论文代码:https://github.com/Uason-Chen/CTR-GCN
ctrgcn.py
文件路径:CTR-GCN/model/ctrgcn.py
import math
import pdb
import numpy as np
import torch
import torch.nn as nn
from torch.autograd import Variable
def import_class(name):
components = name.split('.')
mod = __import__(components[0])
for comp in components[1:]:
mod = getattr(mod, comp)
return mod
def conv_branch_init(conv, branches):
weight = conv.weight
n = weight.size(0)
k1 = weight.size(1)
k2 = weight.size(2)
nn.init.normal_(weight, 0, math.sqrt(2. / (n * k1 * k2 * branches)))
nn.init.constant_(conv.bias, 0)
def conv_init(conv):
if conv.weight is not None:
nn.init.kaiming_normal_(conv.weight, mode='fan_out')
if conv.bias is not None:
nn.init.constant_(conv.bias, 0)
def bn_init(bn, scale):
nn.init.constant_(bn.weight, scale)
nn.init.constant_(bn.bias, 0)
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
if hasattr(m, 'weight'):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
if hasattr(m, 'bias') and m.bias is not None and isinstance(m.bias, torch.Tensor):
nn.init.constant_(m.bias, 0)
elif classname.find('BatchNorm') != -1:
if hasattr(m, 'weight') and m.weight is not None:
m.weight.data.normal_(1.0, 0.02)
if hasattr(m, 'bias') and m.bias is not None:
m.bias.data.fill_(0)
class TemporalConv(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, dilation=1):
super(TemporalConv, self).__init__()
pad = (kernel_size + (kernel_size-1) * (dilation-1) - 1) // 2
self.conv = nn.Conv2d(
in_channels,
out_channels,
kernel_size=(kernel_size, 1),
padding=(pad, 0),
stride=(stride, 1),
dilation=(dilation, 1))
self.bn = nn.BatchNorm2d(out_channels)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
return x
class MultiScale_TemporalConv(nn.Module):
def __init__(self,
in_channels,
out_channels,
kernel_size=3,
stride=1,
dilations=[1,2,3,4],
residual=True,
residual_kernel_size=1):
super().__init__()
assert out_channels % (len(dilations) + 2) == 0, '# out channels should be multiples of # branches'
# Multiple branches of temporal convolution
self.num_branches = len(dilations) + 2
branch_channels = out_channels // self.num_branches
if type(kernel_size) == list:
assert len(kernel_size) == len(dilations)
else:
kernel_size = [kernel_size]*len(dilations)
# Temporal Convolution branches
self.branches = nn.ModuleList([
nn.Sequential(
nn.Conv2d(
in_channels,
branch_channels,
kernel_size=1,
padding=0),
nn.BatchNorm2d(branch_channels),
nn.ReLU(inplace=True),
TemporalConv(
branch_channels,
branch_channels,
kernel_size=ks,
stride=stride,
dilation=dilation),
)
for ks, dilation in zip(kernel_size, dilations)
])
# Additional Max & 1x1 branch
self.branches.append(nn.Sequential(
nn.Conv2d(in_channels, branch_channels, kernel_size=1, padding=0),
nn.BatchNorm2d(branch_channels),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=(3,1), stride=(stride,1), padding=(1,0)),
nn.BatchNorm2d(branch_channels) # 为什么还要加bn
))
self.branches.append(nn.Sequential(
nn.Conv2d(in_channels, branch_channels, kernel_size=1, padding=0, stride=(stride,1)),
nn.BatchNorm2d(branch_channels)
))
# Residual connection
if not residual:
self.residual = lambda x: 0
elif (in_channels == out_channels) and (stride == 1):
self.residual = lambda x: x
else:
self.residual = TemporalConv(in_channels, out_channels, kernel_size=residual_kernel_size, stride=stride)
# initialize
self.apply(weights_init)
def forward(self, x):
# Input dim: (N,C,T,V)
res = self.residual(x)
branch_outs = []
for tempconv in self.branches:
out = tempconv(x)
branch_outs.append(out)
out = torch.cat(branch_outs, dim=1)
out += res
return out
class CTRGC(nn.Module):
def __init__(self, in_channels, out_channels, rel_reduction=8, mid_reduction=1):
