目录
1.线程
2.前台线程和后台线程
3.run和start的区别
4.线程的终止
5.线程等待
6.获取当前线程的引用
1.线程
创建线程需要继承Thread方法
调用start方法就会生成一个新的线程,调用run方法会在老的线程继续跑
main也是个线程,他是自动调用的.线程休息了先唤醒main和thread 是不确定的,宏观上线程调度是随机的也是同时的(抢占式执行)
这个随机性给我们多线程编程带来了许多麻烦
写法2:
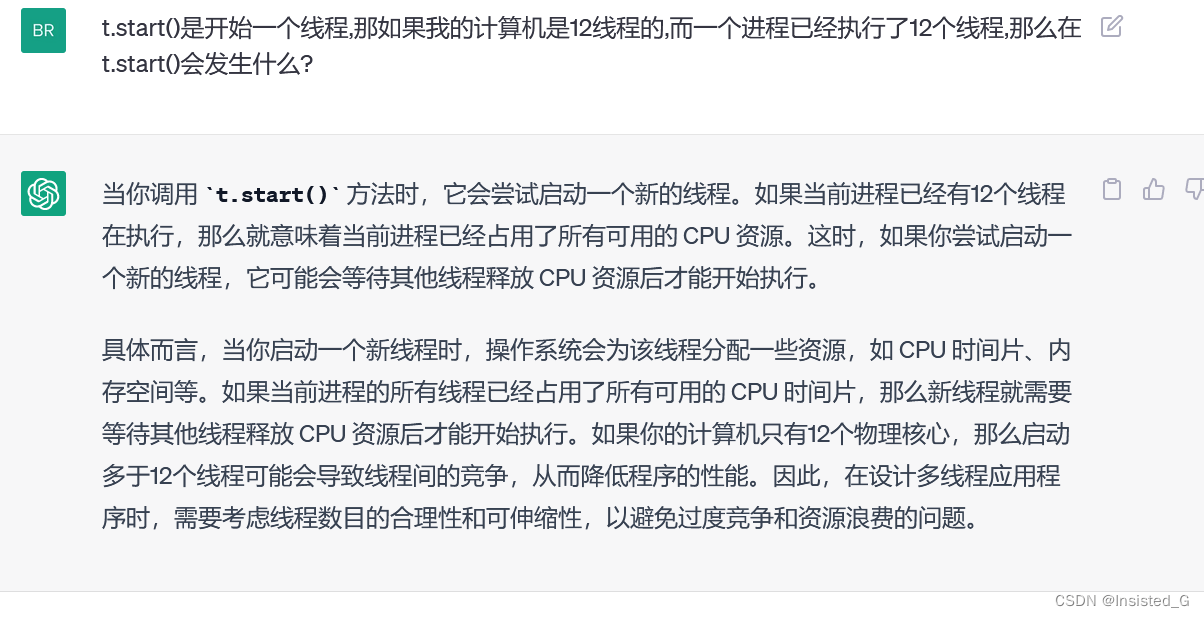
创建一个myRunnable类实现Runnable 接口,再创建Runnable 实例传给Thread实例
法3:匿名内部类创建线程
lambda表达式:就是匿名的函数,其中参数如果可以从上下文推断出来则可以省略类型.否则就别省略
2.前台线程和后台线程
前台线程:即使main函数的线程结束,已经执行的线程不结束,直到运行完毕
