文章目录
- @[TOC](文章目录)
- 前言
- 一、什么是列式数据库?
- 为什么要用列式数据库,优点是什么?
- 二、clickhouse入门
- 1. 个人猜想
- 2. 使用clickhouse
- 引入依赖
- yml配置
- 扫描mapper
- 2.生成相应代码,执行测试用例
- 查询结果
- 总结
文章目录
- @[TOC](文章目录)
- 前言
- 一、什么是列式数据库?
- 为什么要用列式数据库,优点是什么?
- 二、clickhouse入门
- 1. 个人猜想
- 2. 使用clickhouse
- 引入依赖
- yml配置
- 扫描mapper
- 2.生成相应代码,执行测试用例
- 查询结果
- 总结
前言
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
一、什么是列式数据库?
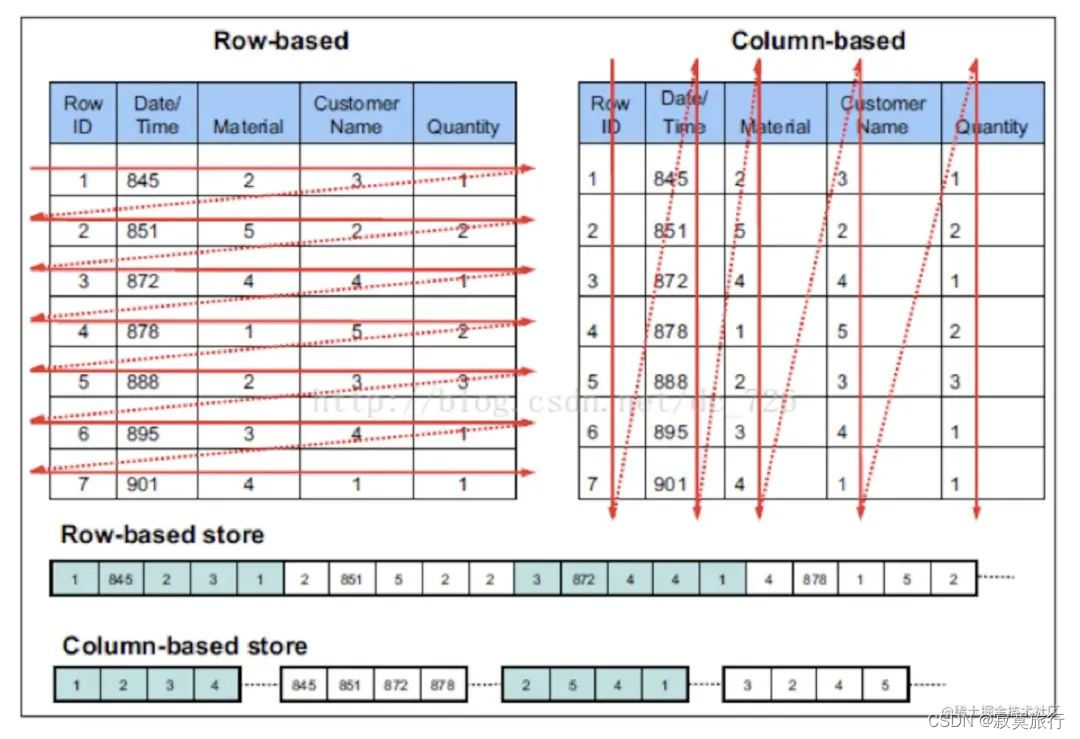
什么事列式数据库,顾名思义它与平时的主流关系型数据库不太一致,例如mysql 它是行式数据库,什么意思呢?
