- main.py
- same_seeds
- parse_args
- main
- ensemble.py
- configs 文件夹
- Joint(J)的配置文件
- ctrgcn_fsd_J_fold0.yaml
- ctrgcn_fsd_J_fold1.yaml
- Joint Angle(JA)的配置文件
- ctrgcn_fsd_JA_fold0.yaml
- paddlevideo 文件夹
- utils 文件夹
- `__init__.py`
- `registry.py`
- `build_utils.py`
- `config.py`
- `logger.py`
- 训练和测试脚本
- 训练脚本 train.py
- 测试脚本 test.py
- 配置文件 -- MODEL
- RecognizerGCN
- CTRGCN
- graph_ctrgcn.py
- tools_ctrgcn.py
- CTRGCNHead
该项目见飞桨:
PaddleVideo 的文件结构如下图:
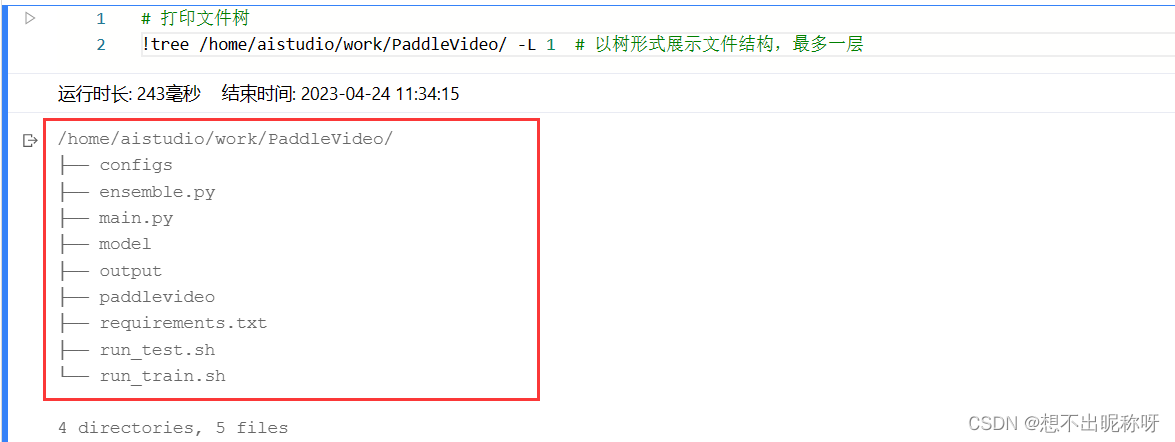
- 其中 output 文件夹用于保存训练过程中生成的权重文件、优化器参数等 .paparams 和 .pdopt 文件,如
CTRGCN_J_fold0_0.6403_best.pdparams和CTRGCN_J_fold0_0.6403_best.pdopt; - model 文件夹用于保存每个模型训练过程中的最优模型权重文件,如
model/CTRGCN_J_fold0.pdparams。 - requirements.txt 文件是要安装的依赖,每一行内容是一个要安装的依赖,其中包含了 Python 第三方库的名称和版本信息。直接执行
pip install -r requirements.txt即可快速安装所有依赖项,并保证各依赖项的版本一致。 - run_train.sh 和 run_test.sh 分别是训练命令和测试命令的集成,因为该模型数较多,一个一个训练和测试过于繁琐。
requirements.txt 内容如下所示:

下面主要讲两个脚本文件、 configs 和 paddlevideo 文件夹。
main.py
文件路径:work/PaddleVideo/main.py
import paddle
import argparse
from paddlevideo.utils import get_config
from paddlevideo.tasks import train_model, train_model_multigrid, test_model, train_dali
from paddlevideo.utils import get_dist_info
import numpy as np
import random
import paddle.fluid as fluid
def same_seeds(seed):
np.random.seed(seed)
random.seed(seed)
fluid.default_startup_program().random_seed = seed
paddle.seed(seed)
def parse_args():
parser = argparse.ArgumentParser("PaddleVideo train script")
parser.add_argument('-c',
'--config',
type=str,
default='configs/example.yaml',
help='config file path')
parser.add_argument('-o',
'--override',
action='append',
default=[],
help='config options to be overridden')
parser.add_argument('--test',
action='store_true',
help='whether to test a model')
parser.add_argument('--train_dali',
action='store_true',
help='whether to use dali to speed up training')
parser.add_argument('--multigrid',
action='store_true',
help='whether to use multigrid training')
parser.add_argument('-w',
'--weights',
type=str,
help='weights for finetuning or testing')
parser.add_argument('--fleet',
action='store_true',
help='whether to use fleet run distributed training')
parser.add_argument('--amp',
action='store_true',
help='whether to open amp training.')
parser.add_argument(
'--validate',
action='store_true',
help='whether to evaluate the checkpoint during training')
args = parser.parse_args()
return args
def main():
same_seeds(0)
args = parse_args()
cfg = get_config(args.config, overrides=args.override, show=(not args.test))
_, world_size = get_dist_info()
parallel = world_size != 1
if parallel:
paddle.distributed.init_parallel_env()
if args.test:
test_model(cfg, weights=args.weights, parallel=parallel)
elif args.train_dali:
train_dali(cfg, weights=args.weights, parallel=parallel)
elif args.multigrid:
train_model_multigrid(cfg, world_size, validate=args.validate)
else:
train_model(cfg,
weights=args.weights,
parallel=parallel,
validate=args.validate,
use_fleet=args.fleet,
amp=args.amp)
if __name__ == '__main__':
main()
通过命令行参数传入配置文件路径、权重路径等信息进行模型训练或测试。
具体实现了 test_model、train_model、train_model_multigrid、train_dali 四个视频任务训练函数。
其中
- test_model 函数用于模型测试,
- train_model 函数用于模型训练,
- train_model_multigrid 函数用于多尺度训练,
- train_dali 函数用于训练数据处理加速。
same_seeds
def same_seeds(seed):
np.random.seed(seed)
random.seed(seed)
fluid.default_startup_program().random_seed = seed
paddle.seed(seed)
这段代码的作用是设定随机数种子,以保证实验结果的可重复性。
具体地,
- np.random.seed(seed) 设定了 numpy 库中随机数生成的种子,
- random.seed(seed) 设定了 Python 内置库中随机数生成的种子,
- fluid.default_startup_program().random_seed = seed 设定了 fluid
框架中随机数生成的种子, - paddle.seed(seed) 设定了 PaddlePaddle 中随机数生成的种子。
这些随机数生成器通常用于网络初始化、数据增强等场景,通过固定随机数种子,我们可以控制每一次生成的随机数序列是相同的,从而保证实验结果的可重复性。
parse_args
def parse_args():
parser = argparse.ArgumentParser("PaddleVideo train script")
parser.add_argument('-c',
'--config',
type=str,
default='configs/example.yaml',
help='config file path')
parser.add_argument('-o',
'--override',
action='append',
default=[],
help='config options to be overridden')
parser.add_argument('--test',
action='store_true',
help='whether to test a model')
parser.add_argument('--train_dali',
action='store_true',
help='whether to use dali to speed up training')
parser.add_argument('--multigrid',
action='store_true',
help='whether to use multigrid training')
parser.add_argument('-w',
'--weights',
type=str,
help='weights for finetuning or testing')
parser.add_argument('--fleet',
action='store_true',
help='whether to use fleet run distributed training')
parser.add_argument('--amp',
action='store_true',
help='whether to open amp training.')