后台线程:main函数的线程退出, 正在执行的后台进程也强制退出
3.run和start的区别
run是普通的并行执行,并不创建线程. run执行完了才执行后面的代码
start是创建一个新的线程,创建完这个线程后,线程内的start开始执行,同时执行后面的代码,与后面的代码抢夺资源
4.线程的终止
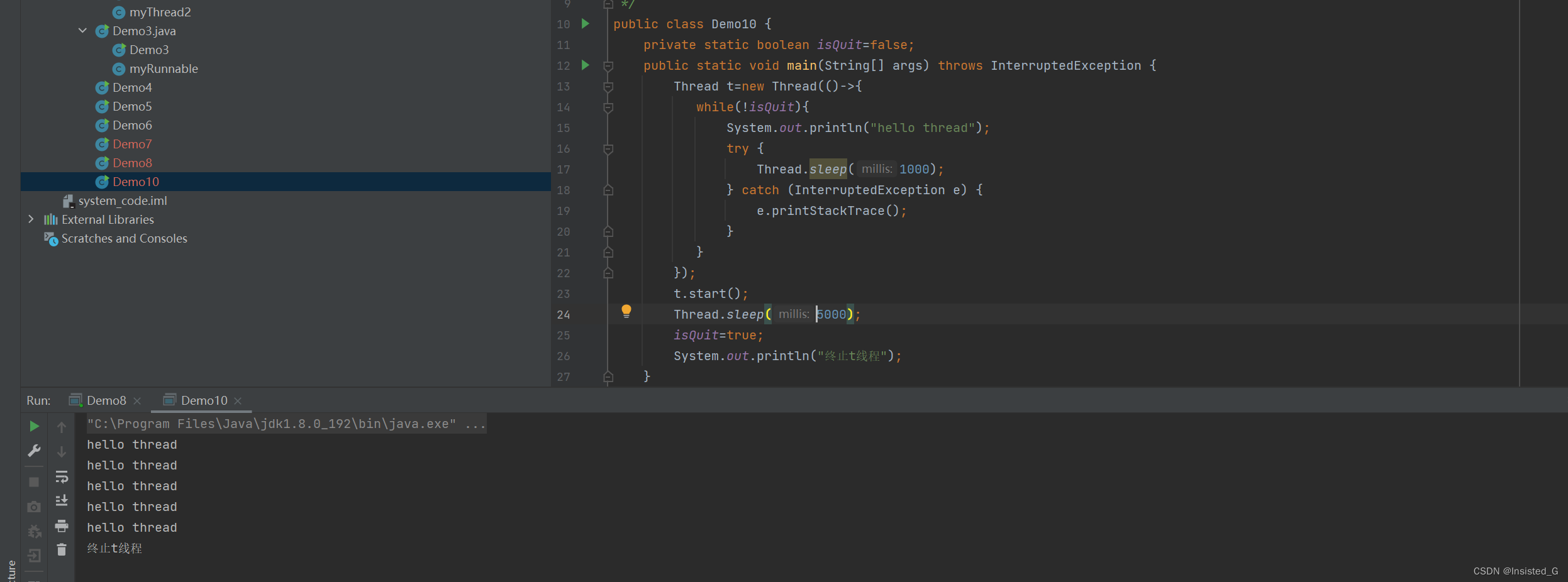
1.设置一个变量来设置线程是否退出
这个isQuit也可以在main函数中去修改,因为多线程共用一块虚拟地址空间,因此Main线程和t线程判定的isQuit是同一个
2.实用Thread中内置的标志位进行判断
两种标志位的区别是:第一个共用一些标志位,容易造成误会,你修改了,我认为这是我修改的
第二种是每个实例有一个标志位,很好,一般用这个方法
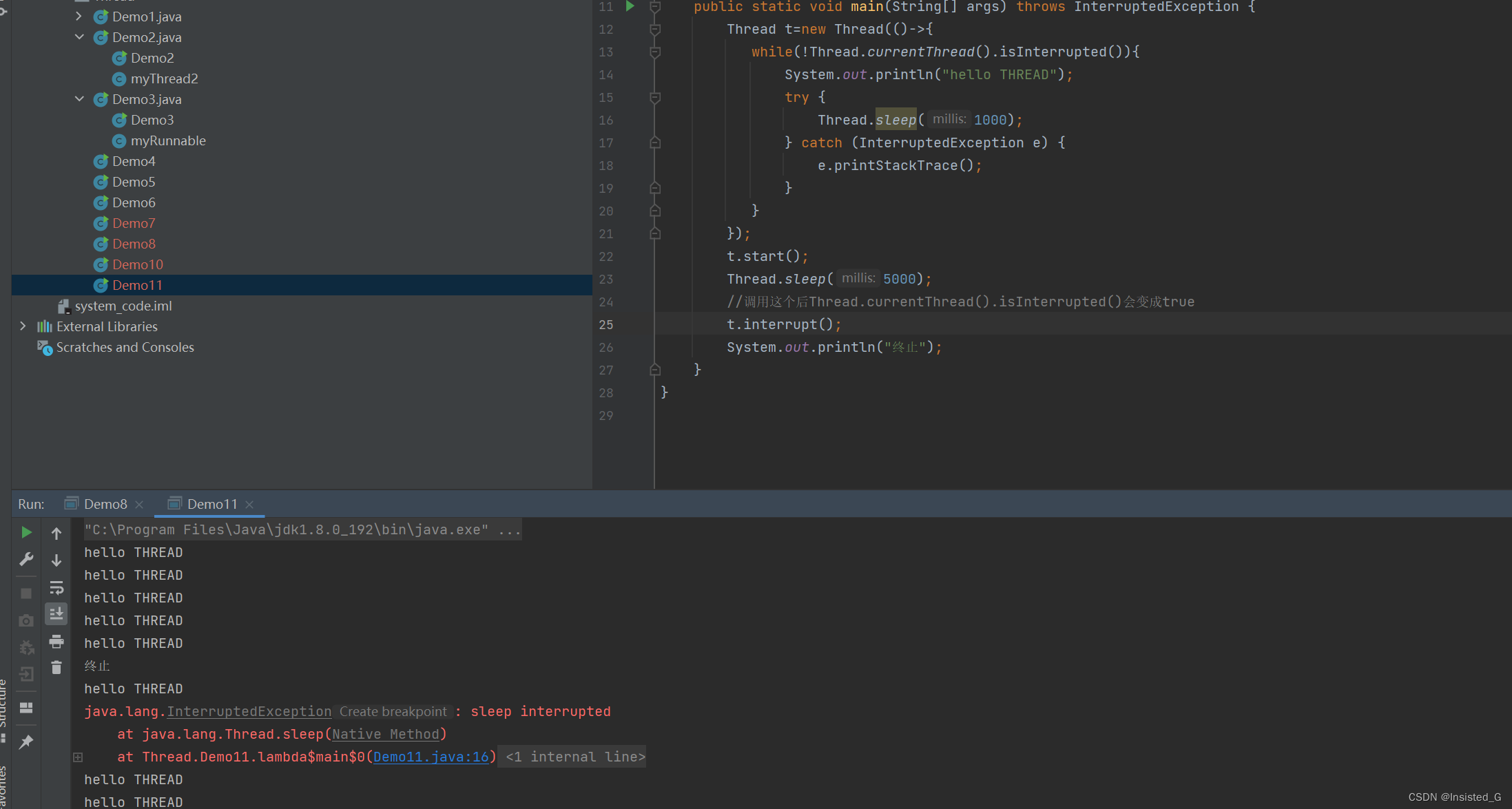
调用t.interrupt() 会产生两种结果,如果t线程处于就绪状态,那么就会正常中断线程
