目录
1、数组
2、一维数组的创建和初始化
2.1数组的创建方式:
2.2数组的初始化
2.3一维数组的使用
2.4一维数组在内存中的存储
3、二维数组的创建和初始化
3.1二维数组的创建
3.2二维数组的初始化
3.3二维数组的使用
3.4二维数组在内存中的存储
4、数组越界
4.1数组下标取值越界
4.2指向数组的指针的指向范围越界
5、数组作为函数参数
5.1数组名
1、数组
数组是由数据类型相同的一些列类型元素组成,需要使用数组时,通过声明数组告诉编译器数组中内含多少元素和这些元素的类型。编译器根据这些信息正确地创建数组。普通变量可以使用的类型,数组元素都可以用。要访问数组中的元素,通过使用数组下标数(也称为索引)表示数组中的各元素。数组元素的编号从0开始。
2、一维数组的创建和初始化
2.1数组的创建方式:
type_t arr_name [const_n];
数组类型 数组名字[数组大小];
数组类型 数组名字[数组大小] = { 初始化值1,初始化值2,...,初始化值N};名词解释:
type_t:数组的元素类型
arr_name:数组名字
const_n:常量表达式,用来指定数组的大小
数组创建,在C99标准之前,[]中要给一个常量才可以,不能使用变量。在C99标准支持了变长数组的概念(后面再介绍)
2.2数组的初始化
数组常用来存储程序需要的数据,在这种情况下,在程序一开始就初始化数组比较好。
数组化的初始化是指:在创建数组的同时给数组的内容一些合理初始值(初始化)。
int arr1[10] = { 1,2,3,4,5,6,7,8,9,10 };
int arr2[] = { 1,2,3,4,5 };
int arr3[10] = { 1,2,3,4,5};
char arr4[10] = { 'h','e','l','l','o' };
char arr5[] = { 'h','i' };
char arr6[] = "helloworld" ;
上面这一些初始化都是成立的,那数组对应的大小是多少?通过代码案例来直接查看:
int main(void)
{
int arr1[10] = { 1,2,3,4,5,6,7,8,9,10 };
int arr2[] = { 1,2,3,4,5 };
int arr3[10] = { 1,2,3,4,5 };
char arr4[10] = { 'h','e','l','l','o' };
char arr5[] = { 'h','i' };
char arr6[] = "helloworld";
printf("arr1的长度为:%d\n", sizeof(arr1) / sizeof(int));
printf("arr2的长度为:%d\n", sizeof(arr2) / sizeof(int));
printf("arr3的长度为:%d\n", sizeof(arr3) / sizeof(int));
printf("arr4的长度为:%d\n", sizeof(arr4) / sizeof(char));
printf("arr5的长度为:%d\n", sizeof(arr5) / sizeof(char));
printf("arr6的长度为:%d\n", sizeof(arr6) / sizeof(char));
return 0;
}
总结:
- 当创建数组的时候有初始化数组的大小,整个数组的长度就为数组下标引用符里面的值
- 当创建数组的时候没有初始化数组的大小,但有给数组一些合理初始值,初始值的个数就是数组的大小