super(CTRGC, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
if in_channels == 3 or in_channels == 9:
self.rel_channels = 8
self.mid_channels = 16
else:
self.rel_channels = in_channels // rel_reduction
self.mid_channels = in_channels // mid_reduction
self.conv1 = nn.Conv2d(self.in_channels, self.rel_channels, kernel_size=1)
self.conv2 = nn.Conv2d(self.in_channels, self.rel_channels, kernel_size=1)
self.conv3 = nn.Conv2d(self.in_channels, self.out_channels, kernel_size=1)
self.conv4 = nn.Conv2d(self.rel_channels, self.out_channels, kernel_size=1)
self.tanh = nn.Tanh()
for m in self.modules():
if isinstance(m, nn.Conv2d):
conv_init(m)
elif isinstance(m, nn.BatchNorm2d):
bn_init(m, 1)
def forward(self, x, A=None, alpha=1):
x1, x2, x3 = self.conv1(x).mean(-2), self.conv2(x).mean(-2), self.conv3(x)
x1 = self.tanh(x1.unsqueeze(-1) - x2.unsqueeze(-2))
x1 = self.conv4(x1) * alpha + (A.unsqueeze(0).unsqueeze(0) if A is not None else 0) # N,C,V,V
x1 = torch.einsum('ncuv,nctv->nctu', x1, x3)
return x1
class unit_tcn(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=9, stride=1):
super(unit_tcn, self).__init__()
pad = int((kernel_size - 1) / 2)
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=(kernel_size, 1), padding=(pad, 0),
stride=(stride, 1))
self.bn = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
conv_init(self.conv)
bn_init(self.bn, 1)
def forward(self, x):
x = self.bn(self.conv(x))
return x
class unit_gcn(nn.Module):
def __init__(self, in_channels, out_channels, A, coff_embedding=4, adaptive=True, residual=True):
super(unit_gcn, self).__init__()
inter_channels = out_channels // coff_embedding
self.inter_c = inter_channels
self.out_c = out_channels
self.in_c = in_channels
self.adaptive = adaptive
self.num_subset = A.shape[0]
self.convs = nn.ModuleList()
for i in range(self.num_subset):
self.convs.append(CTRGC(in_channels, out_channels))
if residual:
if in_channels != out_channels:
self.down = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1),
nn.BatchNorm2d(out_channels)
)
else:
self.down = lambda x: x
else:
self.down = lambda x: 0
if self.adaptive:
self.PA = nn.Parameter(torch.from_numpy(A.astype(np.float32)))
else:
self.A = Variable(torch.from_numpy(A.astype(np.float32)), requires_grad=False)
self.alpha = nn.Parameter(torch.zeros(1))
self.bn = nn.BatchNorm2d(out_channels)
self.soft = nn.Softmax(-2)
self.relu = nn.ReLU(inplace=True)
for m in self.modules():
if isinstance(m, nn.Conv2d):
conv_init(m)
elif isinstance(m, nn.BatchNorm2d):
bn_init(m, 1)
bn_init(self.bn, 1e-6)
def forward(self, x):
y = None
if self.adaptive:
A = self.PA
else:
A = self.A.cuda(x.get_device())
for i in range(self.num_subset):
z = self.convs[i](x, A[i], self.alpha)
y = z + y if y is not None else z
y = self.bn(y)
y += self.down(x)
y = self.relu(y)
return y
class TCN_GCN_unit(nn.Module):
def __init__(self, in_channels, out_channels, A, stride=1, residual=True, adaptive=True, kernel_size=5, dilations=[1,2]):
super(TCN_GCN_unit, self).__init__()
self.gcn1 = unit_gcn(in_channels, out_channels, A, adaptive=adaptive)
self.tcn1 = MultiScale_TemporalConv(out_channels, out_channels, kernel_size=kernel_size, stride=stride, dilations=dilations,
residual=False)
self.relu = nn.ReLU(inplace=True)
if not residual:
self.residual = lambda x: 0
elif (in_channels == out_channels) and (stride == 1):
self.residual = lambda x: x
else:
self.residual = unit_tcn(in_channels, out_channels, kernel_size=1, stride=stride)
def forward(self, x):
y = self.relu(self.tcn1(self.gcn1(x)) + self.residual(x))
return y
class Model(nn.Module):
def __init__(self, num_class=60, num_point=25, num_person=2, graph=None, graph_args=dict(), in_channels=3,
drop_out=0, adaptive=True):
