文章目录
- 数据湖Iceberg-FlinkSQL集成
- 环境准备
- **Flink与Iceberg的版本对应关系如下**
- jar包下载地址
- jar包上传到Flink lib目录下
- 修改flink-conf.yaml配置
- 创建和使用Catalog
- 创建语法说明
- Hive Catalog
- Hadoop Catalog
- 配置sql-client初始化文件
- DDL语句
- 创建数据库
- 创建表
- 创建分区表
- 使用LIKE语法建表
- 查看表结构
- 修改表
- 修改表属性
- 修改表名
- 删除表
- 查询数据
- Flink On Yarn的问题
- Batch模式
- Streaming模式
- 从当前快照读取所有记录,然后从该快照读取增量数据
- 读取指定快照id(不包含)后的增量数据
- 插入数据
- INSERT INTO
- INSERT OVERWRITE
- UPSERT
- 读取Kafka流,upsert插入到iceberg表中
- 与Flink集成的不足
数据湖Iceberg-简介(1)
数据湖Iceberg-存储结构(2)
数据湖Iceberg-Hive集成Iceberg(3)
数据湖Iceberg-SparkSQL集成(4)
数据湖Iceberg-FlinkSQL集成(5)
数据湖Iceberg-FlinkSQL-kafka类型表数据无法成功写入(6)
数据湖Iceberg-Flink DataFrame集成(7)
数据湖Iceberg-FlinkSQL集成
环境准备
Flink与Iceberg的版本对应关系如下
| Flink 版本 | Iceberg 版本 |
|---|---|
| 1.11 | 0.9.0 – 0.12.1 |
| 1.12 | 0.12.0 – 0.13.1 |
| 1.13 | 0.13.0 – 1.0.0 |
| 1.14 | 0.13.0 – 1.1.0 |
| 1.15 | 0.14.0 – 1.1.0 |
| 1.16 | 1.1.0 – 1.1.0 |
jar包下载地址
https://repo1.maven.org/maven2/org/apache/iceberg/iceberg-flink-runtime-1.14/
在里面选择自己的版本即可,这里我使用的是flink 1.14.3 iceberg1.1.0版本
具体下载地址:https://repo1.maven.org/maven2/org/apache/iceberg/iceberg-flink-runtime-1.14/1.1.0/iceberg-flink-runtime-1.14-1.1.0.jar
jar包上传到Flink lib目录下
[root@ lib]# pwd
/opt/flink/lib
[root@ lib]# ll
total 252612
-rw-r--r-- 1 flink flink 85584 Jan 11 2022 flink-csv-1.14.3.jar
-rw-r--r-- 1 flink flink 136054094 Jan 11 2022 flink-dist_2.12-1.14.3.jar
-rw-r--r-- 1 flink flink 153145 Jan 11 2022 flink-json-1.14.3.jar
-rw-rw-r-- 1 flink flink 43317025 Jan 13 13:54 flink-shaded-hadoop-2-uber-2.8.3-10.0.jar
-rw-r--r-- 1 flink flink 7709731 Aug 22 2021 flink-shaded-zookeeper-3.4.14.jar
-rw-r--r-- 1 flink flink 39633410 Jan 11 2022 flink-table_2.12-1.14.3.jar
-rw-r--r-- 1 flink flink 29256108 Apr 21 09:21 iceberg-flink-runtime-1.14-1.1.0.jar
-rw-r--r-- 1 flink flink 112758 May 3 2013 javax.ws.rs-api-2.0.jar
-rw-r--r-- 1 flink flink 208006 Jan 9 2022 log4j-1.2-api-2.17.1.jar
-rw-r--r-- 1 flink flink 301872 Jan 9 2022 log4j-api-2.17.1.jar
-rw-r--r-- 1 flink flink 1790452 Jan 9 2022 log4j-core-2.17.1.jar
-rw-r--r-- 1 flink flink 24279 Jan 9 2022 log4j-slf4j-impl-2.17.1.jar
修改flink-conf.yaml配置
修改或添加以下配置
# 禁用 ClassLoader 检查
classloader.check-leaked-classloader: false
# 每个 TaskManager 上任务槽数量,这里为 4
taskmanager.numberOfTaskSlots: 4
