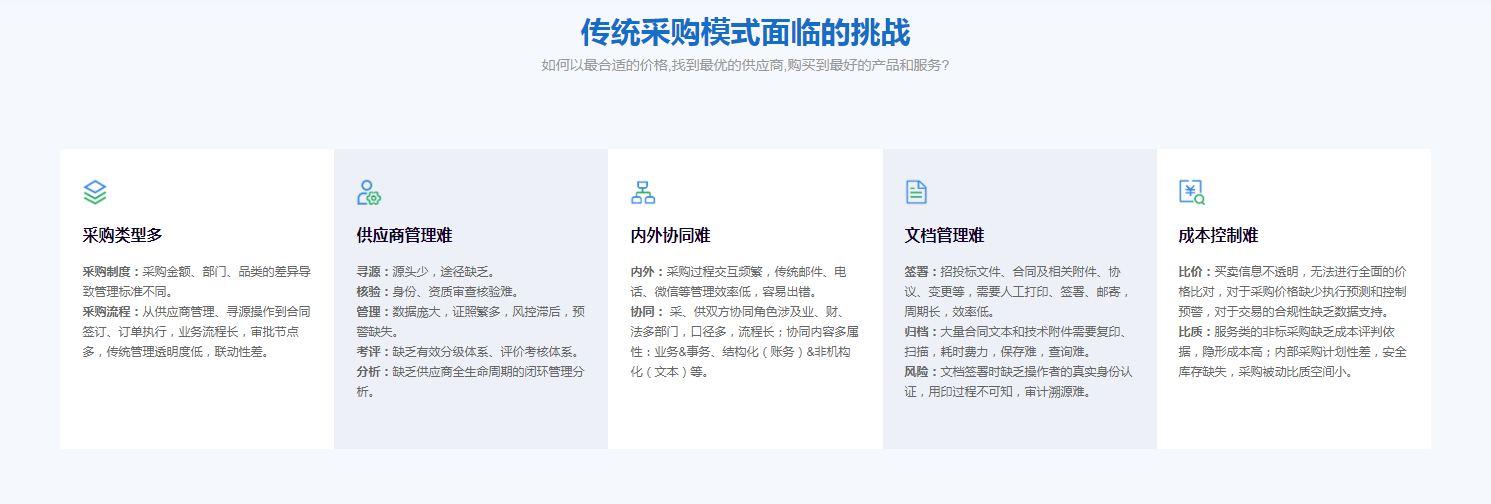
文本挖掘流程:(How)
文本预处理->特征提取->文本分析->可视化展示
文本预处理:包括文本清洗、分词、词性标注等
特征提取:将文本转化为词频、TF-IDF、embedding向量等
文本分析:利用统计学或机器学习的知识,做聚类、情感识别等
可视化展示:帮助人们更好的理解挖掘结构
自然语言处理任务 (Why)
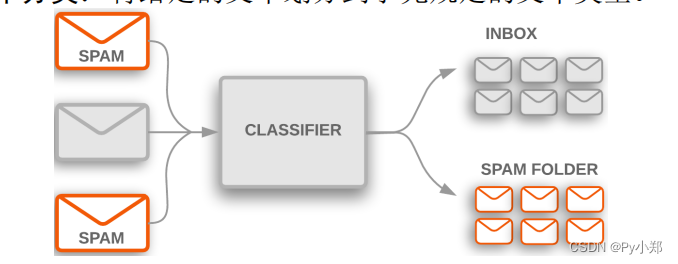
文本分类:将文本区分到事先设定好的类型(垃圾邮件还是正常邮件)
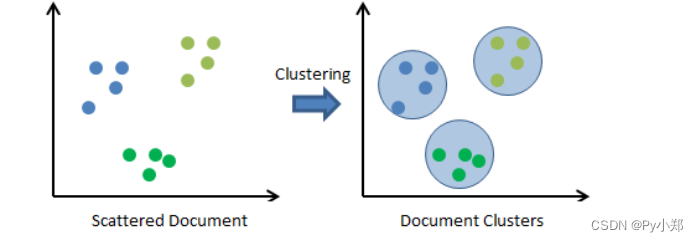
文本聚类:把文本划分到几个特定的Cluster(簇)
主题模型:通常情况下每一篇文章包含多个主题,而主题可以用一组词汇表示,这些词汇之间有较强的相关性,且其概念和语义 基本一致。我们可以认为 (假定) 某个文档以一定概率选择某个主 题,某个主题以一定的概率选择某个词汇,如下 (全概率公式)
简言之就是固定Di和Wj即一篇文章和一个词语,求条件概率即在Di条件下取Wj的概率,求和,比较容易理解,不赘述。
此外一些应用简单的了解:
情感分析:包括情感分类和属性识别,信息抽取以及文本摘要。


TF-IDF(term frequency–inverse document frequency) = TF*IDF


显然TF越大,说明在确定的一篇文章里某个词出现的次数越多,TF-IDF越大,说明这个词越重要;
显然当面临“的”、"地"这样的停顿词,TF还不太够,所以需要引入IDF来平衡一下。
公式易得,当某个词被多个文档包括时,即在多篇文章里经常能看到这个词时,这个词可能就是我们刚刚说的类似于“的”词汇,因此可能没那么重要。
所以公式就很好理解了:打个比喻,在自己的圈子里很厉害未必真的厉害(TF大),在整个世界里厉害才是真的厉害(IDF小)。