super(Model, self).__init__()
if graph is None:
raise ValueError()
else:
Graph = import_class(graph)
self.graph = Graph(**graph_args)
A = self.graph.A # 3,25,25
self.num_class = num_class
self.num_point = num_point
self.data_bn = nn.BatchNorm1d(num_person * in_channels * num_point)
base_channel = 64
self.l1 = TCN_GCN_unit(in_channels, base_channel, A, residual=False, adaptive=adaptive)
self.l2 = TCN_GCN_unit(base_channel, base_channel, A, adaptive=adaptive)
self.l3 = TCN_GCN_unit(base_channel, base_channel, A, adaptive=adaptive)
self.l4 = TCN_GCN_unit(base_channel, base_channel, A, adaptive=adaptive)
self.l5 = TCN_GCN_unit(base_channel, base_channel*2, A, stride=2, adaptive=adaptive)
self.l6 = TCN_GCN_unit(base_channel*2, base_channel*2, A, adaptive=adaptive)
self.l7 = TCN_GCN_unit(base_channel*2, base_channel*2, A, adaptive=adaptive)
self.l8 = TCN_GCN_unit(base_channel*2, base_channel*4, A, stride=2, adaptive=adaptive)
self.l9 = TCN_GCN_unit(base_channel*4, base_channel*4, A, adaptive=adaptive)
self.l10 = TCN_GCN_unit(base_channel*4, base_channel*4, A, adaptive=adaptive)
self.fc = nn.Linear(base_channel*4, num_class)
nn.init.normal_(self.fc.weight, 0, math.sqrt(2. / num_class))
bn_init(self.data_bn, 1)
if drop_out:
self.drop_out = nn.Dropout(drop_out)
else:
self.drop_out = lambda x: x
def forward(self, x):
if len(x.shape) == 3:
N, T, VC = x.shape
x = x.view(N, T, self.num_point, -1).permute(0, 3, 1, 2).contiguous().unsqueeze(-1)
N, C, T, V, M = x.size()
x = x.permute(0, 4, 3, 1, 2).contiguous().view(N, M * V * C, T)
x = self.data_bn(x)
x = x.view(N, M, V, C, T).permute(0, 1, 3, 4, 2).contiguous().view(N * M, C, T, V)
x = self.l1(x)
x = self.l2(x)
x = self.l3(x)
x = self.l4(x)
x = self.l5(x)
x = self.l6(x)
x = self.l7(x)
x = self.l8(x)
x = self.l9(x)
x = self.l10(x)
# N*M,C,T,V
c_new = x.size(1)
x = x.view(N, M, c_new, -1)
x = x.mean(3).mean(1)
x = self.drop_out(x)
return self.fc(x)
ctrgcn.py 分段理解
其中,import_class,conv_branch_init,conv_init,bn_init 在 2s-AGCN 代码理解 中已经说过,本篇略过。
weights_init
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
if hasattr(m, 'weight'):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
if hasattr(m, 'bias') and m.bias is not None and isinstance(m.bias, torch.Tensor):
nn.init.constant_(m.bias, 0)
elif classname.find('BatchNorm') != -1:
if hasattr(m, 'weight') and m.weight is not None:
m.weight.data.normal_(1.0, 0.02)
if hasattr(m, 'bias') and m.bias is not None:
m.bias.data.fill_(0)
这段代码用于初始化神经网络中的卷积层和批量归一化层的权重和偏置。
函数的逻辑如下:
-
首先,获取 m 的类名,存储在 classname 变量中。
-
如果 classname 中包含’Conv’,说明 m 是一个卷积层,那么:
-
如果 m 有 weight 属性,说明它有可学习的权重矩阵,那么使用
nn.init.kaiming_normal_函数对其进行初始化,这是一种基于 He 初始化的方法,可以保持信号的方差不变,避免梯度消失或爆炸。mode 参数设置为’fan_out’,表示根据输出通道数来计算方差。 -
如果 m 有 bias 属性,并且不为空,并且是一个 torch.Tensor 类型,说明它有可学习的偏置向量,那么使用
nn.init.constant_函数对其进行初始化,设置为0。
- 如果 classname 中包含’BatchNorm’,说明 m 是一个批量归一化层,那么:
- 如果 m 有 weight 属性,并且不为空,说明它有可学习的缩放因子向量,那么使用
m.weight.data.normal_函数对其进行初始化,设置为均值为1.0,标准差为0.02的正态分布。 - 如果 m 有 bias 属性,并且不为空,说明它有可学习的平移因子向量,那么使用
m.bias.data.fill_函数对其进行初始化,设置为0。
- weight 表示权重,在 Batch Normalization 层中,它用来调节归一化后的特征图的方差,也就是对特征图缩放(scale)的作用,使其适合之后的网络层。因此,weight 在这里也被称为“可学习的缩放因子向量”。
- 在 Batch Normalization 中,bias 用于调整归一化后的特征图的均值,也就是对特征图平移(shift)的作用,使其更加适合上游网络层的输入。因此,bias 也被称为“可学习的平移因子向量”。
TemporalConv
class TemporalConv(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, dilation=1):
super(TemporalConv, self).__init__()
pad = (kernel_size + (kernel_size-1) * (dilation-1) - 1) // 2
self.conv = nn.Conv2d(
in_channels,
out_channels,
kernel_size=(kernel_size, 1),
padding=(pad, 0),
stride=(stride, 1),
dilation=(dilation, 1))
self.bn = nn.BatchNorm2d(out_channels)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