parser.add_argument(
'--validate',
action='store_true',
help='whether to evaluate the checkpoint during training')
args = parser.parse_args()
return args
这段代码定义了一个命令行参数解析器,用于解析用户在命令行中输入的参数。
- 解析器使用 argparse 库进行构建,在 argparse.ArgumentParser 的参数中通过字符串 “PaddleVideo train script” 定义了解析器的描述信息。
- 接下来,解析器使用 add_argument 方法添加了多个命令行参数选项,可以根据用户的需求选择性地解析这些选项。
例如,–test 参数用于指示是否进行模型测试,-c/–config 参数用于指定配置文件路径等。 - 最后,解析器调用 parse_args 方法解析出命令行参数,并将解析出的结果以一个 Namespace 对象的形式返回给主函数,由主函数根据解析得到的参数执行相应的操作。
main
def main():
same_seeds(0)
args = parse_args()
cfg = get_config(args.config, overrides=args.override, show=(not args.test))
_, world_size = get_dist_info()
parallel = world_size != 1
if parallel:
paddle.distributed.init_parallel_env()
if args.test:
test_model(cfg, weights=args.weights, parallel=parallel)
elif args.train_dali:
train_dali(cfg, weights=args.weights, parallel=parallel)
elif args.multigrid:
train_model_multigrid(cfg, world_size, validate=args.validate)
else:
train_model(cfg,
weights=args.weights,
parallel=parallel,
validate=args.validate,
use_fleet=args.fleet,
amp=args.amp)
if __name__ == '__main__':
main()
这段代码是主函数,程序从这里开始执行。
- 首先,调用 same_seeds(0) 函数,设定随机数种子以保证实验结果的可重复性。
- 接着,调用 parse_args() 函数解析命令行参数,并获取程序配置。根据命令行参数的不同选项,程序将执行不同的任务。
- 如果 args.test 为 True,则调用 test_model() 函数进行模型测试,同时传入相应的参数;
- 如果 args.train_dali 为 True,则调用 train_dali() 函数进行训练数据处理加速;
- 如果 args.multigrid 为 True,则调用 train_model_multigrid() 函数进行多尺度训练;
- 否则,则调用 train_model() 函数进行普通的单尺度训练。
- 最后,程序判断当前模块是否被作为脚本直接运行,如果是,则执行主函数 main()。
_, world_size = get_dist_info()
parallel = world_size != 1
if parallel:
paddle.distributed.init_parallel_env()
这段代码的作用是获取当前程序运行的分布式环境信息,并根据是否处于分布式环境下决定是否初始化分布式并行运行环境。
在 PaddlePaddle 中,如果使用多卡训练或分布式训练,则需要初始化分布式并行运行环境。get_dist_info() 函数用于获取当前程序运行的分布式环境信息,返回一个元组 (local_rank, world_size),其中 local_rank 表示当前进程在本地机器中的编号,world_size 表示当前分布式环境下总共有多少个进程在运行。
接着,程序判断 world_size 是否为 1,即当前程序是否在分布式环境下运行。如果 world_size 不为 1,则表明当前程序运行在分布式环境中,需要调用 paddle.distributed.init_parallel_env() 函数初始化分布式并行运行环境。通过初始化后,后续的训练操作将可以自动使用多卡或者分布式运算。
ensemble.py
import os
import re
import numpy as np
import csv
def softmax(X):
m = np.max(X, axis=1, keepdims=True)
exp_X = np.exp(X - m)
exp_X = np.exp(X)
prob = exp_X / np.sum(exp_X, axis=1, keepdims=True)
return prob
def is_Mb(file_name):
pattern = 'CTRGCN_Mb_fold\d+\.npy'
return re.match(pattern, file_name) is not None
output_prob = None
folder = './logits'
for logits_file in os.listdir(folder):
logits = np.load(os.path.join(folder, logits_file))
prob = softmax(logits)
if is_Mb(logits_file):
prob *= 0.7
if output_prob is None:
output_prob = prob
else:
output_prob = output_prob + prob
pred = np.argmax(output_prob, axis=1)
with open('./submission_ensemble.csv', 'w') as f:
writer = csv.writer(f)
writer.writerow(('sample_index', 'predict_category'))
for i, p in enumerate(pred):
writer.writerow((i, p))
configs 文件夹
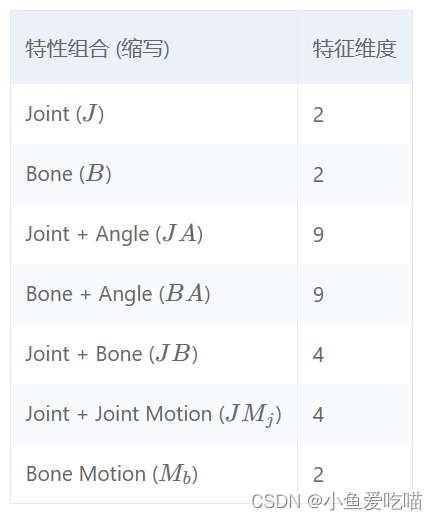
里面是以下7种特征的配置 .yaml 文件:
Joint(J)的配置文件
ctrgcn_fsd_J_fold0.yaml
MODEL: #MODEL field
framework: "RecognizerGCN" #Mandatory, indicate the type of network, associate to the 'paddlevideo/modeling/framework/'.
backbone: #Mandatory, indicate the type of backbone, associate to the 'paddlevideo/modeling/backbones/' .
name: "CTRGCN" #Mandatory, The name of backbone.
in_channels: 2
head:
name: "CTRGCNHead" #Mandatory, indicate the type of head, associate to the 'paddlevideo/modeling/heads'
num_classes: 30 #Optional, the number of classes to be classified.
ls_eps: 0.1
DATASET: #DATASET field
batch_size: 16 #Mandatory, bacth size
num_workers: 2 #Mandatory, the number of subprocess on each GPU.
test_batch_size: 1
test_num_workers: 0
train:
format: "SkeletonDataset" #Mandatory, indicate the type of dataset, associate to the 'paddlevidel/loader/dateset'
file_path: "../dataset/train/J_fold0.npy" #Mandatory, train data index file path
label_path: "../dataset/train/fold0_label.npy"
valid:
format: "SkeletonDataset" #Mandatory, indicate the type of dataset, associate to the 'paddlevidel/loader/dateset'
file_path: "../dataset/valid/J_fold0.npy" #Mandatory, train data index file path
label_path: "../dataset/valid/fold0_label.npy"
test:
format: "SkeletonDataset" #Mandatory, indicate the type of dataset, associate to the 'paddlevidel/loader/dateset'
file_path: "../dataset/test/J.npy" #Mandatory, valid data index file path
test_mode: True
PIPELINE: #PIPELINE field
train: #Mandotary, indicate the pipeline to deal with the training data, associate to the 'paddlevideo/loader/pipelines/'
sample:
name: "UniformSampleFrames"
window_size: 350
transform: #Mandotary, image transfrom operator
- SkeletonNorm_J:
valid: #Mandotary, indicate the pipeline to deal with the training data, associate to the 'paddlevideo/loader/pipelines/'
sample:
name: "UniformSampleFrames"
window_size: 350
test_mode: True
transform: #Mandotary, image transfrom operator
- SkeletonNorm_J:
test: #Mandatory, indicate the pipeline to deal with the validing data. associate to the 'paddlevideo/loader/pipelines/'
sample:
name: "UniformSampleFrames"
window_size: 350
test_mode: True
transform: #Mandotary, image transfrom operator
- SkeletonNorm_J:
OPTIMIZER: #OPTIMIZER field
name: 'Momentum'
momentum: 0.9
learning_rate:
iter_step: False
name: 'CustomWarmupCosineDecay'
max_epoch: 90
warmup_epochs: 10
warmup_start_lr: 0.01
cosine_base_lr: 0.1
weight_decay:
name: 'L2'
value: 4e-4
METRIC:
name: 'SkeletonMetric'
out_file: 'submission.csv'
INFERENCE:
name: 'STGCN_Inference_helper'
num_channels: 5
window_size: 350
vertex_nums: 25
person_nums: 1
model_name: "CTRGCN_J_fold0"
save_interval: 10
val_interval: 1
log_interval: 20 #Optional, the interal of logger, default:10
epochs: 90 #Mandatory, total epoch
ctrgcn_fsd_J_fold1.yaml
同 J_fold0.yaml,区别在于 DATASET 中文件路径不同,修改成 fold1 的训练和测试文件路径即可,fold2、fold3、fold4 同理。
train:
format: "SkeletonDataset"
file_path: "../dataset/train/J_fold1.npy"
label_path: "../dataset/train/fold1_label.npy"
valid:
format: "SkeletonDataset"
file_path: "../dataset/valid/J_fold1.npy"
label_path: "../dataset/valid/fold1_label.npy"
Joint Angle(JA)的配置文件
ctrgcn_fsd_JA_fold0.yaml
MODEL: #MODEL field
framework: "RecognizerGCN" #Mandatory, indicate the type of network, associate to the 'paddlevideo/modeling/framework/'.
backbone: #Mandatory, indicate the type of backbone, associate to the 'paddlevideo/modeling/backbones/' .
name: "CTRGCN" #Mandatory, The name of backbone.
in_channels: 9
head:
name: "CTRGCNHead" #Mandatory, indicate the type of head, associate to the 'paddlevideo/modeling/heads'
num_classes: 30 #Optional, the number of classes to be classified.
ls_eps: 0.1
DATASET: #DATASET field
batch_size: 16 #Mandatory, bacth size
num_workers: 2 #Mandatory, the number of subprocess on each GPU.
test_batch_size: 1
test_num_workers: 0
train:
format: "SkeletonDataset" #Mandatory, indicate the type of dataset, associate to the 'paddlevidel/loader/dateset'
file_path: "../dataset/train/JA_fold0.npy" #Mandatory, train data index file path
label_path: "../dataset/train/fold0_label.npy"
valid:
format: "SkeletonDataset" #Mandatory, indicate the type of dataset, associate to the 'paddlevidel/loader/dateset'
file_path: "../dataset/valid/JA_fold0.npy" #Mandatory, train data index file path
label_path: "../dataset/valid/fold0_label.npy"
test:
format: "SkeletonDataset" #Mandatory, indicate the type of dataset, associate to the 'paddlevidel/loader/dateset'
file_path: "../dataset/test/JA.npy" #Mandatory, valid data index file path
test_mode: True
PIPELINE: #PIPELINE field
train: #Mandotary, indicate the pipeline to deal with the training data, associate to the 'paddlevideo/loader/pipelines/'
sample:
name: "UniformSampleFrames"
window_size: 350
transform: #Mandotary, image transfrom operator
- SkeletonNorm_JA:
valid: #Mandotary, indicate the pipeline to deal with the training data, associate to the 'paddlevideo/loader/pipelines/'
sample:
name: "UniformSampleFrames"
window_size: 350
test_mode: True
transform: #Mandotary, image transfrom operator
- SkeletonNorm_JA:
test: #Mandatory, indicate the pipeline to deal with the validing data. associate to the 'paddlevideo/loader/pipelines/'
sample:
name: "UniformSampleFrames"
window_size: 350
test_mode: True
transform: #Mandotary, image transfrom operator
- SkeletonNorm_JA:
OPTIMIZER: #OPTIMIZER field
name: 'Momentum'
momentum: 0.9
learning_rate:
iter_step: False
name: 'CustomWarmupCosineDecay'
max_epoch: 90
warmup_epochs: 10
warmup_start_lr: 0.01
cosine_base_lr: 0.1
weight_decay:
name: 'L2'
value: 4e-4
METRIC:
name: 'SkeletonMetric'
out_file: 'submission.csv'
INFERENCE:
name: 'STGCN_Inference_helper'
num_channels: 5
window_size: 350
vertex_nums: 25
person_nums: 1
model_name: "CTRGCN_JA_fold0"
save_interval: 10
val_interval: 1
log_interval: 20 #Optional, the interal of logger, default:10
epochs: 90 #Mandatory, total epoch
JA 区别于 J 的在于,不同的特征,除了
- model_name 不同,
- 训练和验证数据文件路径不同,
- SkeletonNorm_J(SkeletonNorm_JA)外,
关键在于 in_channels 的不同:J 特征只有2个特征维度,而 JA 有9个。
paddlevideo 文件夹

utils 文件夹
paddlevideo/utils 文件夹中包含了一些通用的工具函数和预处理方法,用于辅助视频数据的加载、预处理和后处理等。
__init__.py
from .registry import Registry
from .build_utils import build
from .config import *
from .logger import setup_logger, coloring, get_logger
from .record import AverageMeter, build_record, log_batch, log_epoch
from .dist_utils import get_dist_info, main_only
from .save_load import save, load, load_ckpt, mkdir
from .precise_bn import do_preciseBN
__all__ = ['Registry', 'build']
这段代码的作用是从 paddlevideo/utils 目录下导入一些模块或函数,并将它们添加到 paddlevideo.utils 这个包的命名空间中,方便在其他地方使用。
- 例如,
from .registry import Registry这一行就是从registry.py文件中导入 Registry 类,并将它添加到paddlevideo.utils这个包的命名空间中,也就是说,你可以通过paddlevideo.utils.Registry来访问这个类。 __all__是一个特殊的变量,它定义了当使用from paddlevideo.utils import *时要导入的名称。也就是说from paddlevideo.utils import *命令只能导入 Registry 和 build 类,而不会导入其他的如 get_logger。- 所以,如果想导入
get_logger这个函数,可以使用from paddlevideo.utils import get_logger或者import paddlevideo.utils然后使用paddlevideo.utils.get_logger。
__init__.py文件是用来标记一个目录为 Python 包的文件。如,上述是标记paddlevideo/utils目录为paddlevideo.utils包。
- 它可以包含任意的 Python 代码,也可以为空。
- 当一个包被导入时,
__init__.py文件会被隐式地执行,它定义的对象会绑定到包的命名空间中。__init__.py文件是在导入包或包中的模块时运行的。用一个简单的例子来解释一下,假设有一个目录结构如下:
my_package/ __init__.py module1.py module2.py其中,
__init__.py文件的内容是:print("This is my package.") from .module1 import foo from .module2 import bar __all__ = ["foo", "bar"]
module1.py文件的内容是:print("This is module1.") def foo(): print("This is foo.")
