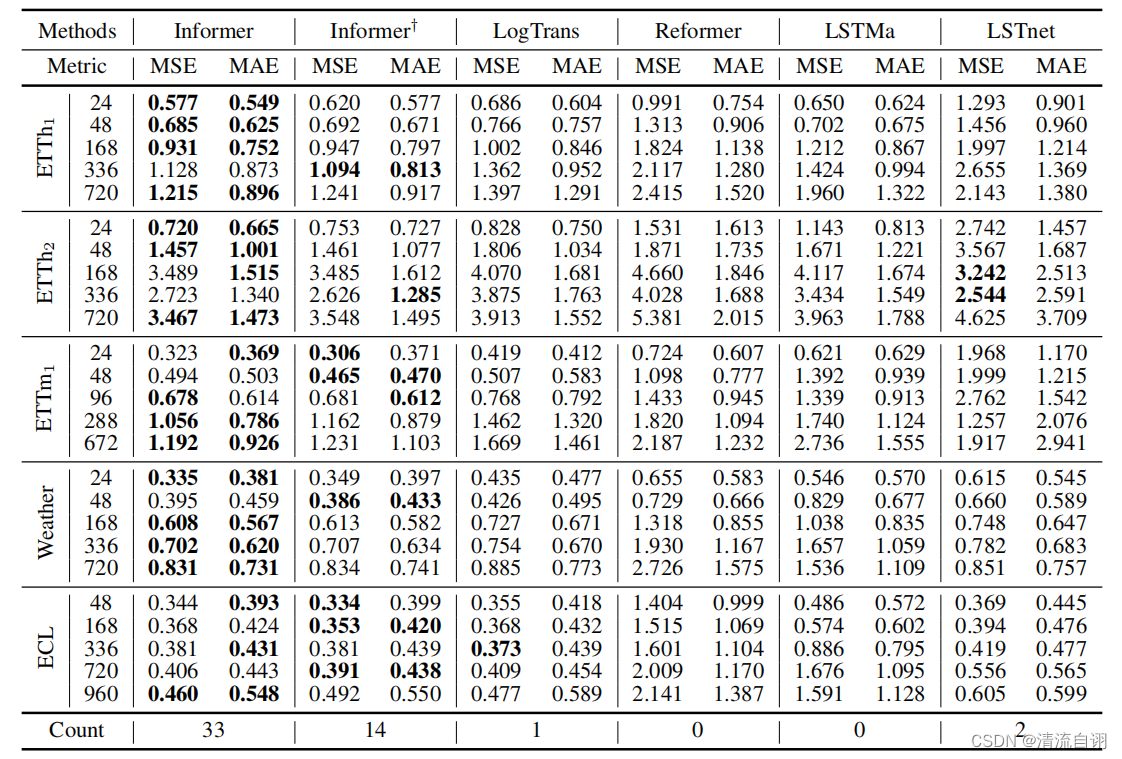
其中
I
n
f
o
r
m
e
r
+
Informer^{+}
Informer+使用的是典型的自注意力机制。
由上图优势项个数的对比结果可以看出,Informer具有明显的优势,在各种数据集均表现不错。
其他实验结果
该部分作者进行了不少对比:数据的时间粒度、参数的敏感性和模型结构的消融实验等等。此外作者还比较了几种方法的总运行时间、时间复杂度、空间复杂度和推理步数。总体而言,Informer表现出较为稳定且优异的预测性能。
总结
这本篇文章做了很多公式推导和求证,精妙的近似手段和精彩的公式过程使得作者改进后的自注意力机制效果和合理性并存。当然,编解码器同样在模型提升、效果提高上占据着不可磨灭的功劳。总体来说,就目前看来,没有什么缺点,效果还不错,确实厉害。