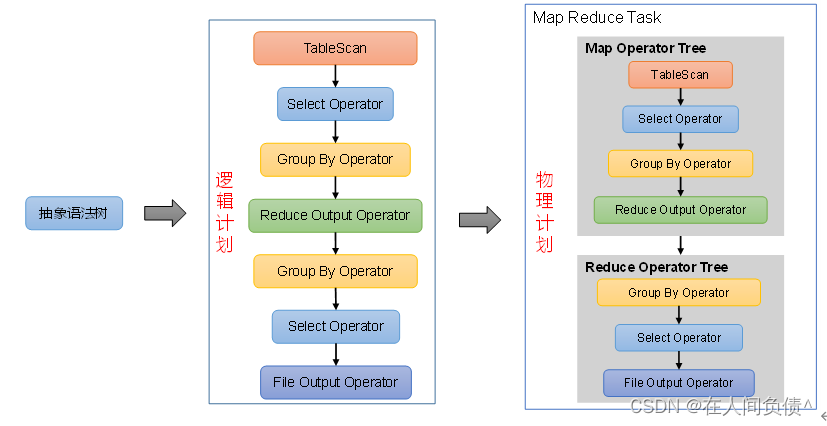
有人说,DolphinDB 是一个时序数据库;
也有人说,DolphinDB 就是 Python 加数据库的结合;还有人说,DolphinDB 是一个支持流数据处理的实时计算软件……
我们经常会听到类似的理解,其实很多小伙伴都会有好奇——DolphinDB 到底是什么定位?
United Real-time Platform for DBMS, Analytics and Stream Processing
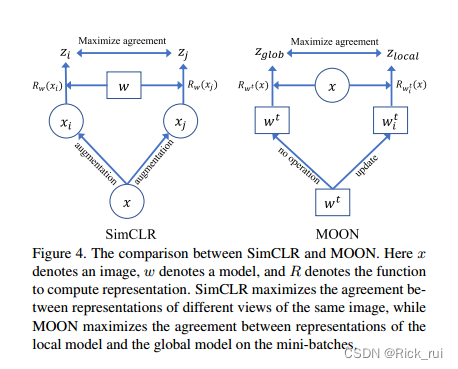
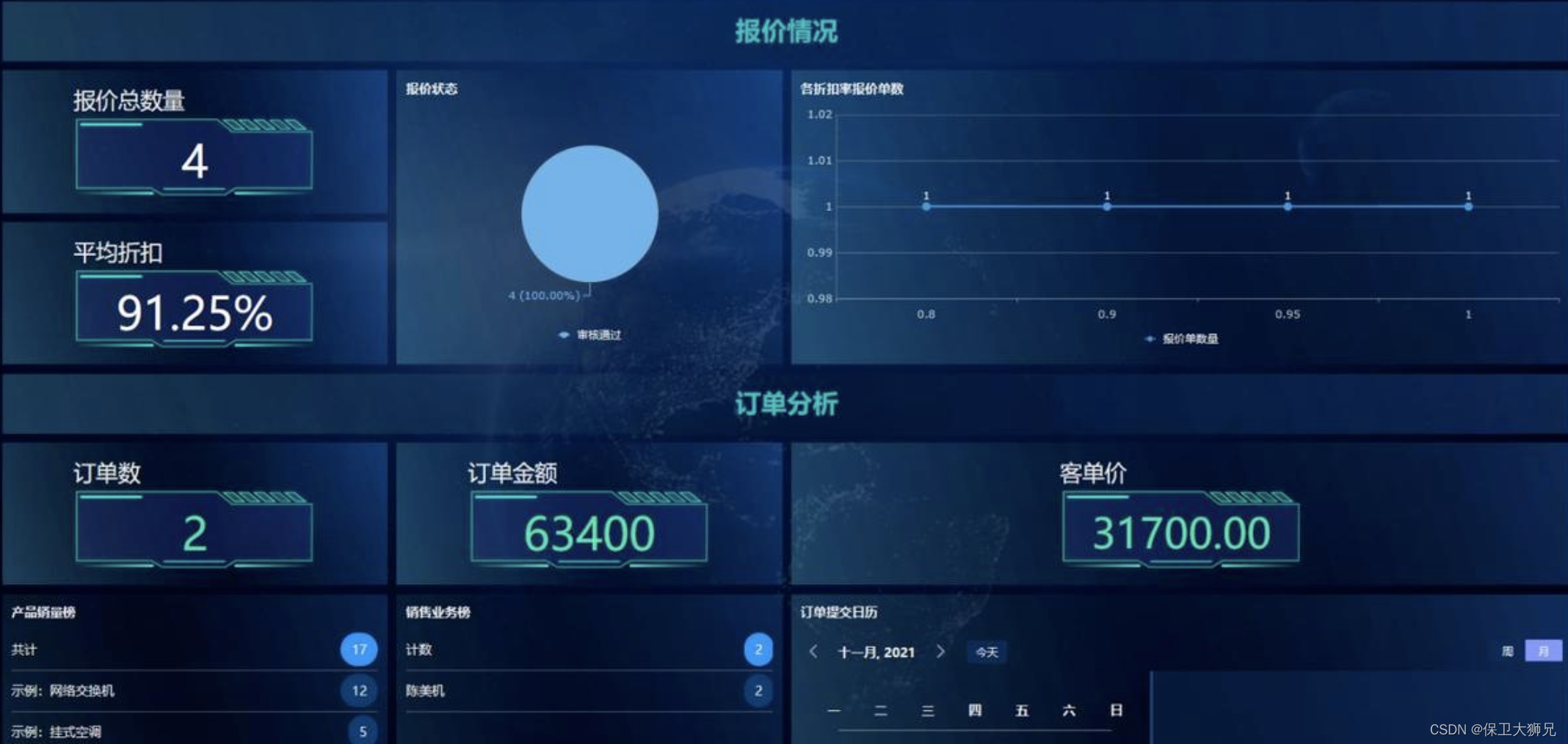
一套完整的量化策略研发和交易流程,大体可以分为行情数据源存储、策略研发与实时交易三个部分。数据存储阶段对于数据库各有选择,有本地离线存储、传统关系型数据库存储,以及专业的时序数据库存储等,比如一般会用到 Oracle、ClickHouse、MySQL 等;策略研发阶段常用 Python 作为主力技术栈;到实时计算与交易环节,为了保证执行效率,往往又会转换成 C++,维护两套系统。

