Model-Contrastive Federated Learning 论文解读
对比学习SimCLR
对比学习的基本想法是同类相聚,异类相离
从不同的图像获得的表征应该相互远离,从相同的图像获得的表征应该彼此靠近
具体框架:
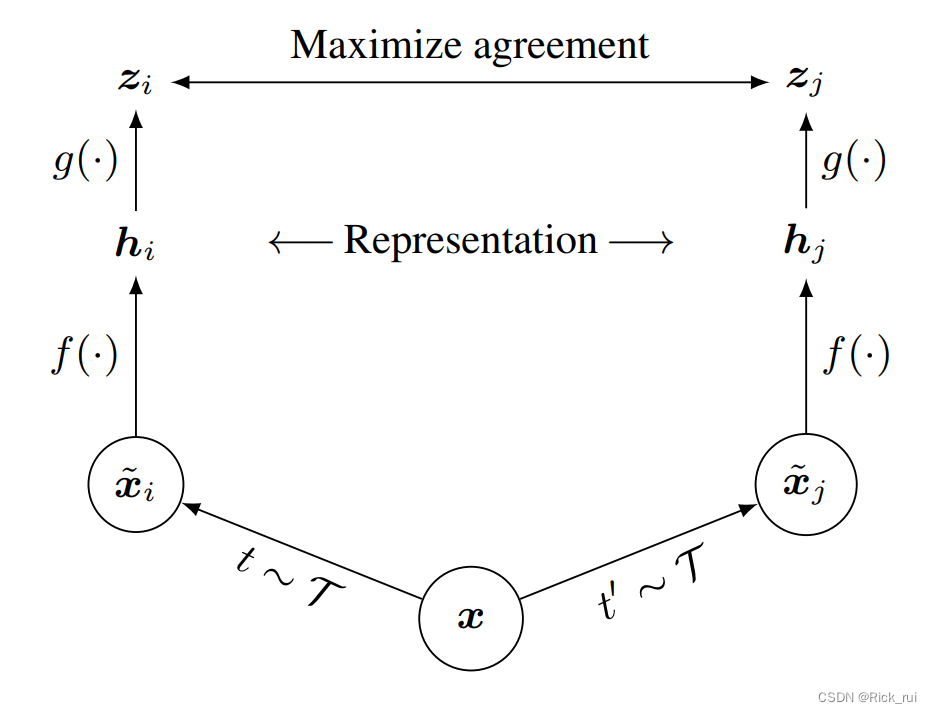

- T随机数据增强模块:随机裁剪然后调整回原始大小(random cropping and resize back)、随机颜色失真(color distortions) 和 随机高斯模糊(random Gaussian blur)
其中 σ是一个 ReLU非线性函数 - 基础编码器(base encoder) f(⋅):用于从生成的视图中提取表示向量,允许选择各种网络架构,这一篇选择 ResNet获得 h i = f ( x ~ i ) = R e s N e t ( x ~ i ) h_i=f(\widetilde{x}_i)=ResNet(\widetilde{x}_i) hi=f(x i)=ResNet(x i);
- 投影头(projection head) g(⋅):将表示映射到应用对比损失的空间。 本文使用一个带有一个隐藏层的 MLP来获得 z = g ( h i ) = w ( 2 ) σ ( w ( 1 ) h i ) z=g(h_i)=w^{(2)}σ(w^{(1)}h_i) z=g(hi)=w(2)σ(w(1)hi)其中 σ是一个 ReLU非线性函数。此外,发现在 zi比在 hi上定义对比损失更有益。所以z只是用来做contrastive learning的训练,而真正当我们使用feature来做下游任务时,还是选取nonlinear projection前的h 特征。这是因为h的信息量是要比z的信息量要高的。
- 对比损失函数(contrastive loss function): 给定 batch中一组生成的视图 { x ~ k } \{\widetilde{x}_k\} {x k},其中包括一对正例 x ~ i \widetilde{x}_i x i和 x ~ j \widetilde{x}_j x j,对比预测任务旨在对给定 x ~ i \widetilde{x}_i x i识别 { x ~ k } i ≠ k \{\widetilde{x}_k \}_{i\neq k} {x k}i=k中的 x ~ j \widetilde{x}_j x j 。
Contrastive loss function
随机抽取 N个样本的小批量样本,并在从小批量样本上生成增强视图,从而产生 2N 个数据点。 本文无明确地指定负例,而是给定一个正对(positivepair),将小批量中的其他 2N−2个增强示例视为负示例。
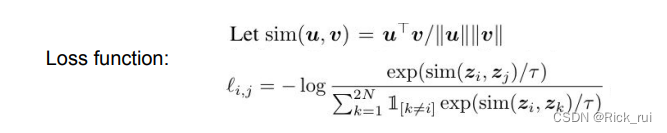
算法流程


Preliminary Experiment
基于这样一个直观的想法来解决Non-IID问题:
the model trained on the whole dataset is able to extract a better feature representation than the model trained on a skewed subset.
