引言
kafka在3.X版本后内置了kraft用来替代zookeeper管理集群,但是在升级的过程中发现,许多升级的文档都是只有新部署安装kraft版本,而没有涉及到数据迁移相关的资料,这样如果直接变更的话,会导致kakfa中的数据全部丢失,这在客户的生产环境中是不可接受的,所以一直在寻求数据迁移的方案,经过查阅大量资料后,基于官方的方案(略了太多步骤),终于折腾出了迁移的方案。
准备工作
- 数据迁移前必须先将kafka升级到3.4以上版本,即 kakfa 3.4 + zookeeper集群的方式。(升级较为简单,参照kafka升级)
- 目前的迁移方式仅支持controller和broker分开部署,也即如果原来是3台kafka机器,迁移后可能会变成3台controller和3台broker。(建议controller使用3台新机器,broker可以使用原有的这个已升级到3.4版本的kafka)
- 数据迁移前建议记录一下目前的数据和消费组的offset位置,用于迁移后的验证,看是否迁移成功
- 机器说明
192.168.0.5
192.168.0.6
192.168.0.7
1. 上面三台为kafka 3.4 + zookeeper集群机器,后续说的“旧的kafka”均指这3台。
2. 迁移后的broker也同样在这三台上面,只是旧的kafka启动时指定的配置文件是config/server.properties,新的broker启动时指定的配置文件是config/kraft/broker.properties
192.168.0.110
192.168.0.111
192.168.0.112
这三台为新的controller集群机器,后续说的"新的kafka"均指这3台。
迁移步骤
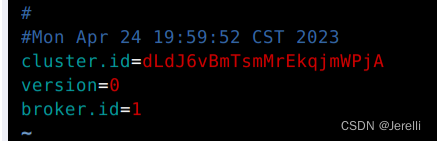
1. 获取旧有的kafka的cluster id
可以在旧的kafka的bin目录下执行下述语句查看
./bin/zookeeper-shell.sh localhost:2181 get /cluster/id
或者也可以在config/server.properties中配置的log.dirs目录中查看meta.properties文件。
2. 打开新的kafka机器controller的trace日志,用于后续观察迁移是否完成
cd /opt/kafka/config (改为自己的kafka目录)
vim log4j.properties
添加如下配置保存后退出,注意将三台controller机器都添加上。
log4j.logger.org.apache.kafka.metadata.migration=TRACE

3. 编辑新的kafka的controller.properties文件
目录为 kafka/config/kraft/controller.properties
主要配置说明:
node.id 必须设置为与之前旧的kafka集群中的broker.id不一样(旧的broker.id可以在旧机器的config/server.properties查看)
controller.quorum.voters 需要配置所有的controller节点,格式为nodeid@ip:端口。如目前我所配置的node.id分别为3000 4000 5000
listeners 修改为自己想要监听的端口,默认为9093
log.dirs controller数据存放的目录
zookeeper.metadata.migration.enable 数据迁移的开关
zookeeper.connect 设置zookeeper的集群地址
例子:
process.roles=controller
node.id=3000
controller.quorum.voters=3000@192.168.0.110:9093,4000@192.168.0.111:9093,5000@192.168.0.112:9093
listeners=CONTROLLER://:9093
controller.listener.names=CONTROLLER
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/opt/kafka/krfdata
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.metadata.migration.enable =true
zookeeper.connect =192.168.0.5:2181,192.168.0.6:2181,192.168.0.7:2181
注意:
三台controller机器的node.id必须不一样,比如(3000、4000、5000)等,将三台controller机器全部修改完成后保存退出
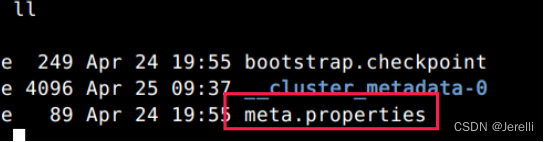
4. 格式化controller集群的id
进入到controller机器的kafka bin目录下面,执行如下语句格式化
./bin/kafka-storage.sh format -t 第一步获取的cluster.id -c ./config/kraft/controller.properties
格式化完成后,会在controller.propertie中配置的log.dirs目录下,生成meta.properties文件
5. 三台全部执行完成后,依次启动三台机器的controller,将controller集群启动
附一个启动命令,注意必须指定使用controller.properties文件启动