- 当创建数组的时候有初始化数组的大小,但给数组的合理初始值个数少于数组大小时,系统给数组其他没初始化元素补0
2.3一维数组的使用
在操作符篇中((1条消息) C语言入门篇——操作符篇_sakura0908的博客-CSDN博客)详细介绍了下标引用操作符,它是数组访问的操作符,这里不多加介绍。
需要记住的是,数组的首元素的下标是从0开始,而不是数学意义上的第一个(1)。
通过sizeof(数组名)/sizeof(数组元素类型)可以计算数组的元素个数。
int main(void)
{
int arr[10] = { 0 };//数组的不完全初始化
//计算数组的元素个数
int sz = sizeof(arr) / sizeof(arr[0]);
//对数组内容赋值,数组是使用下标来访问的,下标从0开始。所以:
for (int i = 0; i < 10; i++)
{
arr[i] = i;
}
//输出数组的内容
for (int i = 0; i < 10; i++)
{
printf("%d ", arr[i]);
}
return 0;
} 2.4一维数组在内存中的存储
2.4一维数组在内存中的存储
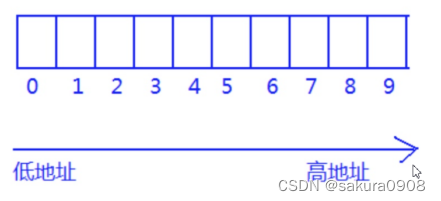
那创建的数组在内存中的存储会是怎么样呢?是连续的一块内存空间存放,还是零零散散的内存空间存放,通过取地址符&访问数组每一个元素的地址就知道答案了:
int main()
{
int arr[10] = { 0 };
int sz = sizeof(arr) / sizeof(arr[0]);
for (int i = 0; i < sz; ++i)
{
printf("&arr[%d] = %p\n", i, &arr[i]);
}
return 0;
}
通过运行效果可以看到每个数组元素的地址是连续的,随着数组下标的增长,数组元素的地址,也是有规律的递增,由此可以得知结论:数组在内存中是连续存放的。
3、二维数组的创建和初始化
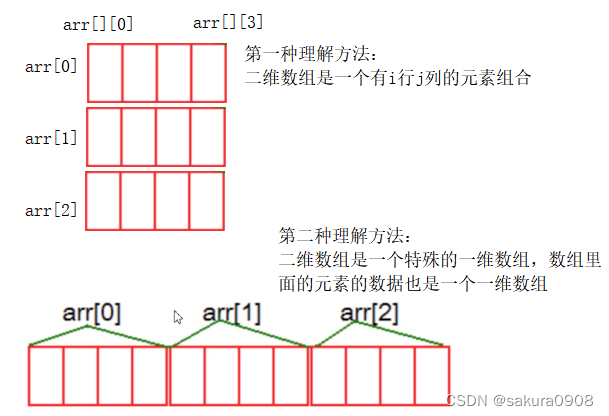
怎么理解二维数组,一般有两种理解,第一种把它看成是行和列的元素组合,第二种把它看成是数组元素也是一个一维数组。两种理解方式都是可以的,看自己更能接受哪一种。通过下面图解更好地理解它:
3.1二维数组的创建
二维数组和一维数组的创建时类似的:
int arr1[5][5];
char arr2[5][5];
double arr3[5][5];
3.2二维数组的初始化
二维数组的初始化和一维数组的初始化有点类似,但也有着不同。
int arr[5][5] = {1,2,3,4};
int arr[5][5] = {{1,2},{4,5}};
int arr[][5] = {{2,3},{4,5}};
记住:二维数组如果有初始化,行可以省略,列不能省略
3.3二维数组的使用
二维数组也是数组,所以也是使用下标引用操作符来使用二维数组。通过for嵌套循环给二维数组赋值和打印。
int main()
{
int arr[3][4] = { 0 };
for (int i = 0; i < 3; i++)
{
for (int j = 0; j < 4; j++)
{
arr[i][j] = i * 4 + j;
}
}
for (int i = 0; i < 3; i++)
{
for (int j = 0; j < 4; j++)
{
printf("%d ", arr[i][j]);
}
printf("\n");
}
return 0;
}
3.4二维数组在内存中的存储
一维数组在内存是连续存放的,那二维数组呢?