return x
实现一个时序卷积层。它继承了 nn.Module 类,并重写了 __init__ 和 forward 方法。它的构造函数的参数中:
- kernel_size: 卷积核的大小,即卷积核在时间维度上的长度。
- stride: 卷积步长,即卷积核在时间维度上每次移动的距离,默认为1。
- dilation: 卷积扩张,即卷积核在时间维度上的间隔,默认为1。
构造函数中,
- 首先计算了卷积层的填充大小 pad,使得输入和输出的时间维度保持一致。
- 然后创建了一个 nn.Conv2d 对象,用于进行二维卷积操作。注意,这里的卷积核的形状是(kernel_size, 1),即只在时间维度上进行卷积,而不改变空间维度。填充,步长和扩张也只在时间维度上设置。
- 接着创建了一个 nn.BatchNorm2d 对象,用于进行批量归一化操作。
forward 方法中,
- 接受一个输入张量 x x x,它的形状应该是(batch_size, in_channels, time_steps, 1),其中 batch_size 是批次大小,time_steps 是时间步数。
- 然后将 x x x 传入卷积层和批量归一化层,得到输出张量 x x x,它的形状是(batch_size, out_channels, time_steps, 1)。
- 最后返回 x x x。
这样就完成了一个时序卷积层的定义和前向传播过程。
MultiScale_TemporalConv
class MultiScale_TemporalConv(nn.Module):
def __init__(self,
in_channels,
out_channels,
kernel_size=3,
stride=1,
dilations=[1,2,3,4],
residual=True,
residual_kernel_size=1):
super().__init__()
assert out_channels % (len(dilations) + 2) == 0, '# out channels should be multiples of # branches'
# Multiple branches of temporal convolution
self.num_branches = len(dilations) + 2
branch_channels = out_channels // self.num_branches
if type(kernel_size) == list:
assert len(kernel_size) == len(dilations)
else:
kernel_size = [kernel_size]*len(dilations)
# Temporal Convolution branches
self.branches = nn.ModuleList([
nn.Sequential(
nn.Conv2d(
in_channels,
branch_channels,
kernel_size=1,
padding=0),
nn.BatchNorm2d(branch_channels),
nn.ReLU(inplace=True),
TemporalConv(
branch_channels,
branch_channels,
kernel_size=ks,
stride=stride,
dilation=dilation),
)
for ks, dilation in zip(kernel_size, dilations)
])
# Additional Max & 1x1 branch
self.branches.append(nn.Sequential(
nn.Conv2d(in_channels, branch_channels, kernel_size=1, padding=0),
nn.BatchNorm2d(branch_channels),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=(3,1), stride=(stride,1), padding=(1,0)),
nn.BatchNorm2d(branch_channels) # 为什么还要加bn
))
self.branches.append(nn.Sequential(
nn.Conv2d(in_channels, branch_channels, kernel_size=1, padding=0, stride=(stride,1)),
nn.BatchNorm2d(branch_channels)
))
# Residual connection
if not residual:
self.residual = lambda x: 0
elif (in_channels == out_channels) and (stride == 1):
self.residual = lambda x: x
else:
self.residual = TemporalConv(in_channels, out_channels, kernel_size=residual_kernel_size, stride=stride)
# initialize
self.apply(weights_init)
def forward(self, x):
# Input dim: (N,C,T,V)
res = self.residual(x)
branch_outs = []
for tempconv in self.branches:
out = tempconv(x)
branch_outs.append(out)
out = torch.cat(branch_outs, dim=1)
out += res
return out
这段代码定义了一个多尺度的时序卷积模块,它继承了 nn.Module 类。
它的主要功能是:
- 接收一些参数,如输入通道数,输出通道数,卷积核大小,步长,扩张率,是否使用残差连接等。
- 根据扩张率的个数,创建多个分支的时序卷积层,每个分支的输出通道数是总输出通道数除以分支个数。
- 每个分支的时序卷积层由一个 1 × 1 1×1 1×1 的卷积层,一个批归一化层,一个 ReLU 激活层和一个时序卷积层组成。时序卷积层使用了不同的卷积核大小和扩张率,以捕捉不同尺度的时序特征。
- 将所有分支的输出在通道维度上拼接起来,得到最终的输出。
它的主要特点是:
- 它有多个分支,每个分支使用不同的卷积核大小和空洞率,以捕捉不同尺度的时间特征。
- 它有一个残差连接,可以将输入和输出相加,以增强信息流和梯度流。
- 它的输出通道数必须是分支数的整数倍,以便将各个分支的输出拼接起来。
其中,dilations=[1,2,3,4] 指定了每个分支的空洞率,空洞率是指卷积核中每两个相邻元素之间的间隔。空洞率越大,卷积核覆盖的时间范围越大,但是捕捉的时间细节越少。所以这里使用了不同的空洞率,以实现多尺度的时序卷积。
assert out_channels % (len(dilations) + 2) == 0 是一个断言语句,它用于检查输出通道数是否能被分支数整除。如果不能,就会抛出一个异常。这是因为在最后,各个分支的输出要拼接在一起,形成一个维度为
[
b
a
t
c
h
_
s
i
z
e
,
o
u
t
_
c
h
a
n
n
e
l
s
,
s
e
q
_
l
e
n
]
[batch\_size, out\_channels, seq\_len]
[batch_size,out_channels,seq_len] 的张量。如果输出通道数不能被分支数整除,就无法进行拼接。
# Multiple branches of temporal convolution
self.num_branches = len(dilations) + 2
branch_channels = out_channels // self.num_branches
if type(kernel_size) == list:
assert len(kernel_size) == len(dilations)
else:
kernel_size = [kernel_size]*len(dilations)
这段计算分支数和每个分支的输出通道数,以及检查卷积核大小的输入类型。
具体来说:
