数据湖Iceberg-简介(1)
数据湖Iceberg-存储结构(2)
数据湖Iceberg-Hive集成Iceberg(3)
数据湖Iceberg-SparkSQL集成(4)
数据湖Iceberg-FlinkSQL集成(5)
数据湖Iceberg-FlinkSQL-kafka类型表数据无法成功写入(6)
数据湖Iceberg-Flink DataFrame集成(7)
数据湖Iceberg-FlinkSQL-kafka类型表数据无法成功写入
数据湖Iceberg-FlinkSQL-kafka类型表数据无法成功写入版本问题问题原因解决方法
版本
Iceberg:1.1.0
Flink:1.14.3
问题
Kafka类型的Iceberg表创建完成后,通过语句写入其他表中执行成功,但是没数据
问题原因
当前版本的BUG(存疑)
解决方法
Kafka表必须要在default_catalog.default_database下,即catalog名为default_catalog,数据库(命名空间)为default_database下,否则kafka类型的表读取不到数据。
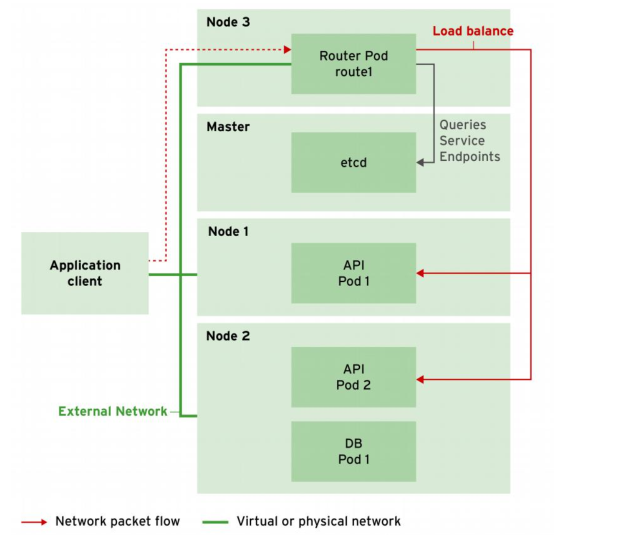
如果都在我们自己创建的catalog下创建,则执行INSERT INTO hadoop_catalog.iceberg_db.sample6 SELECT * FROM default_catalog.default_database.kafka1;后,在Flink任务中看不到一个持续执行的Flink Job,而正常执行该命令Flink会执行一个持续执行的任务,去消费kafka数据写入Iceberg,正常情况如下图:

所以这里我们kafka表在default_catalog.default_database下,写入数据的表在我们自己创建的hadoop_catalog.iceberg_db下
create table default_catalog.default_database.kafka1(
id int,
data string
) with (
'connector' = 'kafka'
,'topic' = 'ttt'
,'properties.zookeeper.connect' = '172.16.24.194:2181'
,'properties.bootstrap.servers' = '172.16.24.194:9092'
,'format' = 'json'
,'properties.group.id'='iceberg1'
,'scan.startup.mode'='earliest-offset'
);
CREATE TABLE `hadoop_catalog`.`iceberg_db`.`sample6` (
`id` INT UNIQUE COMMENT 'unique id',
`data` STRING NOT NULL,
PRIMARY KEY(`id`) NOT ENFORCED
) with (
'format-version'='2',
'write.upsert.enabled'='true'
);
INSERT INTO hadoop_catalog.iceberg_db.sample6 SELECT * FROM default_catalog.default_database.kafka1;
此时我们往Kafka发送数据:
{"id":123,"data":"llalalala"}
{"id":1123,"data":"asdfasfds"}
查看表中数据可以看到写入成功
select * from hadoop_catalog.iceberg_db.sample6;

再次发送数据
{"id":123,"data":"JastData"}
查看表中数据,发现修改成功