循环展开不仅在编译原理中有涉及到,笔者记得在CSAPP里面也提到了这种优化方法。
话不多说,我们先来看个例子。
int loop(int a)
{
int result = 0;
for(int i = 0; i < a; i++){
result += i;
}
return result;
}
int loop1(int a)
{
int result = 0;
int len = a/2;
for(int i = 0; i < len; i++){
result += 2*i;
result += 2*i+1;
}
if (a % 2) result += a - 1;
return result;
}从功能上来讲,这两个函数是等价的,不同之处在于,for循环每次的step不一样,虽然第二个函数len仅仅为a/2,但是它一次加两个,所以只用加一半的次数就可以了。(对于第二个函数,a如果是奇数,要在最后把最后一个数加上)
我们给这个程序加上main函数来跑一下,测一测这两个函数的运行时间。
#include <stdio.h>
#include <time.h>
clock_t to_duration_in_ms(clock_t start, clock_t end)
{
return 1000 * (end - start) / CLOCKS_PER_SEC;
}
int loop(int a)
{
int result = 0;
for(int i = 0; i < a; i++){
result += i;
}
return result;
}
int loop1(int a)
{
int result = 0;
int len = a/2;
for(int i = 0; i < len; i++){
result += 2*i;
result += 2*i+1;
}
if (a % 2) result += a - 1;
return result;
}
int main()
{
int result,result1;
clock_t start, end;
start = clock();
result = loop(200000000);
end = clock();
printf("result is %d,time is %ldms.\n",result,to_duration_in_ms(start,end));
start = clock();
result1 = loop1(200000000);
end = clock();
printf("result1 is %d,time is %ldms.\n",result1,to_duration_in_ms(start,end));
return 0;
} 
可以多运行几次
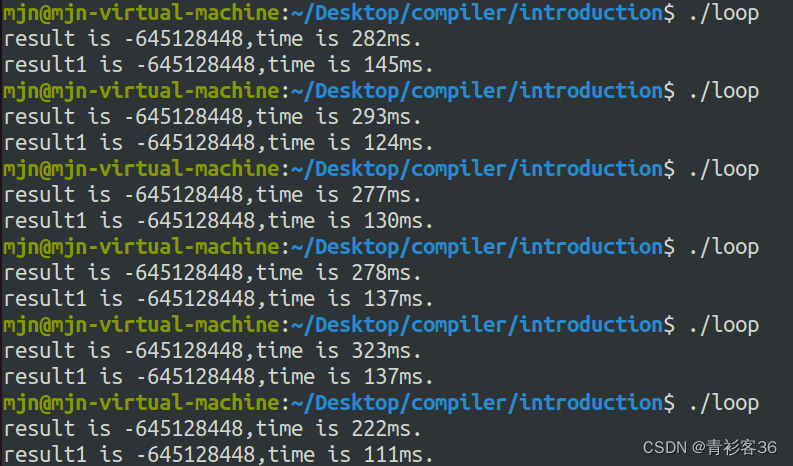
不难看出使用第二种循环(比较次数少)更节省时间,效率更高。
这就是程序的一种优化方法--循环展开
以上是我们自己主动对for循环进行的优化,那我们要是让编译器来帮我们做优化呢?