self.num_branches = len(dilations) + 2是计算分支数,因为除了空洞卷积的分支,还有一个普通的卷积分支(后面的# Additional 1x1 branch)和一个最大池化分支(后面的# Additional Max branch),所以要加2。branch_channels = out_channels // self.num_branches是计算每个分支的输出通道数,用总的输出通道数除以分支数得到。if type(kernel_size) == list:是判断卷积核大小是否是一个列表,如果是,就要求它的长度和空洞率列表的长度相等,否则就会抛出异常。如果不是,就说明卷积核大小是一个整数,就用它乘以空洞率列表的长度,得到一个列表,表示每个空洞卷积分支的卷积核大小。
# Temporal Convolution branches
self.branches = nn.ModuleList([
nn.Sequential(
nn.Conv2d(
in_channels,
branch_channels,
kernel_size=1,
padding=0),
nn.BatchNorm2d(branch_channels),
nn.ReLU(inplace=True),
TemporalConv(
branch_channels,
branch_channels,
kernel_size=ks,
stride=stride,
dilation=dilation),
)
for ks, dilation in zip(kernel_size, dilations)
])
这段是定义了空洞卷积的分支,它使用了一个 nn.ModuleList 来存储多个分支。每个分支是一个 nn.Sequential,包含了四个层:
- 一个 1 × 1 1×1 1×1 的卷积层,用于将输入通道数变为分支通道数。
- 一个批归一化层,用于加速训练和提高稳定性。
- 一个 ReLU 激活函数,用于增加非线性。
- 一个自定义的 TemporalConv 层,用于进行空洞卷积。
for ks, dilation in zip(kernel_size, dilations)这句是一个列表推导式,它用于生成一个列表,列表的元素是 nn.Sequential 对象。它使用了 zip 函数,将卷积核大小和空洞率列表中的元素一一对应起来,然后用 for 循环遍历它们,每次取出一个卷积核大小和一个空洞率,赋值给 ks 和 dilation 变量,然后用这两个变量作为参数,创建一个 nn.Sequential 对象,并将其添加到列表中。最后,这个列表被传递给 nn.ModuleList,作为空洞卷积分支的存储容器。
# Additional Max & 1x1 branch
self.branches.append(nn.Sequential(
nn.Conv2d(in_channels, branch_channels, kernel_size=1, padding=0),
nn.BatchNorm2d(branch_channels),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=(3,1), stride=(stride,1), padding=(1,0)),
nn.BatchNorm2d(branch_channels) # 为什么还要加bn
))
self.branches.append(nn.Sequential(
nn.Conv2d(in_channels, branch_channels, kernel_size=1, padding=0, stride=(stride,1)),
nn.BatchNorm2d(branch_channels)
))
这段是定义了最大池化分支,它使用了 append 方法,将一个 nn.Sequential 对象添加到 nn.ModuleList 中。这个 nn.Sequential 对象包含了五个层:
- 一个 1 × 1 1×1 1×1 的卷积层,用于将输入通道数变为分支通道数。
- 一个批归一化层,用于加速训练和提高稳定性。
- 一个 ReLU 激活函数,用于增加非线性。
- 一个最大池化层,用于降低时间维度,提取全局的时间特征。它的卷积核大小是(3,1),步长是(stride,1),填充是(1,0)。
- 一个批归一化层,用于加速训练和提高稳定性。
这里为什么还要加一个批归一化层,可能是为了防止最大池化后的输出分布发生变化,导致后续层的输入不符合假设,或者是为了与其他分支的输出保持一致,方便拼接。
也定义了普通的卷积分支,它使用了 append 方法,将一个 nn.Sequential 对象添加到 nn.ModuleList 中。这个 nn.Sequential 对象包含了两个层:
- 一个 1 × 1 1×1 1×1 的卷积层,用于将输入通道数变为分支通道数。它的步长是(stride,1),表示在时间维度上进行下采样。
- 一个批归一化层,用于加速训练和提高稳定性。
# Residual connection
if not residual:
self.residual = lambda x: 0
elif (in_channels == out_channels) and (stride == 1):
self.residual = lambda x: x
else:
self.residual = TemporalConv(in_channels, out_channels, kernel_size=residual_kernel_size, stride=stride)
# initialize
self.apply(weights_init)
这段是定义了残差连接,用于将输入和输出相加,以增强信息流和梯度流。
具体来说:
- 如果 residual 参数为 False,表示不使用残差连接,那么就将残差连接定义为一个返回0的函数。
- 如果输入通道数和输出通道数相等,并且步长为1,表示输入和输出的形状相同,那么就将残差连接定义为一个返回输入本身的函数。
- 否则,就将残差连接定义为一个 TemporalConv 层,用于将输入的形状变为与输出一致,然后再相加。
调用 apply 方法,用于对模块的所有参数进行初始化。
def forward(self, x):
# Input dim: (N,C,T,V)
res = self.residual(x)
branch_outs = []
for tempconv in self.branches:
out = tempconv(x)
branch_outs.append(out)
out = torch.cat(branch_outs, dim=1)
out += res
return out
这段是定义了模块的前向传播过程,它接收一个输入张量 x x x,然后进行以下操作:
- 调用残差连接函数,得到一个残差张量 res。
- 创建一个空列表 branch_outs,用于存储各个分支的输出。
- 遍历 nn.ModuleList 中的每个分支,将输入 x x x 传递给分支,得到一个输出 out,然后将其添加到 branch_outs 列表中。
- 使用 torch.cat 函数,将 branch_outs 列表中的所有输出在通道维度上拼接起来,得到一个输出张量 out。
- 将输出张量 out 和残差张量 res 相加,得到最终的输出张量 out,并返回它。
CTRGC
class CTRGC(nn.Module):
def __init__(self, in_channels, out_channels, rel_reduction=8, mid_reduction=1):
super(CTRGC, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
if in_channels == 3 or in_channels == 9:
self.rel_channels = 8
self.mid_channels = 16
else:
self.rel_channels = in_channels // rel_reduction
self.mid_channels = in_channels // mid_reduction
self.conv1 = nn.Conv2d(self.in_channels, self.rel_channels, kernel_size=1)
self.conv2 = nn.Conv2d(self.in_channels, self.rel_channels, kernel_size=1)