目前常用的解决方案如图所示,其中存在两个转换过程:从存储到分析的数据转换,和从投研到生产的代码转换。这两个转换过程的效率,以及数据分析的计算性能,是整个量化框架效率的决定性因素之一。
这张图中,DolphinDB 在哪里呢?
——DolphinDB 包含了这张图中的全部流程!
作为一款基于高性能时序数据库,支持数据分析与流计算的低延时平台,DolphinDB 不仅拥有领先的存储、查询性能,还有强大的计算和流数据实时分析功能。内置的1500多个函数基本覆盖了量化投研常用的计算逻辑,包括 WorldQuant 101 Alpha、国泰君安191 Alpha 等常用的因子库,用户只需要调用函数就可以一键计算。因此,DolphinDB 很好地解决了存储与计算交互的痛点,并且满足了从投研到生产的流批一体需求……
孰优孰劣?
在整个量化框架中,可以说策略研发环节是决定性能和效率的关键因素。Python 作为串联全流程的核心技术栈,既要与存储行情数据的数据库进行交互,又要保证极高的数据分析性能,为实盘交易奠定基础。我们征集了大家在使用 Python 进行量化投研时最常用的一些函数(库包)和语句,下表列举了部分结果:

在这些经典的计算场景下,Python 丰富的数据分析库包和成熟的生态,为因子投研带来了很大的便利,因此广受普及。
而事实上,以上这些大家常用的函数,在 DolphinDB 中,均有更优的实现——不仅计算效率更高,而且还针对各种金融场景做了特定优化。
与以 Python 为核心的传统量化解决方案相比,DolphinDB 的代码会更加简洁直观,运行时的性能也会有数量级的提升。那么,DolphinDB 能在什么程度上实现超越呢?

直播来袭
2023年4月27日19:30(周四),我们将举办主题为“打破 Python 束缚:Level 2 因子的脚本优化实践”的直播活动。直播将围绕 Level 2高频行情数据,以多个复杂因子计算为案例,为大家展示 Python 与 DolphinDB 的脚本差异和性能对比数据。在第二部分中,为了帮助大家更高效地实现从 Python 到 DolphinDB 的转换,我们还准备了详细的转换攻略,进行线上手把手教学!
本次直播将由 DolphinDB CEO 周小华博士,与数据分析负责人毛忻玥老师一同主讲。点击链接立即报名!
直播中,你将了解到:
- DolphinDB 如何替代以 Python 为核心的传统量化解决方案
- 基于高频行情数据的因子计算,包括 Level 2行情数据概览,用 DolphinDB TSDB 引擎存储 Level 2行情数据,以及基于快照、逐笔成交、逐笔委托数据的因子计算与性能对比
- 高频因子的流式实现,包括状态函数与无状态函数如何拆分,窗口计算与迭代的应用,循环与判断的高效实现,以及用即时编译(JIT)和独特的数组向量(array vector)实现流计算优化
- 从 Python 到 DolphinDB 转换攻略,包括数据结构对比、脚本语言转换思路,以及数据透视、多表关联、循环、时序数据处理等各种计算场景的转换教学
此外,此前有许多小伙伴参与了我们的 “What’s Your Cup of Tea——Python 语句征集”活动,都将获得抽奖资格,中奖名单将在直播后3-5个工作日公布,敬请期待~
干货满满,快点击链接报名!