# 状态后端使用 RocksDB
state.backend: rocksdb
# 每隔 30000 毫秒进行一次检查点
execution.checkpointing.interval: 30000
# 指定检查点保存的目录,这里为 HDFS 上的目录
state.checkpoints.dir: hdfs://hadoop1:8020/ckps
# 启用增量式检查点,这将在一定程度上提高性能
state.backend.incremental: true
启动flink-sql
注意:
刚刚Flink修改完需要重启Flink
输入 ./sql-client.sh embedded或者./sql-client
sql-client.sh embedded是启动 Flink SQL Client 时指定的一种模式,即嵌入式模式。在嵌入式模式下,Flink SQL Client 会自动启动一个 Flink 集群,无需手动启动,直接在命令行中交互式地输入 SQL 命令进行查询和操作。同时,Flink SQL Client 会将所有的数据和表定义存储在本地内存中,这意味着不支持持久化数据和高可用性。
相反,如果您使用的是独立模式,Flink SQL Client 会连接到一个已经运行的 Flink 集群。在这种模式下,需要首先手动启动 Flink 集群,并将 Flink SQL Client 配置为连接到该集群。独立模式相对嵌入式模式更加灵活和可扩展,但启动和配置过程可能需要更多的时间和精力。
总之,嵌入式模式适用于快速原型设计和小规模数据探索,而独立模式适用于生产环境和大规模数据处理。
创建和使用Catalog
创建语法说明
CREATE CATALOG <catalog_name> WITH (
'type'='iceberg',
`<config_key>`=`<config_value>`
);
- type: 必须是iceberg。(必须)
- catalog-type: 内置了hive和hadoop两种catalog,也可以使用catalog-impl来自定义catalog。(可选)
- catalog-impl: 自定义catalog实现的全限定类名。如果未设置catalog-type,则必须设置。(可选)
- property-version: 描述属性版本的版本号。此属性可用于向后兼容,以防属性格式更改。当前属性版本为1。(可选)
- cache-enabled: 是否启用目录缓存,默认值为true。(可选)
- cache.expiration-interval-ms: 本地缓存catalog条目的时间(以毫秒为单位);负值,如-1表示没有时间限制,不允许设为0。默认值为-1。(可选)
Hive Catalog
- 上传hive connector到flink的lib中
下载地址:https://repo1.maven.org/maven2/org/apache/flink/flink-sql-connector-hive-3.1.2_2.12/1.14.3/flink-sql-connector-hive-3.1.2_2.12-1.14.3.jar
- 重启Flink集群,进入sql-client
如果不上传jar包重启服务,后续可能会遇到这种错误
[ERROR] Could not execute SQL statement. Reason: org.apache.hadoop.hive.metastore.api.MetaException: java.lang.reflect.UndeclaredThrowableException
- 创建Hive Catalog
CREATE CATALOG hive_catalog WITH (
'type'='iceberg',
'catalog-type'='hive',
'uri'='thrift://bigdata-24-195:9083',
'clients'='5',
'property-version'='1',
'warehouse'='hdfs://bigdata-24-194:8020/iceberg/iceberg-hive'
);
注意:这里指定的warehouse目录hive用户需要有权限访问,否则后续创建库或者表会失败
Flink SQL> CREATE DATABASE iceberg_db; [ERROR] Could not execute SQL statement. Reason: org.apache.hadoop.hive.metastore.api.MetaException: java.lang.reflect.UndeclaredThrowableException详细异常日志可以在hive日志中查看
-
uri: Hive metastore的thrift uri。(必选)
-
clients:Hive metastore客户端池大小,默认为2。(可选)
-
warehouse: 数仓目录。
-
hive-conf-dir:包含hive-site.xml配置文件的目录路径,hive-site.xml中hive.metastore.warehouse.dir 的值会被warehouse覆盖。
-