self.conv3 = nn.Conv2d(self.in_channels, self.out_channels, kernel_size=1)
self.conv4 = nn.Conv2d(self.rel_channels, self.out_channels, kernel_size=1)
self.tanh = nn.Tanh()
for m in self.modules():
if isinstance(m, nn.Conv2d):
conv_init(m)
elif isinstance(m, nn.BatchNorm2d):
bn_init(m, 1)
def forward(self, x, A=None, alpha=1):
x1, x2, x3 = self.conv1(x).mean(-2), self.conv2(x).mean(-2), self.conv3(x)
x1 = self.tanh(x1.unsqueeze(-1) - x2.unsqueeze(-2))
x1 = self.conv4(x1) * alpha + (A.unsqueeze(0).unsqueeze(0) if A is not None else 0) # N,C,V,V
x1 = torch.einsum('ncuv,nctv->nctu', x1, x3)
return x1
这段是定义了一个 CTRGC 模块,它是一个用于图卷积的模块,可以用于处理空间关系的数据,如人体姿态。
该模块的构造函数,
- 接收输入通道数、输出通道数、
rel_reduction=8空间关系通道数的缩减比例和mid_reduction=1中间通道数的缩减比例作为参数。 - 定义了四个卷积层,self.conv1、self.conv2、self.conv3 和 self.conv4。
这四个卷积层都是 1 × 1 1×1 1×1 的卷积层,它们的作用是改变输入的通道数,而不改变输入的高度和宽度。具体来说:
- self.conv1 是用于将输入变为空间关系通道数的卷积层,它的输入通道数是 self.in_channels,输出通道数是 self.rel_channels。
- self.conv2 是用于将输入变为空间关系通道数的卷积层,它的输入通道数是 self.in_channels,输出通道数是 self.rel_channels。它和 self.conv1 的作用相同,但是用于计算不同的空间关系。
- self.conv3 是用于将输入变为输出通道数的卷积层,它的输入通道数是 self.in_channels,输出通道数是 self.out_channels。它用于计算特征。
- self.conv4 是用于将空间关系通道数变为输出通道数的卷积层,它的输入通道数是 self.rel_channels,输出通道数是 self.out_channels。它用于将空间关系和特征对齐。
- 它根据输入通道数的值,判断是否使用固定的空间关系通道数和中间通道数,如果是3或9,就分别使用8和16,否则就用输入通道数除以缩减比例得到。
这么做可能是为了适应不同的输入通道数,如果输入通道数太小,比如3或9,就使用固定的空间关系通道数和中间通道数,以保证有足够的参数和特征。如果输入通道数较大,就用输入通道数除以缩减比例得到,以减少计算量和内存消耗。
- 最后遍历模块的所有子模块,如果是卷积层,就调用 conv_init 函数进行初始化,如果是批归一化层,就调用 bn_init 函数进行初始化。
forward 是:
- 使用了三个 1 × 1 1×1 1×1 的卷积层,分别将输入 x x x 变为 x 1 x_1 x1, x 2 x_2 x2, x 3 x_3 x3,其中 x 1 x_1 x1 和 x 2 x_2 x2 用于计算空间关系, x 3 x_3 x3 用于计算特征。
- 使用了一个 Tanh 激活函数,将 x 1 x_1 x1 和 x 2 x_2 x2 在最后两个维度上进行广播相减,得到一个表示空间关系的张量 x 1 x_1 x1。
- 使用了一个 1 × 1 1×1 1×1 的卷积层,将 x 1 x_1 x1 变为与输出通道数一致的张量,并乘以一个 α \alpha α 参数,表示空间关系的权重。如果有额外的邻接矩阵 A \mathbf A A,就将其加到 x 1 x_1 x1 上,表示先验的空间关系。
- 使用了一个爱因斯坦求和约定,将 x 1 x_1 x1 和 x 3 x_3 x3 进行矩阵乘法,得到最终的输出张量 x 1 x_1 x1,并返回它。
unit_tcn
class unit_tcn(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=9, stride=1):
super(unit_tcn, self).__init__()
pad = int((kernel_size - 1) / 2)
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=(kernel_size, 1), padding=(pad, 0),
stride=(stride, 1))
self.bn = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
conv_init(self.conv)
bn_init(self.bn, 1)
def forward(self, x):
x = self.bn(self.conv(x))
return x
self.relu = nn.ReLU(inplace=True) 定义一个 ReLU 激活函数,它的参数是 inplace=True,表示直接在原始数据上进行操作,节省内存空间。
构造函数中定义了 relu 函数,为什么 forward 方法只将输入数据 x x x 经过卷积层和批归一化层而没有进行 relu 呢?
可能是因为这个类只是定义了一个时序卷积网络的单元,而不是整个网络的结构。在后面的代码中,会将多个 unit_tcn 类的实例组合起来,形成一个完整的网络,并在每个单元的输出后面加上 ReLU 激活函数。这样做的好处是可以灵活地调整网络的层数和激活函数,而不需要修改 unit_tcn 类的代码。
unit_gcn
class unit_gcn(nn.Module):
def __init__(self, in_channels, out_channels, A, coff_embedding=4, adaptive=True, residual=True):
super(unit_gcn, self).__init__()
inter_channels = out_channels // coff_embedding
self.inter_c = inter_channels
self.out_c = out_channels
self.in_c = in_channels
self.adaptive = adaptive
self.num_subset = A.shape[0]
self.convs = nn.ModuleList()
for i in range(self.num_subset):
self.convs.append(CTRGC(in_channels, out_channels))
if residual:
if in_channels != out_channels:
self.down = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1),
nn.BatchNorm2d(out_channels)
)
else:
self.down = lambda x: x
else:
self.down = lambda x: 0
if self.adaptive:
self.PA = nn.Parameter(torch.from_numpy(A.astype(np.float32)))
else:
self.A = Variable(torch.from_numpy(A.astype(np.float32)), requires_grad=False)
self.alpha = nn.Parameter(torch.zeros(1))
self.bn = nn.BatchNorm2d(out_channels)
self.soft = nn.Softmax(-2)