module2.py文件的内容是:print("This is module2.") def bar(): print("This is bar.")现在,如果你在 Python 解释器中输入:
>>> import my_package你会看到输出:
This is my package. This is module1. This is module2.这说明,当你导入
my_package这个包时,它的__init__.py文件被隐式地执行了,它打印了一句话,并且从module1.py和module2.py文件中导入了 f o o foo foo 和 b a r bar bar 这两个函数,并将它们添加到了my_package这个包的命名空间中。所以,你可以直接使用my_package.foo()和my_package.bar()来调用这两个函数。
另外,由于
__init__.py文件中定义了__all__ = ["foo", "bar"]这一行,它指定了当你使用from my_package import *时要导入的名称。所以,如果你在 Python 解释器中输入:>>> from my_package import * >>> foo() >>> bar()你会看到输出:
This is foo. This is bar.这说明,当你使用
from my_package import *时,它只导入了__all__中指定的名称,即 f o o foo foo 和 b a r bar bar 这两个函数,并将它们添加到了当前的命名空间中。所以,你可以直接使用foo()和bar()来调用这两个函数。
registry.py
class Registry(object):
"""
The registry that provides name -> object mapping, to support third-party users' custom modules.
To register an object:
.. code-block:: python
BACKBONES = Registry('backbone')
@BACKBONES.register()
class ResNet:
pass
Or:
.. code-block:: python
BACKBONES = Registry('backbone')
class ResNet:
pass
BACKBONES.register(ResNet)
Usage: To build a module.
.. code-block:: python
backbone_name = "ResNet"
b = BACKBONES.get(backbone_name)()
"""
def __init__(self, name):
"""
Args:
name (str): the name of this registry
"""
self._name = name
self._obj_map = {}
def __contains__(self, key):
return self._obj_map.get(key) is not None
def _do_register(self, name, obj):
assert (
name not in self._obj_map
), "An object named '{}' was already registered in '{}' registry!".format(
name, self._name)
self._obj_map[name] = obj
def register(self, obj=None, name=None):
"""
Register the given object under the the name `obj.__name__`.
Can be used as either a decorator or not. See docstring of this class for usage.
"""
if obj is None:
# used as a decorator
def deco(func_or_class, name=name):
if name is None:
name = func_or_class.__name__
self._do_register(name, func_or_class)
return func_or_class
return deco
# used as a function call
if name is None:
name = obj.__name__
self._do_register(name, obj)
def get(self, name):
"""Get the registry record.
Args:
name (str): The class name.
Returns:
ret: The class.
"""
ret = self._obj_map.get(name)
if ret is None:
raise KeyError(
"No object named '{}' found in '{}' registry!".format(
name, self._name))
return ret
这段代码定义了一个 Registry 类,作用是用来注册一些对象,并通过名称来获取它们。这个类有以下几个方法:
__init__(self, name):构造方法,初始化一个空的对象映射字典 _ o b j _ m a p \_obj\_map _obj_map,并记录注册器的名称 n a m e name name。__contains__(self, key):判断一个名称是否已经被注册过,如果是,返回 True,否则返回 False。_do_register(self, name, obj):私有方法,用来将一个对象 o b j obj obj 注册到一个名称 n a m e name name 上,如果该名称已经被注册过,就抛出断言错误。register(self, obj=None, name=None):公开方法,用来注册一个对象或者作为装饰器使用。如果传入了 o b j obj obj 参数,就将它注册到 n a m e name name 参数指定的名称上(如果没有指定 n a m e name name 参数,就使用obj.__name__作为名称)。如果没有传入 o b j obj obj 参数,就返回一个装饰器函数,用来装饰一个类或者函数,并将它注册到指定的名称上。
用法如下:
.. code-block:: python BACKBONES = Registry('backbone') # 创建一个名为'backbone'的注册器 BACKBONES @BACKBONES.register() # 在类 ResNet 定义前加上语法糖,那么这个类 ResNet 就被注册进了这个 BACKBONES 注册器中 class ResNet: passOr:
.. code-block:: python BACKBONES = Registry('backbone') class ResNet: pass BACKBONES.register(ResNet) # BACKBONES 注册器注册这个类 ResNet
get(self, name):根据名称获取一个已经注册的对象,如果没有找到,就抛出 KeyError 异常。
用法如下:
.. code-block:: python backbone_name = "ResNet" b = BACKBONES.get(backbone_name)()
这个类可以用来实现一种插件机制,让不同的模块可以向注册器中添加自己的对象,并通过名称来访问它们。
build_utils.py
def build(cfg, registry, key='name'):
"""Build a module from config dict.
Args:
cfg (dict): Config dict. It should at least contain the key.
registry (XXX): The registry to search the type from.
key (str): the key.
Returns:
obj: The constructed object.