下面我们来看看,编译器对这个程序做优化的效果
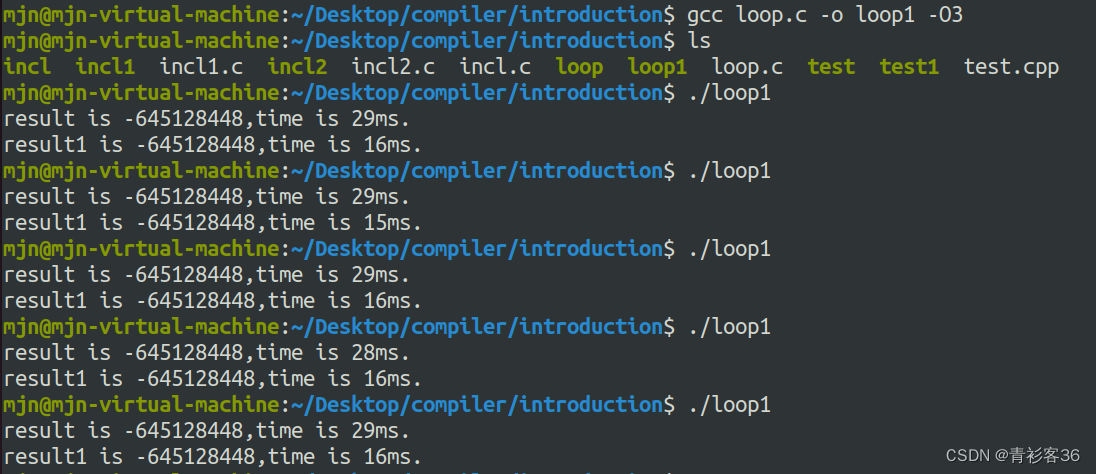
相比于上次测试的结果,经过O3优化后,两个循环的运行时间都有大幅度的降低
可以看出,对代码进行优化是编译器的一个很重要的工作。
有的读者可能疑惑会不会真有代码这样写(这样写代码真的不会被打死吗hh~)笔者记得上学期在Web信息安全课上,看老师讲述PHP 的DoS攻击的时候(补充:PHP DoS是由于PHP本身对键值对数组的实现而导致的在存储恶意数据的时候造成算法复杂度升高,而导致的DoS)看到过下面的代码。这个是PHP本身对于键值对数组的实现,这里可以看出,PHP尽量避免使用循环,注重效率:
static inline ulong zend_inline_hash_func(const char *arKey, uint nKeyLength)
{
register ulong hash = 5381;
/* variant with the hash unrolled eight times */
for (; nKeyLength >= 8; nKeyLength -= 8) {
hash = ((hash << 5) + hash) + *arKey++;
hash = ((hash << 5) + hash) + *arKey++;
hash = ((hash << 5) + hash) + *arKey++;
hash = ((hash << 5) + hash) + *arKey++;
hash = ((hash << 5) + hash) + *arKey++;
hash = ((hash << 5) + hash) + *arKey++;
hash = ((hash << 5) + hash) + *arKey++;
hash = ((hash << 5) + hash) + *arKey++;
}
switch (nKeyLength) {
case 7: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */
case 6: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */
case 5: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */
case 4: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */
case 3: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */
case 2: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */
case 1: hash = ((hash << 5) + hash) + *arKey++; break;
case 0: break;
EMPTY_SWITCH_DEFAULT_CASE()
}
return hash;
}如果这个代码让笔者来写,可能会写成下面这样
static inline ulong zend_inline_hash_func(const char *arKey, uint nKeyLength)
{
register ulong hash = 5381;
/* variant with the hash unrolled eight times */
for (; nKeyLength >= 1; nKeyLength --) {
hash = ((hash << 5) + hash) + *arKey++;
}
return hash;
}那为什么PHP源码中的实现看起来这么冗长呢?
它在这个for循环中step每次减8,for循环体中的八步操作都是一样的,主要是为了减少循环的次数,即循环进行一次,同时操作8步。
像我们上面的第一个例子中,我们是主动给它除以2,让它的循环次数减少为原来的1/2。
对于PHP中键值对数组实现的这个例子,它的循环此处减少为1/8。
ps:上述PHP源码中的switch也比较有意思,它的作用是:如果nKeyLength不是8的倍数,就需要额外的处理最后这几个数字,源码中还特意在case后面提示了/* fallthrough... */,我们知道case后面一般都会跟上break,不然会把后面的代码一行一行的执行一遍,而PHP源码在此处故意不写break,这样的好处是,如果nKeyLength=7,那么从case 7开始执行7行,如果nKeyLength=5,那么从case 5开始执行5行,这种写法还是比较高效的hh~
由此看出PHP源码写的真挺好的(仰望大佬~)。从上面的例子中,可以看出什么呢?如果我们理解编译器的工作,理解底层的知识,对我们自己的编码水平其实也有帮助。
以上为中科大软件学院《编译工程》课后总结,感谢郭燕老师的倾心教授,老师讲的太好啦(^_^)