self.relu = nn.ReLU(inplace=True)
for m in self.modules():
if isinstance(m, nn.Conv2d):
conv_init(m)
elif isinstance(m, nn.BatchNorm2d):
bn_init(m, 1)
bn_init(self.bn, 1e-6)
def forward(self, x):
y = None
if self.adaptive:
A = self.PA
else:
A = self.A.cuda(x.get_device())
for i in range(self.num_subset):
z = self.convs[i](x, A[i], self.alpha)
y = z + y if y is not None else z
y = self.bn(y)
y += self.down(x)
y = self.relu(y)
return y
这段代码的功能是对输入数据 x x x 进行多个图卷积的操作,并输出 y y y。
- 它首先根据是否使用自适应的邻接矩阵,选择合适的 A \mathbf A A 作为图结构的表示。
- 然后,它对每个子集对应的图,使用一个 CTRGC 模块进行图卷积,并将所有子集的输出相加。
- 最后,它对相加后的输出进行批归一化,残差连接和 ReLU 激活,得到最终的输出 y y y。
y += self.down(x)将 y y y 和下采样层处理后的输入数据 x x x 相加,并赋值给 y y y。这样可以实现残差连接。
self.num_subset = A.shape[0]
TCN_GCN_unit
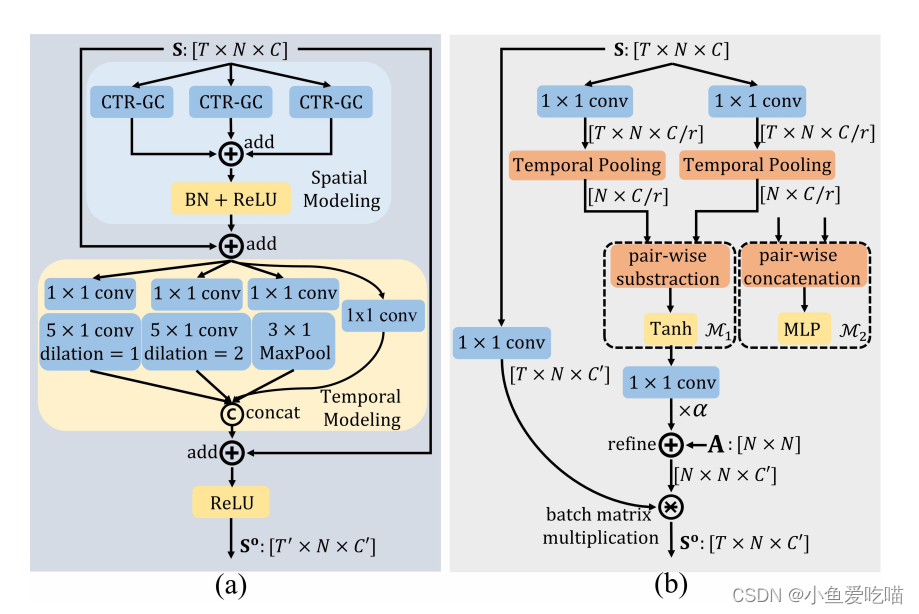
左图为 TCN_GCN_unit 一个基本架构,右图为 CTR-GC 的补充。
class TCN_GCN_unit(nn.Module):
def __init__(self, in_channels, out_channels, A, stride=1, residual=True, adaptive=True, kernel_size=5, dilations=[1,2]):
super(TCN_GCN_unit, self).__init__()
self.gcn1 = unit_gcn(in_channels, out_channels, A, adaptive=adaptive)
self.tcn1 = MultiScale_TemporalConv(out_channels, out_channels, kernel_size=kernel_size, stride=stride, dilations=dilations,
residual=False)
self.relu = nn.ReLU(inplace=True)
if not residual:
self.residual = lambda x: 0
elif (in_channels == out_channels) and (stride == 1):
self.residual = lambda x: x
else:
self.residual = unit_tcn(in_channels, out_channels, kernel_size=1, stride=stride)
def forward(self, x):
y = self.relu(self.tcn1(self.gcn1(x)) + self.residual(x))
return y
这段代码定义了一个名为 TCN_GCN_unit 的类,它是 nn.Module 的子类,用于实现一个时空图卷积网络的单元。它的思想是将图卷积和时序卷积相结合,以捕捉图数据中的空间和时间特征。
它的功能是对输入数据 x x x 进行如下操作:
- 首先,使用 unit_gcn 类实现一个图卷积单元,对输入数据 x x x 进行空间维度上的卷积,并输出 y y y。
- 然后,使用 MultiScale_TemporalConv 类实现一个多尺度时序卷积单元,对图卷积后的输出 y y y 进行时间维度上的卷积,并输出 z z z。
- 接着,根据是否使用残差连接,选择合适的函数作为 self.residual 属性。如果使用残差连接,并且输入通道数不等于输出通道数或者时序卷积的步长不等于1,则使用 unit_tcn 类实现一个时序卷积单元,对输入数据 x x x 进行下采样和通道变换,并输出 w w w。否则,使用恒等函数或零函数作为 self.residual 属性。
- 最后,将时序卷积后的输出
z
z
z 即
self.tcn1(self.gcn1(x))和残差连接后的输出 w w w 即self.residual(x)相加,并经过 ReLU 激活函数,得到最终的输出 y y y。
这样,TCN_GCN_unit 类可以实现一个时空图卷积网络的单元,以提取图数据中的时空特征。
Model
class Model(nn.Module):
def __init__(self, num_class=60, num_point=25, num_person=2, graph=None, graph_args=dict(), in_channels=3,
drop_out=0, adaptive=True):
super(Model, self).__init__()
if graph is None:
raise ValueError()
else:
Graph = import_class(graph)
self.graph = Graph(**graph_args)
A = self.graph.A # 3,25,25
self.num_class = num_class
self.num_point = num_point
self.data_bn = nn.BatchNorm1d(num_person * in_channels * num_point)
base_channel = 64
self.l1 = TCN_GCN_unit(in_channels, base_channel, A, residual=False, adaptive=adaptive)
self.l2 = TCN_GCN_unit(base_channel, base_channel, A, adaptive=adaptive)
self.l3 = TCN_GCN_unit(base_channel, base_channel, A, adaptive=adaptive)
self.l4 = TCN_GCN_unit(base_channel, base_channel, A, adaptive=adaptive)
self.l5 = TCN_GCN_unit(base_channel, base_channel*2, A, stride=2, adaptive=adaptive)
self.l6 = TCN_GCN_unit(base_channel*2, base_channel*2, A, adaptive=adaptive)
self.l7 = TCN_GCN_unit(base_channel*2, base_channel*2, A, adaptive=adaptive)
self.l8 = TCN_GCN_unit(base_channel*2, base_channel*4, A, stride=2, adaptive=adaptive)
self.l9 = TCN_GCN_unit(base_channel*4, base_channel*4, A, adaptive=adaptive)
self.l10 = TCN_GCN_unit(base_channel*4, base_channel*4, A, adaptive=adaptive)
self.fc = nn.Linear(base_channel*4, num_class)
nn.init.normal_(self.fc.weight, 0, math.sqrt(2. / num_class))
bn_init(self.data_bn, 1)
if drop_out:
self.drop_out = nn.Dropout(drop_out)
else:
self.drop_out = lambda x: x
def forward(self, x):
if len(x.shape) == 3:
N, T, VC = x.shape