"""
assert isinstance(cfg, dict) and key in cfg
cfg_copy = cfg.copy()
obj_type = cfg_copy.pop(key)
obj_cls = registry.get(obj_type)
if obj_cls is None:
raise KeyError('{} is not in the {} registry'.format(
obj_type, registry.name))
return obj_cls(**cfg_copy)
这段代码是定义了一个 b u i l d build build 函数,它的作用是根据一个配置字典和一个注册器,构建一个模块对象。它的参数和返回值如下:
- c f g cfg cfg ( d i c t dict dict):配置字典,它至少应该包含一个 k e y key key,表示要构建的模块的类型。
c f g cfg cfg 字典可以有多个键,只要其中有一个键是 n a m e name name,用来指定要从注册器中获取的类。其他的键和值都会作为参数传递给类的构造函数。
例如,如果想要创建一个 T h i n g 3 Thing3 Thing3 的实例,而 T h i n g 3 Thing3 Thing3 的构造函数需要三个参数, a r g 1 arg1 arg1, a r g 2 arg2 arg2 和 a r g 3 arg3 arg3,可以使用以下代码:cfg = { 'name': 'Thing3', 'arg1': 5, 'arg2': 6, 'arg3': 7 }那么
build(cfg, registry)就相当于调用Thing3(arg1=5, arg2=6, arg3=7),并返回一个 T h i n g 3 Thing3 Thing3 的实例。
- r e g i s t r y registry registry (XXX):注册器,它是一个 Registry 类的实例,用来存储不同类型的模块类。
- k e y key key ( s t r str str):配置字典中表示模块类型的键,默认为 ‘name’。
- o b j obj obj:返回值,是根据配置字典和注册器中获取的模块类构造的对象。
函数的逻辑如下:
- 首先断言 c f g cfg cfg 是一个字典,并且包含 k e y key key 这个键。
- 然后复制一份 c f g cfg cfg,并从中弹出 k e y key key 对应的值,赋给 o b j _ t y p e obj\_type obj_type,表示要构建的模块类型。
- 接着从注册器中根据 o b j _ t y p e obj\_type obj_type 获取对应的模块类,赋给 o b j _ c l s obj\_cls obj_cls。如果没有找到,就抛出 K e y E r r o r KeyError KeyError 异常。
- 最后用剩余的 c f g _ c o p y cfg\_copy cfg_copy 作为关键字参数,调用 o b j _ c l s obj\_cls obj_cls 构造一个对象,并返回。
举个例子,假设有以下配置字典和注册器:
cfg = { 'name': 'Thing1', 'arg1': 1, 'arg2': 2 } registry = Registry('thing') registry.register('Thing1', Thing1) registry.register('Thing2', Thing2)
- 这段代码创建一个名为 t h i n g thing thing 的注册器,然后向注册器中注册两个类, T h i n g 1 Thing1 Thing1 和 T h i n g 2 Thing2 Thing2( T h i n g 1 Thing1 Thing1 和 T h i n g 2 Thing2 Thing2 是两个自定义的类),并给它们分别指定一个字符串作为键。
- 那么调用
build(cfg, registry)就相当于调用Thing1(arg1=1, arg2=2)(这是因为 c f g cfg cfg 中的'name': 'Thing1'指定了调用 b u i l d build build 要创建 T h i n g 1 Thing1 Thing1 类),并返回一个 T h i n g 1 Thing1 Thing1 的实例。注册器是一个用于存储和查找类的容器,可以根据键来获取对应的类。
- 例如,如果想要创建一个 T h i n g 1 Thing1 Thing1 的实例,可以使用以下代码:
thing1 = registry.get('Thing1')()或者thing1 = registry['Thing1']()。如果想要创建 T h i n g 1 Thing1 Thing1 和 T h i n g 2 Thing2 Thing2 的实例,可以使用两个不同的 c f g cfg cfg 字典,分别指定 n a m e name name 键的值为 ′ T h i n g 1 ′ 'Thing1' ′Thing1′ 和 ′ T h i n g 2 ′ 'Thing2' ′Thing2′,然后分别调用
build(cfg, registry)函数。例如,可以使用以下代码:cfg1 = { 'name': 'Thing1', 'arg1': 1, 'arg2': 2 } cfg2 = { 'name': 'Thing2', 'arg1': 3, 'arg2': 4 } thing1 = build(cfg1, registry) # 创建 Thing1 的实例 thing2 = build(cfg2, registry) # 创建 Thing2 的实例
config.py
import os
import yaml
from paddlevideo.utils.logger import coloring, get_logger, setup_logger
__all__ = ['get_config']
logger = setup_logger("./", name="paddlevideo", level="INFO")
class AttrDict(dict):
def __getattr__(self, key):
return self[key]
def __setattr__(self, key, value):
if key in self.__dict__:
self.__dict__[key] = value
else:
self[key] = value
def create_attr_dict(yaml_config):
from ast import literal_eval
for key, value in yaml_config.items():
if type(value) is dict:
yaml_config[key] = value = AttrDict(value)
if isinstance(value, str):
try:
value = literal_eval(value)
except BaseException:
pass
if isinstance(value, AttrDict):
create_attr_dict(yaml_config[key])
else:
yaml_config[key] = value
def parse_config(cfg_file):
"""Load a config file into AttrDict"""
with open(cfg_file, 'r') as fopen:
yaml_config = AttrDict(yaml.load(fopen, Loader=yaml.SafeLoader))
create_attr_dict(yaml_config)
return yaml_config
def print_dict(d, delimiter=0):
"""
Recursively visualize a dict and
indenting acrrording by the relationship of keys.
"""
placeholder = "-" * 60
for k, v in sorted(d.items()):
if isinstance(v, dict):
logger.info("{}{} : ".format(delimiter * " ", coloring(k,
"HEADER")))
print_dict(v, delimiter + 4)
elif isinstance(v, list) and len(v) >= 1 and isinstance(v[0], dict):
logger.info("{}{} : ".format(delimiter * " ",
coloring(str(k), "HEADER")))
for value in v:
print_dict(value, delimiter + 4)
else:
logger.info("{}{} : {}".format(delimiter * " ",
coloring(k, "HEADER"),
coloring(v, "OKGREEN")))
if k.isupper():
logger.info(placeholder)
def print_config(config):
"""
visualize configs
Arguments:
config: configs
"""
print_dict(config)
def check_config(config):
"""
Check config
"""
pass
def override(dl, ks, v):
"""
Recursively replace dict of list
Args:
dl(dict or list): dict or list to be replaced
ks(list): list of keys
v(str): value to be replaced
"""
def str2num(v):
try:
return eval(v)
except Exception:
return v
assert isinstance(dl, (list, dict)), ("{} should be a list or a dict")
assert len(ks) > 0, ('lenght of keys should larger than 0')
if isinstance(dl, list):
k = str2num(ks[0])
if len(ks) == 1:
assert k < len(dl), ('index({}) out of range({})'.format(k, dl))
dl[k] = str2num(v)
else:
override(dl[k], ks[1:], v)
else:
if len(ks) == 1:
#assert ks[0] in dl, ('{} is not exist in {}'.format(ks[0], dl))
if not ks[0] in dl:
logger.warning('A new filed ({}) detected!'.format(ks[0], dl))
dl[ks[0]] = str2num(v)
else:
assert ks[0] in dl, (
'({}) doesn\'t exist in {}, a new dict field is invalid'.format(
ks[0], dl))
override(dl[ks[0]], ks[1:], v)
def override_config(config, options=None):
"""
Recursively override the config
Args:
config(dict): dict to be replaced
options(list): list of pairs(key0.key1.idx.key2=value)
such as: [
epochs=20',
'PIPELINE.train.transform.1.ResizeImage.resize_short=300'
]
Returns:
config(dict): replaced config
"""
if options is not None:
for opt in options:
assert isinstance(opt,
str), ("option({}) should be a str".format(opt))
assert "=" in opt, (
"option({}) should contain a ="
"to distinguish between key and value".format(opt))
pair = opt.split('=')
assert len(pair) == 2, ("there can be only a = in the option")
key, value = pair
keys = key.split('.')
override(config, keys, value)
return config
def get_config(fname, overrides=None, show=True):
"""
Read config from file
"""
assert os.path.exists(fname), ('config file({}) is not exist'.format(fname))
config = parse_config(fname)
override_config(config, overrides)
if show:
print_config(config)
check_config(config)
return config
AttrDict类,继承自 dict 类,重写了 getattr 和 setattr 方法,使得可以用点号访问字典中的键和值,而不需要用方括号。create_attr_dict函数,用于把一个普通的字典转换为 AttrDict 类型,并递归地处理字典中的子字典。这个函数还会尝试把字典中的字符串值转换为 Python 的原生类型,例如数字或布尔值。parse_config函数,用于从一个 YAML 文件中读取配置信息,并返回一个 AttrDict 类型的对象。这个函数会调用create_attr_dict函数来处理 YAML 文件中的内容。
YAML 是一种人类可读的数据序列化语言,常用于配置文件或数据交换。Python 中有一个 PyYAML 模块,可以用来加载,解析和写入 YAML 文件。这个函数就是利用了 PyYAML 模块来读取 YAML 配置文件,并把它转换为一个方便访问的 AttrDict 对象。
print_dict函数,用于递归地打印一个字典的键和值,并根据键的层级关系进行缩进。这个函数还会用不同的颜色来显示键和值(通过 coloring 实现),以及用一条横线来分隔大写的键。print_config函数,用于调用print_dict函数来可视化输出一个配置对象。
override这个函数的作用是可以用一个简单的方式来修改一个复杂的字典或列表中的某个值,而不需要写很多层的索引或键。在替换值过程中,还会进行一些断言和警告,检查索引是否越界,键是否存在,以及是否出现了新的字段。
这样可以提高代码的可读性和可维护性。例如,如果有一个嵌套的字典,如下:
d = { 'a': { 'b': { 'c': 1, 'd': 2 }, 'e': 3 }, 'f': 4 }如果想要把
d[‘a’][‘b’][‘c’]的值改为 5,可以使用 override 函数,只需要传入一个键的列表[‘a’, ‘b’, ‘c’],而不需要写d[‘a’][‘b’][‘c’] = 5。例如:override(d, ['a', 'b', 'c'], 5),这样就可以实现同样的效果,但是更简洁和清晰。
override_config这个函数的作用是根据一个选项列表,递归地覆盖一个配置字典中的某些值。
这个函数接受两个参数:
- config 是要被覆盖的配置字典,
- options 是一个字符串列表,每个字符串表示一个键和值的对应关系,用等号分隔。键可以用点号连接多个子键,表示配置字典中的层级关系。
例如:
options = [ 'epochs=20', 'PIPELINE.train.transform.1.ResizeImage.resize_short=300' ]这个函数会调用之前定义的 override 函数,把每个选项中的键和值分别传入,实现对配置字典的修改。
例如,上面的选项列表会把
config[‘epochs’]的值改为 20,把config[‘PIPELINE’][‘train’][‘transform’][1][‘ResizeImage’][‘resize_short’]的值改为 300。这样就可以实现对配置字典的自定义修改。
get_config这个函数的意思是从一个文件中读取配置信息,并根据一些选项进行覆盖和检查。
这个函数接受三个参数:
- fname 是配置文件的路径,
- overrides 是一个选项列表,用于修改配置信息,
- show 是一个布尔值,表示是否打印配置信息。
这个函数会调用之前定义的 parse_config,override_config,print_config 和 check_config 函数,分别实现解析,覆盖,打印和检查配置信息的功能。
最后,这个函数会返回一个配置对象。
logger.py
import logging
import os
import sys
import datetime
from paddle.distributed import ParallelEnv
Color = {
'RED': '\033[31m',
'HEADER': '\033[35m', # deep purple
'PURPLE': '\033[95m', # purple
'OKBLUE': '\033[94m',
'OKGREEN': '\033[92m',
'WARNING': '\033[93m',
'FAIL': '\033[91m',
'ENDC': '\033[0m'
}
def coloring(message, color="OKGREEN"):
assert color in Color.keys()
if os.environ.get('COLORING', True):
return Color[color] + str(message) + Color["ENDC"]
else:
return message
logger_initialized = []
def setup_logger(output=None, name="paddlevideo", level="INFO"):
"""
Initialize the paddlevideo logger and set its verbosity level to "INFO".
Args:
output (str): a file name or a directory to save log. If None, will not save log file.