hadoop-conf-dir:包含core-site.xml和hdfs-site.xml配置文件的目录路径。
-
查看catalogs
Flink SQL> show CATALOGS ;
+-----------------+
| catalog name |
+-----------------+
| default_catalog |
| hive_catalog |
+-----------------+
2 rows in set
- 进入catalogs
use catalog hive_catalog;
Hadoop Catalog
Iceberg还支持HDFS中基于目录的catalog,可以使用’catalog-type’='hadoop’配置。
- 创建catalog
CREATE CATALOG hadoop_catalog WITH (
'type'='iceberg',
'catalog-type'='hadoop',
'warehouse'='hdfs://bigdata-24-194:8020/iceberg/iceberg-hadoop',
'property-version'='1'
);
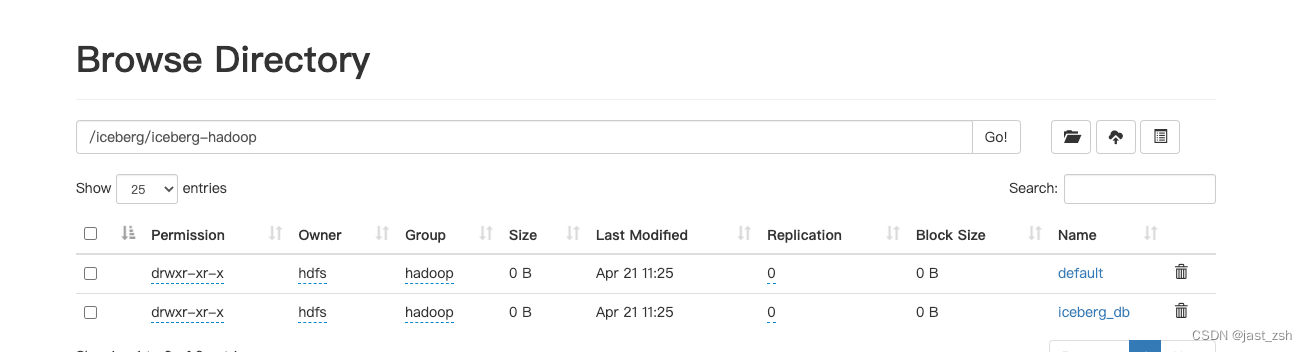
use catalog hadoop_catalog;
create database iceberg_db;
在目录中可以看到我们创建的库和catalog
配置sql-client初始化文件
配置初始化文件后,后续启动,不用每次重新启动都创建catalog
在$FLINK_HOME/conf目录下创建sql-client-init.sql文件
CREATE CATALOG hadoop_catalog WITH (
'type'='iceberg',
'catalog-type'='hadoop',
'warehouse'='hdfs://bigdata-24-194:8020/iceberg/iceberg-hadoop',
'property-version'='1'
);
CREATE CATALOG hive_catalog WITH (
'type'='iceberg',
'catalog-type'='hive',
'uri'='thrift://bigdata-24-195:9083',
'clients'='5',
'property-version'='1',
'warehouse'='hdfs://bigdata-24-194:8020/iceberg/iceberg-hive'
);
USE CATALOG hive_catalog;
后续启动sql-client时,加上 -i sql文件路径 即可完成catalog的初始化,并进入hive_catalog
bin/sql-client.sh embedded -i conf/sql-client-init.sql
DDL语句
创建数据库
CREATE DATABASE iceberg_db;
USE iceberg_db;
创建表
CREATE TABLE `hive_catalog`.`iceberg_db`.`sample` (
id BIGINT COMMENT 'unique id',
data STRING
);
建表命令现在支持最常用的flink建表语法,包括:
- PARTITION BY (column1, column2, …):配置分区,apache flink还不支持隐藏分区。
- COMMENT ‘table document’:指定表的备注
- WITH (‘key’=‘value’, …):设置表属性
目前,不支持计算列、watermark(支持主键)。
创建分区表
CREATE TABLE `hive_catalog`.`iceberg_db`.`sample1` (
id BIGINT COMMENT 'unique id',
data STRING
) PARTITIONED BY (data);
Apache Iceberg支持隐藏分区,但Apache flink不支持在列上通过函数进行分区,现在无法在flink DDL中支持隐藏分区。
使用LIKE语法建表
LIKE语法用于创建一个与另一个表具有相同schema、分区和属性的表。
CREATE TABLE `hive_catalog`.`iceberg_db`.`sample2` (
id BIGINT COMMENT 'unique id',
data STRING
);
CREATE TABLE `hive_catalog`.`iceberg_db`.`sample_like` LIKE `hive_catalog`.`iceberg_db`.`sample2`;
查看表结构
默认在FlinkSQL中无法查看到表结构
Flink SQL> desc formatted sample_like;
[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.sql.parser.impl.ParseException: Encountered "sample_like" at line 1, column 16.