int main()
{
int arr[3][4] = { 0 };
int i = 0;
for (i = 0; i < 3; i++)
{
int j = 0;
for (j = 0; j < 4; j++)
{
printf("&arr[%d][%d] = %p\n", i, j, &arr[i][j]);
}
}
return 0;
}
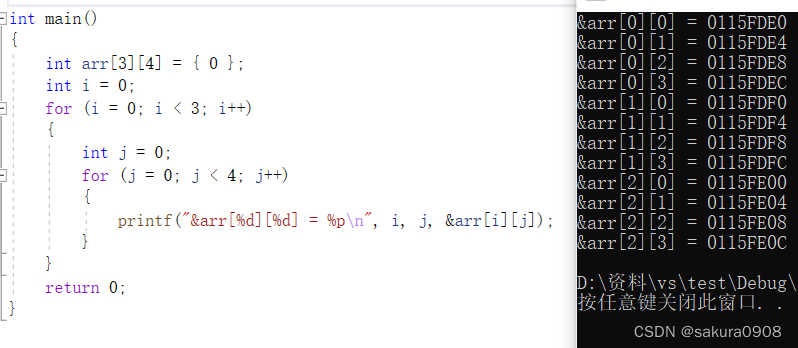
可以看到二维数组在内存中确实也是连续存储的,如下图图解:

4、数组越界
所谓的数组越界,简单地讲就是指数组下标变量的取值超过了初始定义时的大小,导致对数组元素的访问出现在数组的范围之外,这类错误也是 C 语言程序中最常见的错误之一。
在 C 语言中,数组必须是静态的。换而言之,数组的大小必须在程序运行前就确定下来。由于 C 语言并不具有类似 Java 等语言中现有的静态分析工具的功能,可以对程序中数组下标取值范围进行严格检查,一旦发现数组上溢或下溢,都会因抛出异常而终止程序。也就是说,C 语言并不检验数组边界,数组的两端都有可能越界,从而使其他变量的数据甚至程序代码被破坏。
一般情况下,数组的越界错误主要包括两种:数组下标取值越界与指向数组的指针的指向范围越界。
4.1数组下标取值越界
数组的下标是有范围限制的。 数组的下规定是从0开始的,如果数组有n个元素,最后一个元素的下标就是n-1。 所以数组的下标如果小于0,或者大于n-1,就是数组越界访问了,超出了数组合法空间的访问。 C语言本身是不做数组下标的越界检查,编译器也不一定报错,但是编译器不报错,并不意味着程序就是正确的, 所以程序员写代码时,最好自己做越界的检查。

这里的-858993460是什么东西?
十进制数字-858993460转换为二进制数字之后为:1100 1100 1100 1100 1100 1100 1100 1100,二进制转换为十六进制数字之后为:0xCCCCCCCC。
给函数分配栈空间的时候,其中的数据有可能是别的函数使用过的,或者是垃圾数据,所以在使用这段栈空间之前,会先将这段栈空间全部用CC填充,0xCC在X86指令集中对应的汇编是int3。
int(interrupt)是中断,3是中断码,根据中断码进行相应操作,int3起到一个断点的作用,IDE的断点调试就是使用了int3指令,从而不会往下继续执行。
假设 jmp、jz 等跳转语句后面跟的地址值给错了,指向了函数的栈空间,当跳转到函数的栈空间时,如果之前的数据是一些敏感操作,这样就会很危险,但是填充了CC后,程序就会停下来,不会再执行。
这样程序出现内存越界时,调试器可以捕捉这个异常,而在Release下默认内存清零。
而且汉字“烫”的编码也是CC,所以有时候还可能看到很多“烫烫烫烫烫烫烫”。。。
4.2指向数组的指针的指向范围越界
指向数组的指针的指向范围越界是指定义数组时会返回一个指向第一个变量的头指针,对这个指针进行加减运算可以向前或向后移动这个指针,进而访问数组中所有的变量。但在移动指针时,如果不注意移动的次数和位置,会使指针指向数组以外的位置,导致数组发生越界错误。下面的示例代码就是移动指针时没有考虑到移动的次数和数组的范围,从而使程序访问了数组以外的存储单元.