If ends with ".txt" or ".log", assumed to be a file name.
Otherwise, logs will be saved to `output/log.txt`.
name (str): the root module name of this logger
Returns:
logging.Logger: a logger
"""
def time_zone(sec, fmt):
real_time = datetime.datetime.now()
return real_time.timetuple()
logging.Formatter.converter = time_zone
logger = logging.getLogger(name)
if level == "INFO":
logger.setLevel(logging.INFO)
elif level=="DEBUG":
logger.setLevel(logging.DEBUG)
logger.propagate = False
if level == "DEBUG":
plain_formatter = logging.Formatter(
"[%(asctime)s] %(name)s %(levelname)s: %(message)s",
datefmt="%m/%d %H:%M:%S")
else:
plain_formatter = logging.Formatter(
"[%(asctime)s] %(message)s",
datefmt="%m/%d %H:%M:%S")
# stdout logging: master only
local_rank = ParallelEnv().local_rank
if local_rank == 0:
ch = logging.StreamHandler(stream=sys.stdout)
ch.setLevel(logging.DEBUG)
formatter = plain_formatter
ch.setFormatter(formatter)
logger.addHandler(ch)
# file logging: all workers
if output is not None:
if output.endswith(".txt") or output.endswith(".log"):
filename = output
else:
filename = os.path.join(output, "log.txt")
if local_rank > 0:
filename = filename + ".rank{}".format(local_rank)
# PathManager.mkdirs(os.path.dirname(filename))
os.makedirs(os.path.dirname(filename), exist_ok=True)
# fh = logging.StreamHandler(_cached_log_stream(filename)
fh = logging.FileHandler(filename, mode='a')
fh.setLevel(logging.DEBUG)
fh.setFormatter(plain_formatter)
logger.addHandler(fh)
logger_initialized.append(name)
return logger
def get_logger(name, output=None):
logger = logging.getLogger(name)
if name in logger_initialized:
return logger
return setup_logger(name=name, output=name)
logging 模块是 Python 标准库中提供的一个功能强大而灵活的日志系统,可以让你在程序中输出不同级别的日志信息。
- 首先导入了 logging 模块,
- C o l o r Color Color 字典,用来给不同级别的日志信息添加颜色。
coloring函数,用来根据颜色参数给消息添加颜色。logger_initialized列表,用来存储已经初始化过的 logger 对象。
logger 对象是 logging 模块中的基本类,它提供了应用程序直接使用的接口。通过调用
logging.getLogger(name)函数,可以获取一个 logger 对象,如果 name 相同,那么返回的是同一个 logger 对象。
setup_logger函数,用来初始化一个名为 paddlevideo 的 logger 对象,并根据参数设置其输出级别和文件。
- 设置了 logging.Formatter.converter 属性为 time_zone 函数,用来自定义日志信息中的时间格式。
- 设置 logger 对象的日志级别为 INFO 或 DEBUG。
如果level是 DEBUG,那么日志信息中会包含时间、名称、级别和消息;如果 level 是 INFO,那么日志信息中只包含时间和消息。
- 设置 logger 对象的 propagate 属性为 False,表示不向上级 logger 传递日志信息。
- 获取当前进程的 local_rank 值,如果是0,表示是主进程,那么创建一个 StreamHandler 对象,用来将日志信息输出到标准输出流。设置该 handler 对象的级别为 DEBUG,格式为 plain_formatter,并添加到 logger 对象中。
- 如果 output 参数不为空,表示需要将日志信息保存到文件中。根据 output 参数的值,确定文件名。如果 output 以".txt"或".log"结尾,那么认为它是一个文件名;否则,将在 output 目录下创建一个"log.txt"文件。如果 local_rank 值大于0,表示是子进程,那么在文件名后面加上".rank"和 local_rank 值,以区分不同进程的日志文件。
get_logger函数,用来获取一个指定名称的 logger 对象。
– 如果 name 已经在 logger_initialized 列表中,表示该 logger 对象已经被初始化过,那么直接返回该 logger 对象。
– 否则,调用 setup_logger 函数,用 name 作为参数,来初始化该 logger 对象,并返回它。
训练和测试脚本
训练脚本 train.py
路径:work/PaddleVideo/paddlevideo/tasks/train.py
import time
import os
import os.path as osp
import paddle
import paddle.distributed as dist
import paddle.distributed.fleet as fleet
from ..loader.builder import build_dataloader, build_dataset
from ..modeling.builder import build_model
from ..solver import build_lr, build_optimizer
from ..utils import do_preciseBN
from paddlevideo.utils import get_logger
from paddlevideo.utils import (build_record, log_batch, log_epoch, save, load,
mkdir)
import numpy as np
import paddle.nn.functional as F
def train_model(cfg,
weights=None,
parallel=True,
validate=True,
amp=False,
use_fleet=False):
"""Train model entry
Args:
cfg (dict): configuration.
weights (str): weights path for finetuning.
parallel (bool): Whether multi-cards training. Default: True.
validate (bool): Whether to do evaluation. Default: False.
"""
if use_fleet:
fleet.init(is_collective=True)
logger = get_logger("paddlevideo")
batch_size = cfg.DATASET.get('batch_size', 8)
valid_batch_size = cfg.DATASET.get('valid_batch_size', batch_size)
use_gradient_accumulation = cfg.get('GRADIENT_ACCUMULATION', None)
if use_gradient_accumulation and dist.get_world_size() >= 1:
global_batch_size = cfg.GRADIENT_ACCUMULATION.get(
'global_batch_size', None)
num_gpus = dist.get_world_size()
assert isinstance(
global_batch_size, int
), f"global_batch_size must be int, but got {type(global_batch_size)}"
assert batch_size < global_batch_size, f"global_batch_size must bigger than batch_size"
cur_global_batch_size = batch_size * num_gpus # The number of batches calculated by all GPUs at one time
assert global_batch_size % cur_global_batch_size == 0, \
f"The global batchsize must be divisible by cur_global_batch_size, but \
{global_batch_size} % {cur_global_batch_size} != 0"
cfg.GRADIENT_ACCUMULATION[
"num_iters"] = global_batch_size // cur_global_batch_size
# The number of iterations required to reach the global batchsize
logger.info(
f"Using gradient accumulation training strategy, "
f"global_batch_size={global_batch_size}, "
f"num_gpus={num_gpus}, "
f"num_accumulative_iters={cfg.GRADIENT_ACCUMULATION.num_iters}")
places = paddle.set_device('gpu')
# default num worker: 0, which means no subprocess will be created
num_workers = cfg.DATASET.get('num_workers', 0)
valid_num_workers = cfg.DATASET.get('valid_num_workers', num_workers)
model_name = cfg.model_name
output_dir = cfg.get("output_dir", f"./output/{model_name}")
mkdir(output_dir)
# 1. Construct model
model = build_model(cfg.MODEL)
if parallel:
model = paddle.DataParallel(model)
if use_fleet:
model = paddle.distributed_model(model)
# 2. Construct dataset and dataloader
train_dataset = build_dataset((cfg.DATASET.train, cfg.PIPELINE.train))
train_dataloader_setting = dict(batch_size=batch_size,
num_workers=num_workers,
collate_fn_cfg=cfg.get('MIX', None),
places=places)
train_loader = build_dataloader(train_dataset, **train_dataloader_setting)
if validate:
valid_dataset = build_dataset((cfg.DATASET.valid, cfg.PIPELINE.valid))
validate_dataloader_setting = dict(
batch_size=valid_batch_size,
num_workers=valid_num_workers,
places=places,
drop_last=False,
shuffle=cfg.DATASET.get(
'shuffle_valid',
False) #NOTE: attention lstm need shuffle valid data.
)
valid_loader = build_dataloader(valid_dataset,
**validate_dataloader_setting)
# 3. Construct solver.
if cfg.OPTIMIZER.learning_rate.get('iter_step'):
lr = build_lr(cfg.OPTIMIZER.learning_rate, len(train_loader))
else:
lr = build_lr(cfg.OPTIMIZER.learning_rate, 1)
optimizer = build_optimizer(cfg.OPTIMIZER,
lr,
parameter_list=model.parameters())
if use_fleet:
optimizer = fleet.distributed_optimizer(optimizer)
# Resume
resume_epoch = cfg.get("resume_epoch", 0)
if resume_epoch:
filename = osp.join(output_dir,
model_name + f"_epoch_{resume_epoch:05d}")
resume_model_dict = load(filename + '.pdparams')
resume_opt_dict = load(filename + '.pdopt')
model.set_state_dict(resume_model_dict)
optimizer.set_state_dict(resume_opt_dict)
# Finetune:
if weights:
assert resume_epoch == 0, f"Conflict occurs when finetuning, please switch resume function off by setting resume_epoch to 0 or not indicating it."
model_dict = load(weights)
model.set_state_dict(model_dict)
# 4. Train Model
###AMP###
if amp:
scaler = paddle.amp.GradScaler(init_loss_scaling=2.0**16,
incr_every_n_steps=2000,
decr_every_n_nan_or_inf=1)
best = 0.
