AI模型的发展速度令人惊讶,几乎每天都会有新的模型发布。而2023年4月中旬也有很多新的模型发布,我们挑出几个重点给大家介绍一下。

-
Dolly-v2
-
MiniGPT-4
-
LLaVA
-
DINOv2
Dolly-v2
Dolly是EleutherAI开源的一系列大语言模型,EleutherAI认为大语言模型应该被所有人共享,并为大多数人提供服务,因此他们开启了大语言模型开源计划。Dolly系列就是他们开源的成果。Dolly 1.0在2023年3月24日发布,而过了还不到一个月时间,Dolly 2.0就发布了。
Dolly 2.0是一个基于Pythia微调的语言模型,Pythia是EleutherAI开源的语言模型,共8个版本,最大的参数120亿(Pythia模型卡信息:https://www.datalearner.com/ai-models/pretrained-models/Pythia )。而Dolly 2.0就是在120亿参数版本上微调得到的。
需要注意的是,Dolly 2.0专门在一个新的高质量人类生成的指令跟踪数据集上进行微调(即databricks-dolly-15k,它包含了15,000个高质量的人类生成的提示/响应对,专门用于调整大型语言模型的指令。),这些数据集是由Databricks员工众包生成的。因此,它在理解人类意图上表现很好。
Dolly 1.0是基于斯坦福Alpaca进行微调的,训练成本为30美元。但是因为Alpaca禁止商业使用,所有Dolly2.0改成了Pythia基础上进行微调,而pythia允许商业使用。
我们认为Dolly 2.0最大的贡献是允许商业使用!它的代码到模型到数据集均开源!
Dolly 1.0模型卡地址:
https://www.datalearner.com/ai/pretrained-models/Dolly
Dolly 2.0模型卡地址:
https://www.datalearner.com/ai/pretrained-models/dolly-v2
MiniGPT-4
MiniGPT-4是一个低成本的多模态预训练模型,用了4个A100,10个小时左右训练完成的。基于前段时间开源的Vacuna模型和BLIP-2结合得到。先用500万个文本-图像数据训练,然后再用3500个高质量的数据微调,一下就让语言模型有了理解图像的能力。

从测试结果看,MiniGPT-4在理解图像上有着很不错的效果。而这种低成本的将语言模型能力扩展到对图像的理解,十分值得继续关注。
研究发现,MiniGPT-4具有许多与GPT-4类似的功能,比如生成详细的图像描述和从手写草稿创建网站。MiniGPT-4还有其他新兴功能,包括根据给定的图像撰写故事和诗歌,提供解决图像中显示的问题的方法,以及基于食品照片教用户如何烹饪等。
MiniGPT-4模型卡地址:
https://www.datalearner.com/ai/pretrained-models/MiniGPT-4
LLaVA
LLaVA全称Large Language and Vision Assistant,是由微软与威斯康星大学麦迪逊分校教授一起提出的一个多模态大模型。
LLaVA将预训练的CLIP VIT-L/14作为encoder,然后和MetaAI开源的LLaMA连接。
与MiniGPT-4不同的是,这个模型主要是把instruction-tuning放到了多模态模型上,这是将指令调整扩展到多模态空间的第一次尝试,使用ChatGPT/GPT-4将图像-文本对转换为适当的指令跟随格式。将CLIP视觉编码器与语言解码器LLaMA连接起来,并进行端到端微调。最终效果也是很不错。
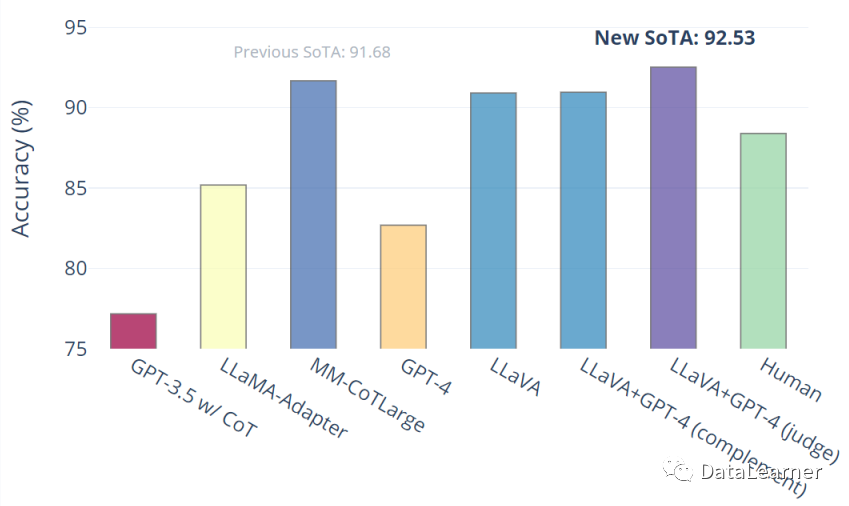
将instruction-tuning能力运用到语言模型的图像理解上是一个值得关注的思路,可能是多模态模型的一个重要的微调方向。
LLaVA模型卡地址:
https://www.datalearner.com/ai-models/pretrained-models/LLaVA
DINOv2
DINOv2是MetaAI最新开源的计算机视觉领域的预训练大模型。相比较DINO的第一个版本,作者做了很多的修改,使得v2版本的DINO模型性能更加强大。
2021年4月30日,MetaAI公开了DINO算法,DINO的核心思想是在无需标注数据的情况下,学习图像的有意义表示。通过自监督学习,DINO可以从大量未标注的图像中提取视觉特征,这些特征对于各种下游计算机视觉任务非常有用,例如图像分类、物体检测和语义分割。时隔一年后的2022年4月8日,MetaAI开源了DINO的实现代码和预训练结果。
一年之后的2023年4月17日,MetaAI开源DINOv2版本。相比较原始的DINO模型,DINOv2能够对视频进行处理,生成比原始DINO方法更高质量的分割结果。DINOv2能够呈现出非凡的特性,例如对物体部分的强大理解,以及对图像的鲁棒语义和低级理解。

相比较之前的模型,它的性能更好,而且比基于text-image的预训练模型也好很多,不过因为是纯CV领域的预训练结果(1.40亿图像数据集),它主要抽取的是基础特征。但是可以用这个特征做图片分类、图像分割、深度估计等,模型开源,11亿参数版本也就4.2G。
DINOv2模型卡地址:
https://www.datalearner.com/ai-models/pretrained-models/DINOv2