nohup ./bin/kafka-server-start.sh ./config/kraft/controller.properties &
启动完成后记得看一下日志和kafka进程,确保启动成功
6. 修改旧的kafka集群的server.properties配置,打开迁移模式
在配置文件中添加如下配置:
注意controller.quorum.voters修改为controller集群的ID和IP地址,ID和IP地址必须与controller集群的匹配上
inter.broker.protocol.version=3.4
log.message.format.version=3.4
listener.security.protocol.map=PLAINTEXT:PLAINTEXT,CONTROLLER:PLAINTEXT
zookeeper.metadata.migration.enable=true
controller.quorum.voters=3000@192.168.0.110:9093,4000@192.168.0.111:9093,5000@192.168.0.112:9093
controller.listener.names=CONTROLLER
7. 将所有的三台旧的kafka的server.properties文件修改完成后,保存退出,重启三台旧的kakfa
8. 重启三台旧的kafka后,就会自动开始数据迁移,在controller机器的server.log日志中,会出现TRACE级别的日志,数据迁移完成后会打印如下语句。
Completed migration of metadata from Zookeeper to KRaft
可以使用grep "Completed migration" server.log过滤日志查看

注意: 有多台controller机器的集群时,该日志可能只在某一台的controller机器的server.log中出现,记得都检查一下
9. 数据迁移完成后,修改旧的kafka的config/kraft目录下的broker.properties文件,可以直接复制下面的内容,修改对应的参数即可
配置说明:
node.id 必须设置为与旧的kafka的broker.id一致,如果旧的broker.id分别为1、2、3,新的也必须分别为1、2、3
controller.quorum.voters 设置为controller集群的ID和IP地址
log.dirs 必须与旧的kafka的log.dirs保持一致
advertised.listeners 修改为本机的IP
补充比较容易混淆的点,新的controller的node.id必须与旧的kafka的broker.id不一样,新的broker的node.id必须与旧的kafka的broker.id一致
process.roles=broker
node.id=1
controller.quorum.voters=3000@192.168.0.110:9093,4000@192.168.0.111:9093,5000@192.168.0.112:9093
listeners=PLAINTEXT://:9092
inter.broker.listener.name=PLAINTEXT
advertised.listeners=PLAINTEXT://192.168.0.5:9092
controller.listener.names=CONTROLLER
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/opt/kafka/kfdata
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
10. 修改完成后停掉旧的kafka和zookeeper,然后使用新的配置启动kafka,将所有的kafka启动后,就是开始使用kraft来管理集群。
附上一个启动命令
nohup ./bin/kafka-server-start.sh ./config/kraft/broker.properties &
11. 修改controller集群的配置,把迁移的开关关掉,退出迁移模式
注释掉最后两行
process.roles=controller
node.id=3000
controller.quorum.voters=3000@192.168.0.110:9093,4000@192.168.0.111:9093,5000@192.168.0.112:9093
listeners=CONTROLLER://:9093
controller.listener.names=CONTROLLER
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/opt/kafka/krfdata
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
#zookeeper.metadata.migration.enable =true
#zookeeper.connect =192.168.0.5:2181,192.168.0.6:2181,192.168.0.7:2181
12. 注释后依次重启controller机器,整体的迁移流程全部完成
13. 迁移完成后可以在broker机器(即旧的kafka机器)的bin目录下执行语句,验证数据以及consumer的offset位置是否还存在。
附上一条语句
./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group 消费者组名称 -describe
最后附上官方的方案:
kraft_zk_migration