for epoch in range(0, cfg.epochs):
if epoch < resume_epoch:
logger.info(
f"| epoch: [{epoch+1}] <= resume_epoch: [{ resume_epoch}], continue... "
)
continue
model.train()
record_list = build_record(cfg.MODEL)
tic = time.time()
for i, data in enumerate(train_loader):
record_list['reader_time'].update(time.time() - tic)
# 4.1 forward
###AMP###
if amp:
with paddle.amp.auto_cast(custom_black_list={"reduce_mean"}):
outputs = model(data, mode='train')
avg_loss = outputs['loss']
scaled = scaler.scale(avg_loss)
scaled.backward()
# keep prior to 2.0 design
scaler.minimize(optimizer, scaled)
optimizer.clear_grad()
else:
outputs = model(data, mode='train')
# 4.2 backward
if use_gradient_accumulation and i == 0: # Use gradient accumulation strategy
optimizer.clear_grad()
avg_loss = outputs['loss']
avg_loss.backward()
# 4.3 minimize
if use_gradient_accumulation: # Use gradient accumulation strategy
if (i + 1) % cfg.GRADIENT_ACCUMULATION.num_iters == 0:
for p in model.parameters():
p.grad.set_value(
p.grad / cfg.GRADIENT_ACCUMULATION.num_iters)
optimizer.step()
optimizer.clear_grad()
else: # Common case
optimizer.step()
optimizer.clear_grad()
# log record
record_list['lr'].update(optimizer.get_lr(), batch_size)
for name, value in outputs.items():
record_list[name].update(value, batch_size)
record_list['batch_time'].update(time.time() - tic)
tic = time.time()
if i % cfg.get("log_interval", 10) == 0:
ips = "ips: {:.5f} instance/sec.".format(
batch_size / record_list["batch_time"].val)
log_batch(record_list, i, epoch + 1, cfg.epochs, "train", ips)
# learning rate iter step
if cfg.OPTIMIZER.learning_rate.get("iter_step"):
lr.step()
# learning rate epoch step
if not cfg.OPTIMIZER.learning_rate.get("iter_step"):
lr.step()
ips = "avg_ips: {:.5f} instance/sec.".format(
batch_size * record_list["batch_time"].count /
record_list["batch_time"].sum)
log_epoch(record_list, epoch + 1, "train", ips)
def evaluate(best):
model.eval()
record_list = build_record(cfg.MODEL)
record_list.pop('lr')
tic = time.time()
for i, data in enumerate(valid_loader):
outputs = model(data, mode='valid')
# log_record
for name, value in outputs.items():
record_list[name].update(value, batch_size)
record_list['batch_time'].update(time.time() - tic)
tic = time.time()
if i % cfg.get("log_interval", 10) == 0:
ips = "ips: {:.5f} instance/sec.".format(
batch_size / record_list["batch_time"].val)
log_batch(record_list, i, epoch + 1, cfg.epochs, "val", ips)
ips = "avg_ips: {:.5f} instance/sec.".format(
batch_size * record_list["batch_time"].count /
record_list["batch_time"].sum)
log_epoch(record_list, epoch + 1, "val", ips)
best_flag = False
for top_flag in ['hit_at_one', 'top1']:
if record_list.get(
top_flag) and record_list[top_flag].avg > best:
best = record_list[top_flag].avg
best_flag = True
return best, best_flag
# use precise bn to improve acc
if cfg.get("PRECISEBN") and (epoch % cfg.PRECISEBN.preciseBN_interval
== 0 or epoch == cfg.epochs - 1):
do_preciseBN(
model, train_loader, parallel,
min(cfg.PRECISEBN.num_iters_preciseBN, len(train_loader)))
# 5. Validation
if validate and (epoch % cfg.get("val_interval", 1) == 0
or epoch == cfg.epochs - 1):
with paddle.no_grad():
best, save_best_flag = evaluate(best)
# save best
if save_best_flag:
save(optimizer.state_dict(),
osp.join(output_dir, model_name + '_' + str(int(best *10000)/10000) + "_best.pdopt"))
save(model.state_dict(),
osp.join(output_dir, model_name + '_' + str(int(best *10000)/10000) + "_best.pdparams"))
os.makedirs('./model', exist_ok=True)
save(model.state_dict(),
osp.join('./model', model_name + ".pdparams"))
if model_name == "AttentionLstm":
logger.info(
f"Already save the best model (hit_at_one){best}")
else:
logger.info(
f"Already save the best model (top1 acc){int(best *10000)/10000}"
)
# 6. Save model and optimizer
if epoch % cfg.get("save_interval", 1) == 0 or epoch == cfg.epochs - 1:
save(
optimizer.state_dict(),
osp.join(output_dir,
model_name + f"_epoch_{epoch+1:05d}.pdopt"))
save(
model.state_dict(),
osp.join(output_dir,
model_name + f"_epoch_{epoch+1:05d}.pdparams"))
logger.info(f'training {model_name} finished')
测试脚本 test.py
路径:work/PaddleVideo/paddlevideo/tasks/test.py
import paddle
from paddlevideo.utils import get_logger
from ..loader.builder import build_dataloader, build_dataset
from ..metrics import build_metric
from ..modeling.builder import build_model
from paddlevideo.utils import load
import numpy as np
import os
import paddle.nn.functional as F
logger = get_logger("paddlevideo")
@paddle.no_grad()
def test_model(cfg, weights, parallel=True):
"""Test model entry
Args:
cfg (dict): configuration.
weights (str): weights path to load.
parallel (bool): Whether to do multi-cards testing. Default: True.
"""
# 1. Construct model.
if cfg.MODEL.backbone.get('pretrained'):
cfg.MODEL.backbone.pretrained = '' # disable pretrain model init
model = build_model(cfg.MODEL)
if parallel:
model = paddle.DataParallel(model)
# 2. Construct dataset and dataloader.
cfg.DATASET.test.test_mode = True
dataset = build_dataset((cfg.DATASET.test, cfg.PIPELINE.test))
batch_size = cfg.DATASET.get("test_batch_size", 8)
places = paddle.set_device('gpu')
# default num worker: 0, which means no subprocess will be created
num_workers = cfg.DATASET.get('num_workers', 0)
num_workers = cfg.DATASET.get('test_num_workers', num_workers)
dataloader_setting = dict(batch_size=batch_size,
num_workers=num_workers,
places=places,
drop_last=False,
shuffle=False)
data_loader = build_dataloader(dataset, **dataloader_setting)
model.eval()
state_dicts = load(weights)
model.set_state_dict(state_dicts)
# add params to metrics
cfg.METRIC.data_size = len(dataset)
cfg.METRIC.batch_size = batch_size
print('{} inference start!!!'.format(cfg.model_name))
Metric = build_metric(cfg.METRIC)
ans = np.zeros((len(data_loader), 30))
for batch_id, data in enumerate(data_loader):
outputs = model(data, mode='test')
ans[batch_id, :] = outputs
Metric.update(batch_id, data, outputs)
os.makedirs('logits', exist_ok=True)
with open('logits/{}.npy'.format(cfg.model_name), 'wb') as f:
np.save(f, ans)
print('{} inference finished!!!'.format(cfg.model_name))
Metric.accumulate()
MODEL:
framework: "RecognizerGCN"
backbone:
name: "CTRGCN"
in_channels: 9
配置文件 – MODEL
接下来是由配置文件中的配置引发的各种源码。
MODEL:
framework: "RecognizerGCN"
backbone:
name: "CTRGCN"
in_channels: 2
head:
name: "CTRGCNHead"
num_classes: 30
ls_eps: 0.1
RecognizerGCN
from ...registry import RECOGNIZERS
from .base import BaseRecognizer
from paddlevideo.utils import get_logger
logger = get_logger("paddlevideo")
@RECOGNIZERS.register()
class RecognizerGCN(BaseRecognizer):
"""GCN Recognizer model framework.
"""
def forward_net(self, data):
"""Define how the model is going to run, from input to output.
"""
feature = self.backbone(data)
cls_score = self.head(feature)
return cls_score
def train_step(self, data_batch):
"""Training step.
"""
data = data_batch[0]
label = data_batch[1:]
# call forward
cls_score = self.forward_net(data)
loss_metrics = self.head.loss(cls_score, label)
return loss_metrics
def val_step(self, data_batch):
"""Validating setp.
"""
data = data_batch[0]
label = data_batch[1:]
# call forward
cls_score = self.forward_net(data)
loss_metrics = self.head.loss(cls_score, label, valid_mode=True)
return loss_metrics
def test_step(self, data_batch):
"""Test step.
"""
data = data_batch[0]
# call forward
cls_score = self.forward_net(data)
return cls_score
def infer_step(self, data_batch):
"""Infer step.