Was expecting one of:
<EOF>
"." ...
我们可以在hive中查看iceberg的表结构
0: jdbc:hive2://bigdata-24-194:2181,bigdata-2> desc formatted sample_like;
INFO : Compiling command(queryId=hive_20230421141659_e372d739-42e8-4cac-97a2-64c10d12c5da): desc formatted sample_like
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:col_name, type:string, comment:from deserializer), FieldSchema(name:data_type, type:string, comment:from deserializer), FieldSchema(name:comment, type:string, comment:from deserializer)], properties:null)
INFO : Completed compiling command(queryId=hive_20230421141659_e372d739-42e8-4cac-97a2-64c10d12c5da); Time taken: 0.077 seconds
INFO : Executing command(queryId=hive_20230421141659_e372d739-42e8-4cac-97a2-64c10d12c5da): desc formatted sample_like
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=hive_20230421141659_e372d739-42e8-4cac-97a2-64c10d12c5da); Time taken: 0.108 seconds
INFO : OK
+-------------------------------+----------------------------------------------------+----------------------------------------------------+
| col_name | data_type | comment |
+-------------------------------+----------------------------------------------------+----------------------------------------------------+
| # col_name | data_type | comment |
| id | bigint | |
| data | string | |
| | NULL | NULL |
| # Detailed Table Information | NULL | NULL |
| Database: | iceberg_db | NULL |
| OwnerType: | USER | NULL |
| Owner: | hdfs | NULL |
| CreateTime: | Fri Apr 22 14:16:17 CST 2023 | NULL |
| LastAccessTime: | Sun Dec 14 04:03:18 CST 1969 | NULL |
| Retention: | 2147483647 | NULL |
| Location: | hdfs://bigdata-24-194:8020/iceberg/iceberg-hive/iceberg_db.db/sample_like | NULL |
| Table Type: | EXTERNAL_TABLE | NULL |
| Table Parameters: | NULL | NULL |
| | EXTERNAL | TRUE |
| | current-schema | {\"type\":\"struct\",\"schema-id\":0,\"fields\":[{\"id\":1,\"name\":\"id\",\"required\":false,\"type\":\"long\"},{\"id\":2,\"name\":\"data\",\"required\":false,\"type\":\"string\"}]} |
| | metadata_location | hdfs://bigdata-24-194:8020/iceberg/iceberg-hive/iceberg_db.db/sample_like/metadata/00000-0750a26c-8b26-4417-9f27-7786a5775026.metadata.json |
| | numFiles | 1 |
| | snapshot-count | 0 |
| | table_type | ICEBERG |
| | totalSize | 1225 |
| | transient_lastDdlTime | 1682057777 |
| | uuid | 4e0be931-e962-4a94-a176-3969012647c1 |
| | NULL | NULL |
| # Storage Information | NULL | NULL |
| SerDe Library: | org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe | NULL |