作者在CIFAR-10做了个实验,来验证他的这种直觉。
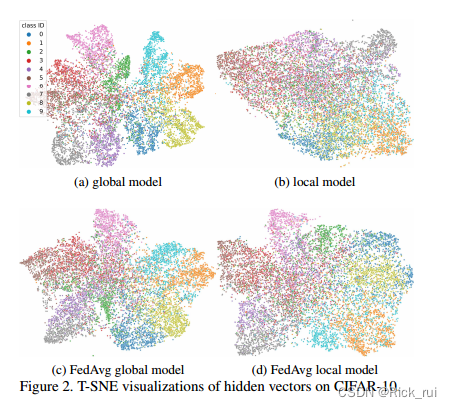
- 2a:用所有数据集放在一起训练一个CNN模型。
- 2b:将所有数据集以Non-IID的方式划分10个客户端,各自训练CNN模型,最后随机选择一个客户端的模型。
- 2c:在10个客户端上使用FedAvg算法训练得到一个global model(10个本地模型加权平均)
- 2d:在10个客户端上使用FedAvg算法训练,然后随机选择一个客户端的local model。(2d学习到的蓝色的类别表征明显比2c差)
Model-Contrastive Federated Learning (MOON)算法
问题定义

MOON的目标
- Since there is always drift in local training and the global model learns a better representation than the local model, MOON aims to decrease the distance between the representation learned by the local model and the representation learned by the global model, and increase the distance between the representation learned by the local model and the representation learned by the previous local model.
MOON的loss函数
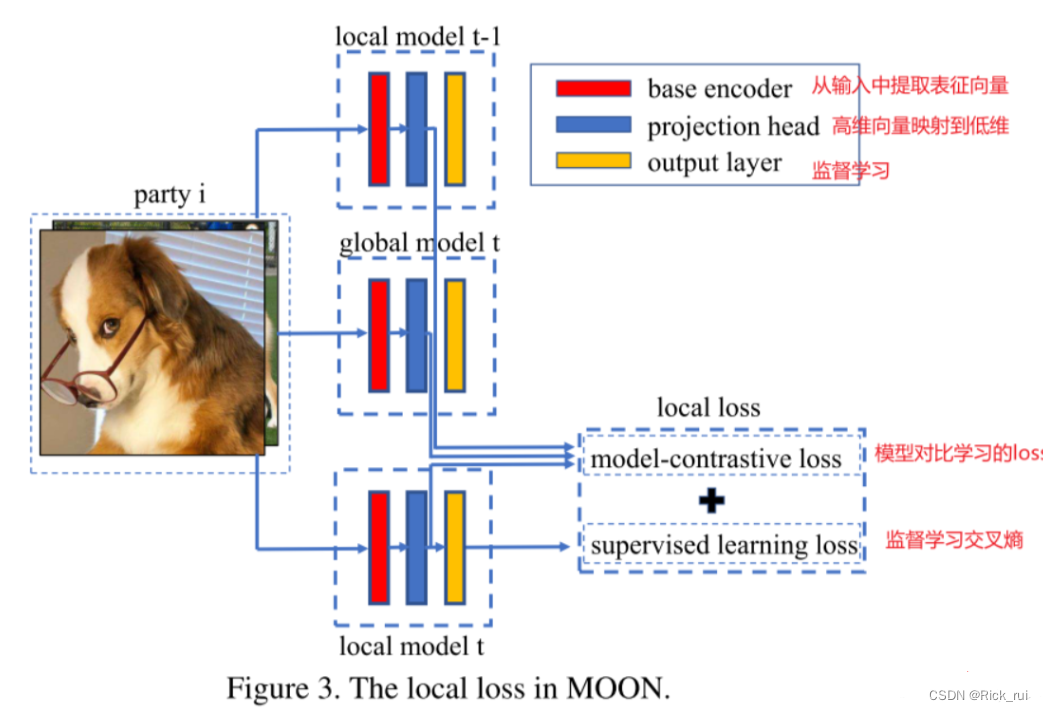
MOON在本地训练阶段,会有三个表征(representation)
- z p r e v = R w i t − 1 ( x ) z_{prev} =R_{w_i^{t-1}}(x) zprev=Rwit−1(x)(上一轮本地训练好的发往server的模型得到的表征)固定
- z g l o b = R w t ( x ) z_{glob}=R_{w^t}(x) zglob=Rwt(x)(这轮开始时发送到本地的全局模型得到的表征)固定
- z = R w i t ( x ) z =R_{w_i^t}(x) z=Rwit(x)(这轮正在被更新的本地模型得到的表征)不断被更新