x = x.view(N, T, self.num_point, -1).permute(0, 3, 1, 2).contiguous().unsqueeze(-1)
N, C, T, V, M = x.size()
x = x.permute(0, 4, 3, 1, 2).contiguous().view(N, M * V * C, T)
x = self.data_bn(x)
x = x.view(N, M, V, C, T).permute(0, 1, 3, 4, 2).contiguous().view(N * M, C, T, V)
x = self.l1(x)
x = self.l2(x)
x = self.l3(x)
x = self.l4(x)
x = self.l5(x)
x = self.l6(x)
x = self.l7(x)
x = self.l8(x)
x = self.l9(x)
x = self.l10(x)
# N*M,C,T,V
c_new = x.size(1)
x = x.view(N, M, c_new, -1)
x = x.mean(3).mean(1)
x = self.drop_out(x)
return self.fc(x)
它定义了一个名为 Model 的类,继承了 nn.Module,有以下几个主要部分:
- 初始化函数:接收一些参数,如类别数、关节数、人数、图结构、输入通道数、dropout 率等,并根据参数创建一些层和变量,如数据归一化层、 TCN_GCN 单元、全连接层等。
- 前向传播函数:接收一个输入张量 x x x,根据模型的结构进行一系列的计算,最后返回一个输出张量。
ntu_rgb_d.py
文件路径:CTR-GCN/graph/ntu_rgb_d.py
import sys
import numpy as np
sys.path.extend(['../'])
from graph import tools
num_node = 25
self_link = [(i, i) for i in range(num_node)]
inward_ori_index = [(1, 2), (2, 21), (3, 21), (4, 3), (5, 21), (6, 5), (7, 6),
(8, 7), (9, 21), (10, 9), (11, 10), (12, 11), (13, 1),
(14, 13), (15, 14), (16, 15), (17, 1), (18, 17), (19, 18),
(20, 19), (22, 23), (23, 8), (24, 25), (25, 12)]
inward = [(i - 1, j - 1) for (i, j) in inward_ori_index]
outward = [(j, i) for (i, j) in inward]
neighbor = inward + outward
class Graph:
def __init__(self, labeling_mode='spatial'):
self.num_node = num_node
self.self_link = self_link
self.inward = inward
self.outward = outward
self.neighbor = neighbor
self.A = self.get_adjacency_matrix(labeling_mode)
def get_adjacency_matrix(self, labeling_mode=None):
if labeling_mode is None:
return self.A
if labeling_mode == 'spatial':
A = tools.get_spatial_graph(num_node, self_link, inward, outward)
else:
raise ValueError()
return A
tools.py
文件路径:CTR-GCN/graph/tools.py
import numpy as np
def get_sgp_mat(num_in, num_out, link):
A = np.zeros((num_in, num_out))
for i, j in link:
A[i, j] = 1
A_norm = A / np.sum(A, axis=0, keepdims=True)
return A_norm
def edge2mat(link, num_node):
A = np.zeros((num_node, num_node))
for i, j in link:
A[j, i] = 1
return A
def get_k_scale_graph(scale, A):
if scale == 1:
return A
An = np.zeros_like(A)
A_power = np.eye(A.shape[0])
for k in range(scale):
A_power = A_power @ A
An += A_power
An[An > 0] = 1
return An
def normalize_digraph(A):
Dl = np.sum(A, 0)
h, w = A.shape
Dn = np.zeros((w, w))
for i in range(w):
if Dl[i] > 0:
Dn[i, i] = Dl[i] ** (-1)
AD = np.dot(A, Dn)
return AD
def get_spatial_graph(num_node, self_link, inward, outward):
I = edge2mat(self_link, num_node)
In = normalize_digraph(edge2mat(inward, num_node))
Out = normalize_digraph(edge2mat(outward, num_node))
A = np.stack((I, In, Out))
return A
def normalize_adjacency_matrix(A):
node_degrees = A.sum(-1)
degs_inv_sqrt = np.power(node_degrees, -0.5)
norm_degs_matrix = np.eye(len(node_degrees)) * degs_inv_sqrt
return (norm_degs_matrix @ A @ norm_degs_matrix).astype(np.float32)
def k_adjacency(A, k, with_self=False, self_factor=1):
assert isinstance(A, np.ndarray)
I = np.eye(len(A), dtype=A.dtype)
if k == 0:
return I
Ak = np.minimum(np.linalg.matrix_power(A + I, k), 1) \
- np.minimum(np.linalg.matrix_power(A + I, k - 1), 1)
if with_self:
Ak += (self_factor * I)
return Ak
def get_multiscale_spatial_graph(num_node, self_link, inward, outward):
I = edge2mat(self_link, num_node)
A1 = edge2mat(inward, num_node)
A2 = edge2mat(outward, num_node)
A3 = k_adjacency(A1, 2)
A4 = k_adjacency(A2, 2)
A1 = normalize_digraph(A1)
A2 = normalize_digraph(A2)
A3 = normalize_digraph(A3)
A4 = normalize_digraph(A4)
A = np.stack((I, A1, A2, A3, A4))
return A
def get_uniform_graph(num_node, self_link, neighbor):
A = normalize_digraph(edge2mat(neighbor + self_link, num_node))
return A