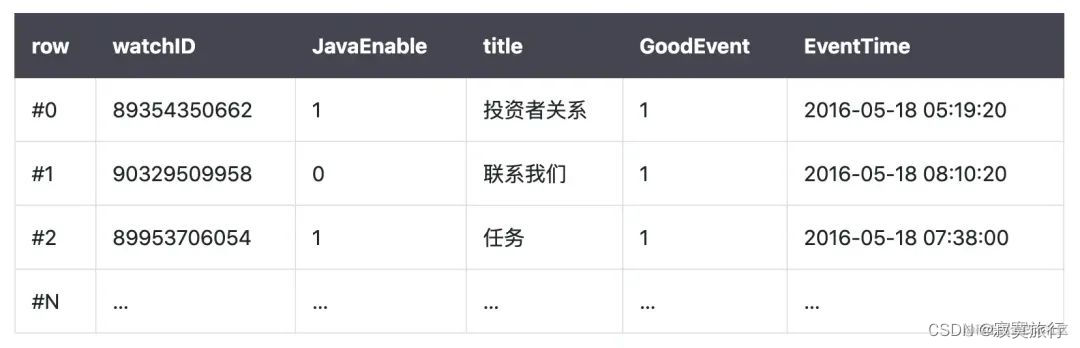
这就是普通的行式数据库的存储,一行是一条完整的数据;
接下来看看列式数据库
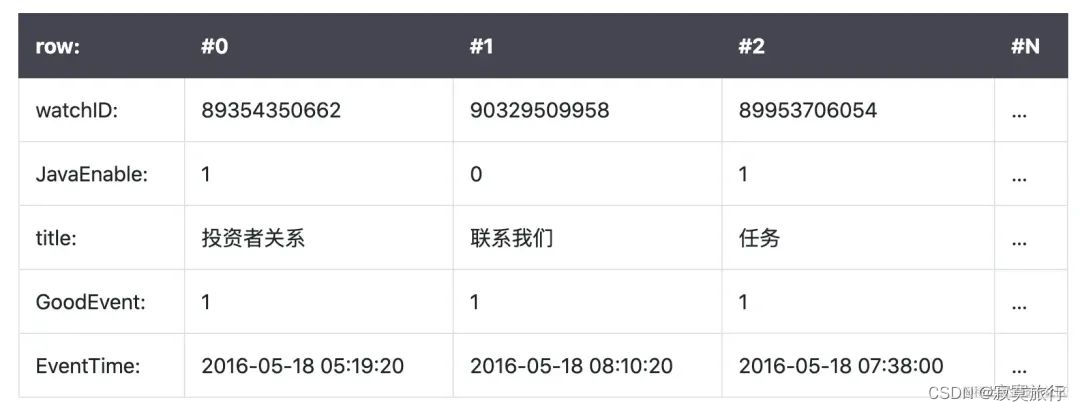
一列是一条完整的数据; 每一行则是同类型的数据;
这就意味着查询的时候, 和存入的时候与传统的行式数据库都不太一致
为什么要用列式数据库,优点是什么?
- 列式数据库的存储方式更节省空间
它的存储与传统行式数据库一样,也是以每一行为一个单元进行存储的,由于每一行作为一个存储单元,每一行的数据类型必定一致,这样对于数据存储的压缩更有利
- 列式数据库查询字段更少,性能更佳
例如行式数据库,我要查询所有人的年龄,那么我需要扫描全表,然后取每一条的一个属性age,相当于全表扫描,但是有用的属性只有一个,造成了查询效率低下; 列式数据库呢? 只需要取出age属性所在的某一行数据,取到的就都是属性age的值; 所以当有数据统计 如: 聚合 统计的时候,列式存储性能更佳
二、clickhouse入门
1. 个人猜想
既然是列式数据库,那么它的存储与查询肯定也与行式的不太一样
- 1 存储
当传入传统的一行数据后, 会对这条数据的字段进行拆分,拆分后,每个字段存入各自的列式数据库中的行,但是他们虽然拆分,但是在所有行中,列号相同
- 2 查询
当想查询一条传统的一行数据, 会根据条件查询需要的字段
既列式数据库的要查询行的所有数据,然后按照条件过滤,得到相应的列式中的行数据,然后根据行所在的列号,找到其他行,然后拼接成一条条数据
这样就变为了传统数据上的一行行数据,返回结果
2. 使用clickhouse
- 来吧,展示~~
- 搞一个springboot项目
- 引入依赖,由于clickhouse springboot没有相应的封装,所以这里采用 springboot的 dynamic-datasource 搞
- 切记不可以用springboot的jdbc,他与clickhouse-jdbc 冲突
- 引入mybatis-plus 然后尝试操作数据库
引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>ru.yandex.clickhouse</groupId>
<artifactId>clickhouse-jdbc</artifactId>