| With model weight w w w, R w ( ⋅ ) R_w(·) Rw(⋅) to denote the network before the output layer (i.e., R w ( x ) R_w (x) Rw(x)is the mapped representation vector of input x). |
|---|
我们的目标是让 z z z靠近 z g l o b z_{glob} zglob(固定),让 z z z 远离 z p r e v z_{prev} zprev(固定)。
我们的本地模型训练时的loss有两部分组成:传统的交叉熵损失 l s u p \mathcal{l}_{sup} lsup以及本文提出的model-contrastive loss l c o n \mathcal{l}_{con} lcon
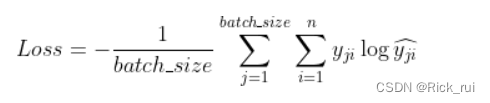
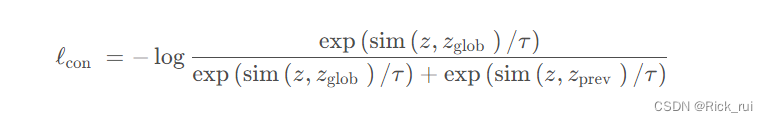
其中
τ
\tau
τ为温度系数,分子是正样本对
(
z
,
z
glob
)
(z, z_{\text {glob}})
(z,zglob),分母是正样本对
(
z
,
z
glob
)
(z, z_{\text {glob}})
(z,zglob)+负样本对
(
z
,
z
prev
)
(z, z_{\text {prev}})
(z,zprev)
MOON的优化目标(loss)如下:
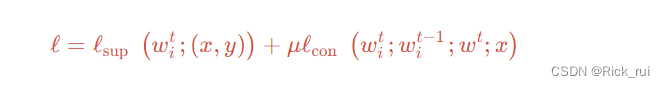
MOON伪代码

SimCLR和MOON
作者还对比了下SimCLR和MOON框架
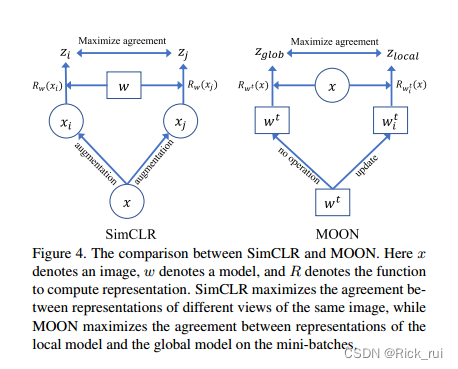
- SimCLR是想让同一张图片(数据层面)的不同view的表征 z i z_i zi和 z j z_j zj最大程度地相近
- MOON是想让全局模型和本地模型的参数(模型层面)对应的表征 z g l o b z_{glob} zglob和 z l o c a l z_{local} zlocal最大程度地相近。
- 理想情况下(IID),全局模型和本地模型训练得到的表征应该是一样好的,那么 l c o n l_{con} lcon是一个常数,此时会得到FedAvg一样的效果。在这种意义上,MOON比FedAvg更具鲁棒性(能处理Non-IID的情况)