如果t线程处于阻塞状态,那么就会抛出 interruptException

5.线程等待
线程等待是控制线程执行顺序的其中之一的方式
线程等待主要是控制线程结束的先后顺序,用join
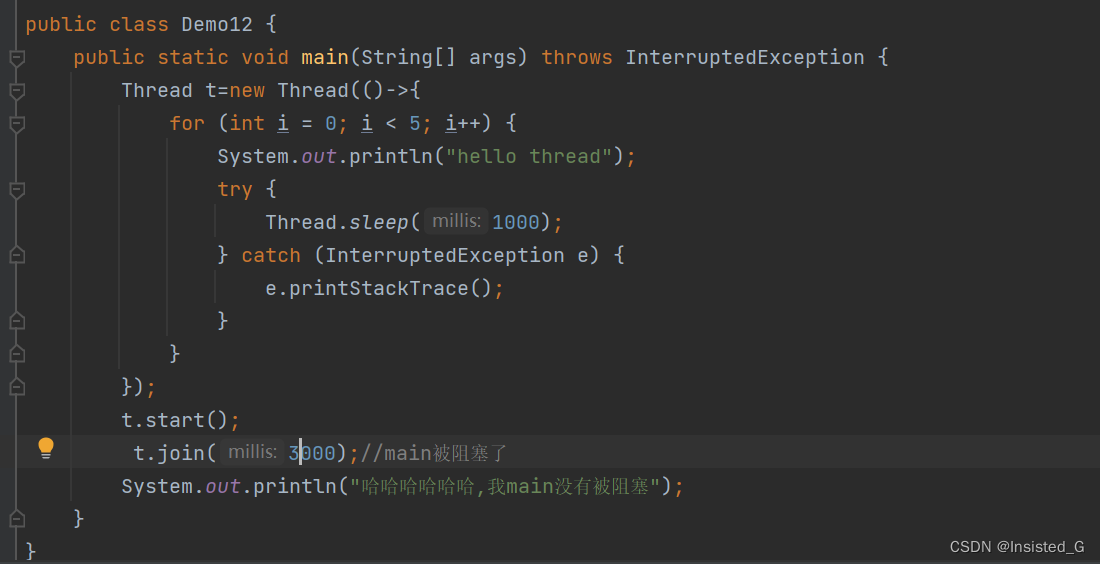
调用join的时候,哪个线程调用join,哪个线程就会阻塞等待,直到对应的线程执行完毕为止(对应线程的run执行完)
调用t.join()之后(由于join是在main线程中调用的,所以说) main线程陷入阻塞,直到t线程执行完毕
阻塞状态:暂时无法在cpu上执行
通过线程等待,我们让t先结束,main后结束


join默认情况下是死等,如果一个线程出问题了可能就会一直等
join的另外一个版本,可以指定最长等多少时间
就是在join里面加个数字
表示最多等待3s
6.获取当前线程的引用
Thread.currentThread()就能获取当前线程的引用