<version>0.3.2</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.1.0</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>dynamic-datasource-spring-boot-starter</artifactId>
<version>3.6.1</version>
<scope>runtime</scope>
</dependency>
yml配置
spring:
datasource:
dynamic:
primary: master
strict: false
datasource:
master:
driver-class-name: com.clickhouse.jdbc.ClickHouseDriver
username: default
password:
url: jdbc:clickhouse://ip:8123/数据库名
扫描mapper
启动类增加扫描
@MapperScan("com.example.clickhousedemo.dao")
2.生成相应代码,执行测试用例
测试用例代码:
@SpringBootTest
class ClickhouseDemoApplicationTests {
@Autowired
MoniterCpuService moniterCpuService;
@Test
void contextLoads() throws Exception{
List<MoniterCpu> list = moniterCpuService.list();
for (MoniterCpu moniterCpu : list) {
// 类内部重新了toString 方法
System.out.println(moniterCpu.toString());
}
}
}
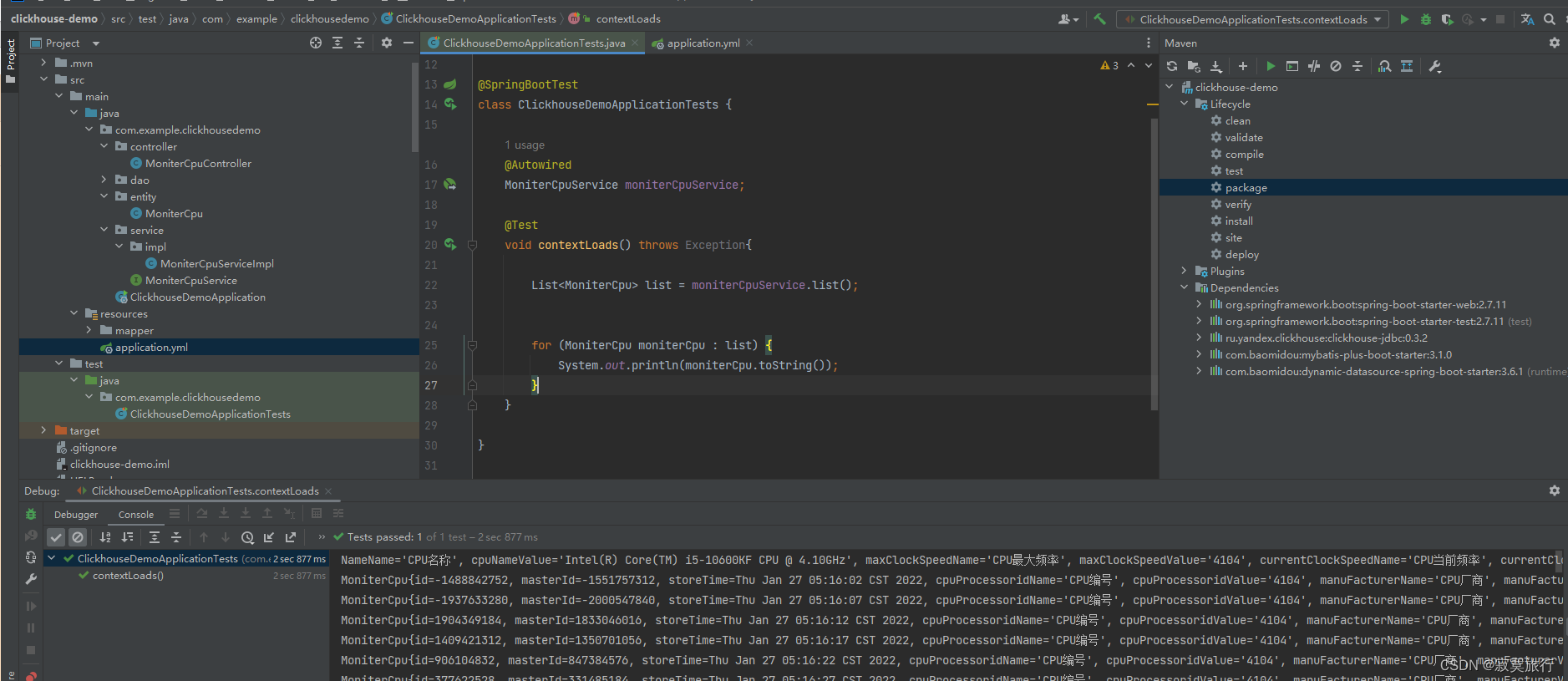
总结
clickhouse 在使用上,与mysql几乎没有差别,遵循sql92标准,某些函数会有不同,然后体验它优越的性能就好了~~
文章中涉及到的所有源码: 项目地址


![[入门必看]数据结构5.2:二叉树的概念](https://img-blog.csdnimg.cn/c718c09bcae846cf9c9419bd15f73dd8.png#pic_center)