"""
data = data_batch[0]
# call forward
cls_score = self.forward_net(data)
return cls_score
这段代码定义了名为 RecognizerGCN 的类,该类继承自 BaseRecognizer 类,并使用装饰器 @RECOGNIZERS.register() 将其注册为一种视频识别模型。
在该类中,包含了模型的前向计算函数 forward_net() 和训练、验证、测试、推理等步骤。具体来说:
- forward_net 方法接收一个数据张量作为输入,将其通过 backbone 模块提取特征,然后通过 head 模块得到分类得分。
- train_step 方法接收一个数据批次,包含数据张量和标签张量,调用 forward_net 方法得到分类得分,然后调用 head 模块的 loss 方法计算损失指标。
- val_step 方法与 train_step 方法类似,但是在调用 head 模块的 loss 方法时,设置 valid_mode=True 参数,表示在验证模式下计算损失指标。
- test_step 方法接收一个数据批次,只包含数据张量,调用 forward_net 方法得到分类得分,然后返回分类得分。
- infer_step 方法定义了模型的推理步骤,与 test_step 方法基本相同,但不需要返回预测结果的置信度。
from paddlevideo.utils import get_logger
logger = get_logger("paddlevideo")
logger = get_logger("paddlevideo") 这行代码定义了一个名为 logger 的日志对象,并使用 get_logger() 函数对其进行初始化。该函数的参数是一个字符串 “paddlevideo”,表示日志对象的名称。
在 Python 中,可以通过 logging 模块来打印日志信息。
- get_logger() 函数是 paddlevideo.utils 包中的一个工具函数,用于获取和配置一个 logger,使得我们能够在程序中输出日志信息。
- 通过 logger 对象可以调用相应的方法(例如 logger.info()),来实现在程序中打印对应级别的日志信息,便于开发者查看和排查问题。
CTRGCN
以下是 PaddleVideo 中 ctrgcn.py 的代码,代码详解见:CTR-GCN 代码理解
import math
from ..registry import BACKBONES
import numpy as np
import paddle
import paddle.nn as nn
from .graph_ctrgcn import Graph
def _calculate_fan_in_and_fan_out(tensor):
dimensions = tensor.ndim
if dimensions < 2:
raise ValueError("Fan in and fan out can not be computed for tensor with fewer than 2 dimensions")
num_input_fmaps = tensor.shape[1]
num_output_fmaps = tensor.shape[0]
receptive_field_size = 1
if tensor.ndim > 2:
for s in tensor.shape[2:]:
receptive_field_size *= s
fan_in = num_input_fmaps * receptive_field_size
fan_out = num_output_fmaps * receptive_field_size
return fan_in, fan_out
def _calculate_correct_fan(tensor, mode):
mode = mode.lower()
valid_modes = ['fan_in', 'fan_out']
if mode not in valid_modes:
raise ValueError("Mode {} not supported, please use one of {}".format(mode, valid_modes))
fan_in, fan_out = _calculate_fan_in_and_fan_out(tensor)
return fan_in if mode == 'fan_in' else fan_out
def kaiming_normal_(tensor, a=0, mode='fan_out', nonlinearity='leaky_relu'):
fan = _calculate_correct_fan(tensor, mode)
gain = math.sqrt(2.0)
std = gain / math.sqrt(fan)
with paddle.no_grad():
return nn.initializer.Normal(0.0, std)
def einsum(x, A): #'ncuv,nctv->nctu'
x = x.transpose((0, 1, 3, 2))
y = paddle.matmul(A, x)
return y
def conv_branch_init(conv, branches):
weight = conv.weight
n = weight.shape[0]
k1 = weight.shape[1]
k2 = weight.shape[2]
nn.init.normal_(weight, 0, math.sqrt(2. / (n * k1 * k2 * branches)))
nn.init.constant_(conv.bias, 0)
def conv_init(conv):
if conv.weight is not None:
kaiming_normal_(conv.weight, mode='fan_out')(conv.weight)
if conv.bias is not None:
nn.initializer.Constant(0)(conv.bias)
def bn_init(bn, scale):
nn.initializer.Constant(scale)(bn.weight)
nn.initializer.Constant(0)(bn.bias)
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
if hasattr(m, 'weight'):
kaiming_normal_(m.weight, mode='fan_out')(m.weight)
if hasattr(m, 'bias') and m.bias is not None:
nn.initializer.Constant(0)(m.bias)
elif classname.find('BatchNorm') != -1:
if hasattr(m, 'weight') and m.weight is not None:
nn.initializer.Normal(1.0, 0.02)(m.weight)
if hasattr(m, 'bias') and m.bias is not None:
nn.initializer.Constant(0)(m.bias)
class TemporalConv(nn.Layer):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, dilation=1):
super(TemporalConv, self).__init__()
pad = (kernel_size + (kernel_size-1) * (dilation-1) - 1) // 2
self.conv = nn.Conv2D(
in_channels,
out_channels,
kernel_size=(kernel_size, 1),
padding=(pad, 0),
stride=(stride, 1),
dilation=(dilation, 1))
self.bn = nn.BatchNorm2D(out_channels)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
return x
class MultiScale_TemporalConv(nn.Layer):
def __init__(self,
in_channels,
out_channels,
kernel_size=3,
stride=1,
dilations=[1,2,3,4],
residual=True,
residual_kernel_size=1):
super().__init__()
assert out_channels % (len(dilations) + 2) == 0, '# out channels should be multiples of # branches'
# Multiple branches of temporal convolution
self.num_branches = len(dilations) + 2
branch_channels = out_channels // self.num_branches
if type(kernel_size) == list:
assert len(kernel_size) == len(dilations)
else:
kernel_size = [kernel_size]*len(dilations)
# Temporal Convolution branches
self.branches = nn.LayerList([
nn.Sequential(
nn.Conv2D(
in_channels,
branch_channels,
kernel_size=1,
padding=0),
nn.BatchNorm2D(branch_channels),
nn.ReLU(),
TemporalConv(
branch_channels,
branch_channels,
kernel_size=ks,
stride=stride,
dilation=dilation),
)
for ks, dilation in zip(kernel_size, dilations)
])
# Additional Max & 1x1 branch
self.branches.append(nn.Sequential(
nn.Conv2D(in_channels, branch_channels, kernel_size=1, padding=0),
nn.BatchNorm2D(branch_channels),
nn.ReLU(),
nn.MaxPool2D(kernel_size=(3,1), stride=(stride,1), padding=(1,0)),
nn.BatchNorm2D(branch_channels) # 为什么还要加bn
))
self.branches.append(nn.Sequential(
nn.Conv2D(in_channels, branch_channels, kernel_size=1, padding=0, stride=(stride,1)),
nn.BatchNorm2D(branch_channels)
))
# Residual connection
if not residual:
self.residual = lambda x: 0
elif (in_channels == out_channels) and (stride == 1):
self.residual = lambda x: x
else:
self.residual = TemporalConv(in_channels, out_channels, kernel_size=residual_kernel_size, stride=stride)
# initialize
self.apply(weights_init)
def forward(self, x):
# Input dim: (N,C,T,V)
res = self.residual(x)
branch_outs = []
for tempconv in self.branches:
out = tempconv(x)
branch_outs.append(out)
out = paddle.concat(branch_outs, axis=1)
out += res
return out
class CTRGC(nn.Layer):
def __init__(self, in_channels, out_channels, rel_reduction=8, mid_reduction=1):
super(CTRGC, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
if in_channels <= 16:
self.rel_channels = 8
self.mid_channels = 16
else:
self.rel_channels = in_channels // rel_reduction
self.mid_channels = in_channels // mid_reduction
self.conv1 = nn.Conv2D(self.in_channels, self.rel_channels, kernel_size=1)
self.conv2 = nn.Conv2D(self.in_channels, self.rel_channels, kernel_size=1)
self.conv3 = nn.Conv2D(self.in_channels, self.out_channels, kernel_size=1)
self.conv4 = nn.Conv2D(self.rel_channels, self.out_channels, kernel_size=1)
self.tanh = nn.Tanh()
for m in self.sublayers():
if isinstance(m, nn.Conv2D):
conv_init(m)
elif isinstance(m, nn.BatchNorm2D):
bn_init(m, 1)
def forward(self, x, A=None, alpha=1):
x1, x2, x3 = self.conv1(x).mean(-2), self.conv2(x).mean(-2), self.conv3(x)
x1 = self.tanh(x1.unsqueeze(-1) - x2.unsqueeze(-2))
x1 = self.conv4(x1) * alpha + (A.unsqueeze(0).unsqueeze(0) if A is not None else 0) # N,C,V,V
x1 = einsum(x1, x3)
return x1
class unit_tcn(nn.Layer):
def __init__(self, in_channels, out_channels, kernel_size=9, stride=1):
super(unit_tcn, self).__init__()
pad = int((kernel_size - 1) / 2)
self.conv = nn.Conv2D(in_channels, out_channels, kernel_size=(kernel_size, 1), padding=(pad, 0),
stride=(stride, 1))
self.bn = nn.BatchNorm2D(out_channels)
self.relu = nn.ReLU()
conv_init(self.conv)
bn_init(self.bn, 1)
def forward(self, x):
x = self.bn(self.conv(x))
return x
class unit_gcn(nn.Layer):
def __init__(self, in_channels, out_channels, A, coff_embedding=4, adaptive=True, residual=True):
super(unit_gcn, self).__init__()
inter_channels = out_channels // coff_embedding
self.inter_c = inter_channels
self.out_c = out_channels
self.in_c = in_channels
self.adaptive = adaptive
self.num_subset = A.shape[0]
self.convs = nn.LayerList()
for i in range(self.num_subset):
self.convs.append(CTRGC(in_channels, out_channels))
if residual:
if in_channels != out_channels:
self.down = nn.Sequential(
nn.Conv2D(in_channels, out_channels, 1),
nn.BatchNorm2D(out_channels)
)
else:
self.down = lambda x: x
else:
self.down = lambda x: 0
if self.adaptive:
self.PA = paddle.static.create_parameter(A.shape, 'float32', default_initializer=nn.initializer.Assign(paddle.to_tensor(A.astype(np.float32), stop_gradient=False)))
else:
self.A = paddle.to_tensor(A.astype(np.float32), stop_gradient=True)
self.alpha = paddle.static.create_parameter([1], 'float32', default_initializer=nn.initializer.Assign(paddle.to_tensor(paddle.zeros(shape=[1]), stop_gradient=False)))