int main(void)
{
int i;
int* p;
int a[5];
//数组a的头指针赋值给指针p
p = a;
for (i = 0; i < 10; i++)
{
//指针p指向的变量
*p = i + 10;
//指针p下一个变量
p++;
}
}for 循环会使指针 p 向后移动 10 次,并且每次向指针指向的单元赋值。但是,这里数组 a 的下标取值范围是 [0,4](即 a[0]、a[1]、a[2]、a[3] 与 a[4])。因此,后 5 次的操作会对未知的内存区域赋值,而这种向内存未知区域赋值的操作会使系统发生错误。
5、数组作为函数参数
在实现具体的功能函数的时候,常常会将数组作为参数传入函数,但是初学者可能会出错,例如,当我们编写冒泡排序算法时,就需要传入数组然后进行排序,有的人也许就会写出下面的代码:
void bubble_sort(int arr[])
{
int sz = sizeof(arr) / sizeof(arr[0]);
for (int i = 0; i < sz - 1; i++)
{
int j = 0;
for (j = 0; j < sz - i - 1; j++)
{
if (arr[j] > arr[j + 1])
{
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
}
int main()
{
int arr[] = { 3,1,7,5,8,9,0,2,4,6 };
bubble_sort(arr);
for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++)
{
printf("%d ", arr[i]);
}
return 0;
}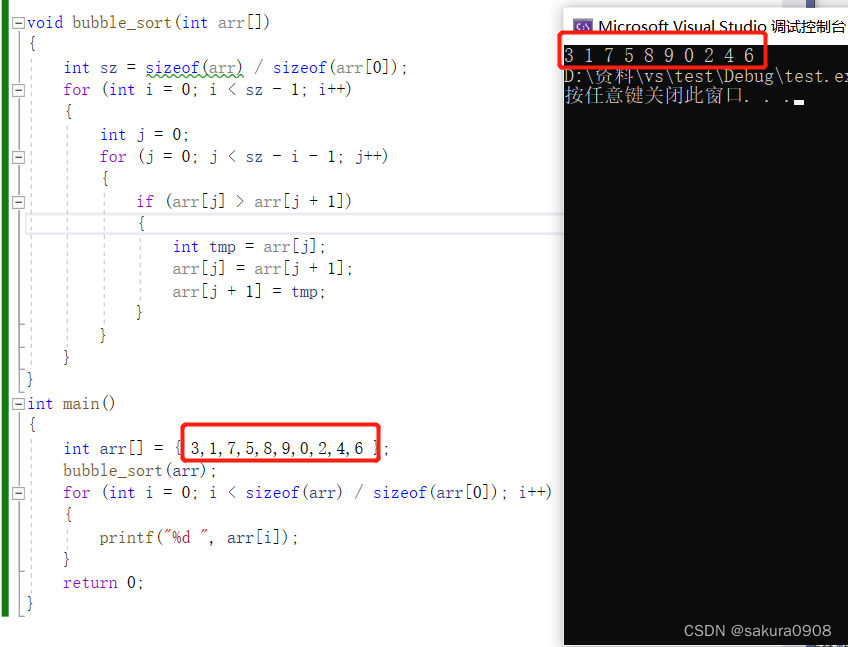 运行发现当我们进行了冒泡排序之后的数组元素排序和原数组元素排序是一样的,这是为什么呢?
运行发现当我们进行了冒泡排序之后的数组元素排序和原数组元素排序是一样的,这是为什么呢?
在我们VS2022的编译软件里面,系统对下面这行代码进行了警告:
int sz = sizeof(arr) / sizeof(arr[0]);

当我们对求出来的sz值进行打印的时候,发现的sz的值为1????这就是一个非常奇怪的地方了,之前介绍过,sizeof(数组名字)/sizeof(数组元素类型)的求值应该是数组元素的个数,那为什么sz的值为1呢?这里就需要我们了解数组名这个概念了。
5.1数组名
一般情况下,C语言中数组名在表达式中被解读为指向数组首元素的指针
C语言中数组名在表达式中被解读为指向数组首元素的指针, 即数组名在表达式中值为数组首元素的地址。但是也有着几种特殊情况:
- sizeof(数组名),计算整个数组的大小,sizeof内部单独放一个数组名,数组名表示整个数 组。
- &数组名,取出的是数组的地址。&数组名,数组名表示整个数组。
除此这两种情况之外,所有的数组名都表示数组首元素的地址。
最后附上数组冒泡排序的设计代码:
void bubble_sort(int arr[],int sz)
{
for (int i = 0; i < sz - 1; i++)
{
for (int j = 0; j < sz - i - 1; j++)
{
if (arr[j] > arr[j + 1])
{
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
}
int main()
{
int arr[] = { 3,1,7,5,8,9,0,2,4,6 };
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr,sz);
for (int i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}