self.bn = nn.BatchNorm2D(out_channels)
self.soft = nn.Softmax(axis=-2)
self.relu = nn.ReLU()
for m in self.sublayers():
if isinstance(m, nn.Conv2D):
conv_init(m)
elif isinstance(m, nn.BatchNorm2D):
bn_init(m, 1)
bn_init(self.bn, 1e-6)
def forward(self, x):
y = None
if self.adaptive:
A = self.PA
else:
A = self.A
for i in range(self.num_subset):
z = self.convs[i](x, A[i], self.alpha)
y = z + y if y is not None else z
y = self.bn(y)
y += self.down(x)
y = self.relu(y)
return y
class TCN_GCN_unit(nn.Layer):
def __init__(self, in_channels, out_channels, A, stride=1, residual=True, adaptive=True, kernel_size=5, dilations=[1,2]):
super(TCN_GCN_unit, self).__init__()
self.gcn1 = unit_gcn(in_channels, out_channels, A, adaptive=adaptive)
self.tcn1 = MultiScale_TemporalConv(out_channels, out_channels, kernel_size=kernel_size, stride=stride, dilations=dilations,
residual=False)
self.relu = nn.ReLU()
if not residual:
self.residual = lambda x: 0
elif (in_channels == out_channels) and (stride == 1):
self.residual = lambda x: x
else:
self.residual = unit_tcn(in_channels, out_channels, kernel_size=1, stride=stride)
def forward(self, x):
y = self.relu(self.tcn1(self.gcn1(x)) + self.residual(x))
return y
@BACKBONES.register()
class CTRGCN(nn.Layer):
def __init__(self, in_channels=2, num_class=30, num_point=25, num_person=1, drop_out=0, adaptive=True):
super(CTRGCN, self).__init__()
self.graph = Graph()
A = self.graph.A # 3,25,25
self.num_class = num_class
self.num_point = num_point
self.data_bn = nn.BatchNorm1D(num_person * in_channels * num_point)
base_channel = 64
self.l1 = TCN_GCN_unit(in_channels, base_channel, A, residual=False, adaptive=adaptive)
self.l2 = TCN_GCN_unit(base_channel, base_channel, A, adaptive=adaptive)
self.l3 = TCN_GCN_unit(base_channel, base_channel, A, adaptive=adaptive)
self.l4 = TCN_GCN_unit(base_channel, base_channel, A, adaptive=adaptive)
self.l5 = TCN_GCN_unit(base_channel, base_channel*2, A, stride=2, adaptive=adaptive)
self.l6 = TCN_GCN_unit(base_channel*2, base_channel*2, A, adaptive=adaptive)
self.l7 = TCN_GCN_unit(base_channel*2, base_channel*2, A, adaptive=adaptive)
self.l8 = TCN_GCN_unit(base_channel*2, base_channel*4, A, stride=2, adaptive=adaptive)
self.l9 = TCN_GCN_unit(base_channel*4, base_channel*4, A, adaptive=adaptive)
self.l10 = TCN_GCN_unit(base_channel*4, base_channel*4, A, adaptive=adaptive)
self.fc = nn.Linear(base_channel*4, num_class, weight_attr=nn.initializer.Normal(0, math.sqrt(2. / num_class)))
bn_init(self.data_bn, 1)
if drop_out:
self.drop_out = nn.Dropout(drop_out)
else:
self.drop_out = lambda x: x
def forward(self, x):
x.stop_gradient = False
if len(x.shape) == 3:
N, T, VC = x.shape
x = x.reshape((N, T, self.num_point, -1))
x = x.transpose((0, 3, 1, 2)).unsqueeze(-1)
N, C, T, V, M = x.shape
x = x.transpose((0, 4, 3, 1, 2))
x = x.reshape((N, M * V * C, T))
x = self.data_bn(x)
x = x.reshape((N, M, V, C, T))
x = x.transpose((0, 1, 3, 4, 2))
x = x.reshape((N * M, C, T, V))
x = self.l1(x)
x = self.l2(x)
x = self.l3(x)
x = self.l4(x)
x = self.l5(x)
x = self.l6(x)
x = self.l7(x)
x = self.l8(x)
x = self.l9(x)
x = self.l10(x)
# N*M,C,T,V
c_new = x.shape[1]
x = x.reshape((N, M, c_new, -1))
x = x.mean(3).mean(1)
x = self.drop_out(x)
return self.fc(x)
graph_ctrgcn.py
import numpy as np
from . import tools_ctrgcn
num_node = 25
self_link = [(i, i) for i in range(num_node)]
inward_ori_index = [(2, 1), (3, 2), (4, 3), (5, 1), (6, 5), (7, 6),
(1, 8), (9, 8), (10, 9), (11, 10), (24, 11), (22, 11), (23, 22),
(12, 8), (13, 12), (14, 13), (21, 14), (19, 14), (20, 19),
(0, 1), (17, 15), (15, 0), (16, 0), (18, 16)]
inward = [(i, j) for (i, j) in inward_ori_index]
outward = [(j, i) for (i, j) in inward]
neighbor = inward + outward
num_node_1 = 11
indices_1 = [8, 0, 6, 7, 3, 4, 13, 19, 10, 22, 1]
self_link_1 = [(i, i) for i in range(num_node_1)]
inward_ori_index_1 = [(1, 11), (2, 11), (3, 11), (4, 3), (5, 11), (6, 5), (7, 1), (8, 7), (9, 1), (10, 9)]
inward_1 = [(i - 1, j - 1) for (i, j) in inward_ori_index_1]
outward_1 = [(j, i) for (i, j) in inward_1]
neighbor_1 = inward_1 + outward_1
num_node_2 = 5
indices_2 = [3, 5, 6, 8, 10]
self_link_2 = [(i ,i) for i in range(num_node_2)]
inward_ori_index_2 = [(0, 4), (1, 4), (2, 4), (3, 4), (0, 1), (2, 3)]
inward_2 = [(i - 1, j - 1) for (i, j) in inward_ori_index_2]
outward_2 = [(j, i) for (i, j) in inward_2]
neighbor_2 = inward_2 + outward_2
class Graph:
def __init__(self, labeling_mode='spatial', scale=1):
self.num_node = num_node
self.self_link = self_link
self.inward = inward
self.outward = outward
self.neighbor = neighbor
self.A = self.get_adjacency_matrix(labeling_mode)
self.A1 = tools_ctrgcn.get_spatial_graph(num_node_1, self_link_1, inward_1, outward_1)
self.A2 = tools_ctrgcn.get_spatial_graph(num_node_2, self_link_2, inward_2, outward_2)
self.A_binary = tools_ctrgcn.edge2mat(neighbor, num_node)
self.A_norm = tools_ctrgcn.normalize_adjacency_matrix(self.A_binary + 2*np.eye(num_node))
self.A_binary_K = tools_ctrgcn.get_k_scale_graph(scale, self.A_binary)
self.A_A1 = ((self.A_binary + np.eye(num_node)) / np.sum(self.A_binary + np.eye(self.A_binary.shape[0]), axis=1, keepdims=True))[indices_1]
self.A1_A2 = tools_ctrgcn.edge2mat(neighbor_1, num_node_1) + np.eye(num_node_1)
self.A1_A2 = (self.A1_A2 / np.sum(self.A1_A2, axis=1, keepdims=True))[indices_2]
def get_adjacency_matrix(self, labeling_mode=None):
if labeling_mode is None:
return self.A
if labeling_mode == 'spatial':
A = tools_ctrgcn.get_spatial_graph(num_node, self_link, inward, outward)
else:
raise ValueError()
return A
tools_ctrgcn.py
import numpy as np
def get_sgp_mat(num_in, num_out, link):
A = np.zeros((num_in, num_out))
for i, j in link:
A[i, j] = 1
A_norm = A / np.sum(A, axis=0, keepdims=True)
return A_norm
def edge2mat(link, num_node):
A = np.zeros((num_node, num_node))
for i, j in link:
A[j, i] = 1
return A
def get_k_scale_graph(scale, A):
if scale == 1:
return A
An = np.zeros_like(A)
A_power = np.eye(A.shape[0])
for k in range(scale):
A_power = A_power @ A
An += A_power
An[An > 0] = 1
return An
def normalize_digraph(A):
Dl = np.sum(A, 0)
h, w = A.shape
Dn = np.zeros((w, w))
for i in range(w):
if Dl[i] > 0:
Dn[i, i] = Dl[i] ** (-1)
AD = np.dot(A, Dn)
return AD
def get_spatial_graph(num_node, self_link, inward, outward):
I = edge2mat(self_link, num_node)
In = normalize_digraph(edge2mat(inward, num_node))
Out = normalize_digraph(edge2mat(outward, num_node))
A = np.stack((I, In, Out))
return A
def normalize_adjacency_matrix(A):
node_degrees = A.sum(-1)
degs_inv_sqrt = np.power(node_degrees, -0.5)
norm_degs_matrix = np.eye(len(node_degrees)) * degs_inv_sqrt
return (norm_degs_matrix @ A @ norm_degs_matrix).astype(np.float32)
def k_adjacency(A, k, with_self=False, self_factor=1):
assert isinstance(A, np.ndarray)
I = np.eye(len(A), dtype=A.dtype)
if k == 0:
return I
Ak = np.minimum(np.linalg.matrix_power(A + I, k), 1) \
- np.minimum(np.linalg.matrix_power(A + I, k - 1), 1)
if with_self:
Ak += (self_factor * I)
return Ak
def get_multiscale_spatial_graph(num_node, self_link, inward, outward):
I = edge2mat(self_link, num_node)
A1 = edge2mat(inward, num_node)
A2 = edge2mat(outward, num_node)
A3 = k_adjacency(A1, 2)
A4 = k_adjacency(A2, 2)
A1 = normalize_digraph(A1)
A2 = normalize_digraph(A2)
A3 = normalize_digraph(A3)
A4 = normalize_digraph(A4)
A = np.stack((I, A1, A2, A3, A4))
return A
def get_uniform_graph(num_node, self_link, neighbor):
A = normalize_digraph(edge2mat(neighbor + self_link, num_node))
return A
CTRGCNHead
以下是 ctrgcn_head.py 的源代码:
import paddle
import paddle.nn as nn
from .base import BaseHead
from ..registry import HEADS
from ..weight_init import weight_init_
@HEADS.register()
class CTRGCNHead(BaseHead):
"""
Head for ST-GCN model.
Args:
in_channels: int, input feature channels. Default: 256.
num_classes: int, number classes. Default: 10.
"""
def __init__(self, in_channels=256, num_classes=10, **kwargs):
super().__init__(num_classes, in_channels, **kwargs)
def forward(self, x):
"""Define how the head is going to run.
"""
return x