| InputFormat: | org.apache.hadoop.mapred.FileInputFormat | NULL |
| OutputFormat: | org.apache.hadoop.mapred.FileOutputFormat | NULL |
| Compressed: | No | NULL |
| Num Buckets: | 0 | NULL |
| Bucket Columns: | [] | NULL |
| Sort Columns: | [] | NULL |
+-------------------------------+----------------------------------------------------+----------------------------------------------------+
32 rows selected (0.289 seconds)
修改表
Flink SQL 目前只支持修改表属性和表名,其他的暂不支持,需要使用API才可以修改
修改表属性
ALTER TABLE `hive_catalog`.`iceberg_db`.`sample` SET ('write.format.default'='avro');
修改表名
ALTER TABLE `hive_catalog`.`iceberg_db`.`sample` RENAME TO `hive_catalog`.`iceberg_db`.`new_sample`;
删除表
DROP TABLE `hive_catalog`.`iceberg_db`.`sample`;
不会删除具体数据,HDFS中文件还继续存在
查询数据
Flink On Yarn的问题
这里遇到个问题,先在这直接说了,刚刚只是操作元数据所以没遇到这个问题,在插入和查询都会遇到这个问题
我使用的是Ambari集成的Flink,运行模式为Flink on Yarn,直接用查询、插入语句去操作q数据会提示连接拒绝。
这里几个问题点需要注意:
- 1.当我们使用
Flink on Yarn模式提交时需要指定-s yarn-session去运行,如下
bin/sql-client.sh -s yarn-session -i conf/sql-client-init.sql
指定
-s yarn-session后,Flink会在当前服务器/tmp/.yarn-properties-flink文件找到运行的yarn-session任务,去提交。内容如下:
# cat /tmp/.yarn-properties-flink #Generated YARN properties file #Fri Apr 21 11:11:44 CST 2023 dynamicPropertiesString= applicationID=application_1675237371712_0532
- 2.Ambari 默认Flink on Yarn 提交是使用的Flink用户,我们提交任务是使用HDFS用户,还是会导致提交失败
解决方法:kill之前使用flink用户提交的任务,使用HDFS启动Flink on Yarn任务
这里偷懒了,直接手动kill,手动启动了,有时间可以改下Ambari启动Flink方法,这样才一劳永逸
Flink on yarn 启动命令如下
export HADOOP_CONF_DIR=/etc/hadoop/conf; export HADOOP_CLASSPATH=/usr/hdp/3.1.5.0-152/hadoop/conf:/usr/hdp/3.1.5.0-152/hadoop/lib/*:/usr/hdp/3.1.5.0-152/hadoop/.//*:/usr/hdp/3.1.5.0-152/hadoop-hdfs/./:/usr/hdp/3.1.5.0-152/hadoop-hdfs/lib/*:/usr/hdp/3.1.5.0-152/hadoop-hdfs/.//*:/usr/hdp/3.1.5.0-152/hadoop-mapreduce/lib/*:/usr/hdp/3.1.5.0-152/hadoop-mapreduce/.//*:/usr/hdp/3.1.5.0-152/hadoop-yarn/./:/usr/hdp/3.1.5.0-152/hadoop-yarn/lib/*:/usr/hdp/3.1.5.0-152/hadoop-yarn/.//*:/usr/hdp/3.1.5.0-152/tez/*:/usr/hdp/3.1.5.0-152/tez/lib/*:/usr/hdp/3.1.5.0-152/tez/conf:/usr/hdp/3.1.5.0-152/tez/conf_llap:/usr/hdp/3.1.5.0-152/tez/doc:/usr/hdp/3.1.5.0-152/tez/hadoop-shim-0.9.1.3.1.5.0-152.jar:/usr/hdp/3.1.5.0-152/tez/hadoop-shim-2.8-0.9.1.3.1.5.0-152.jar:/usr/hdp/3.1.5.0-152/tez/lib:/usr/hdp/3.1.5.0-152/tez/man:/usr/hdp/3.1.5.0-152/tez/tez-api-0.9.1.3.1.5.0-152.jar:/usr/hdp/3.1.5.0-152/tez/tez-common-0.9.1.3.1.5.0-152.jar:/usr/hdp/3.1.5.0-152/tez/tez-dag-0.9.1.3.1.5.0-152.jar:/usr/hdp/3.1.5.0-152/tez/tez-examples-0.9.1.3.1.5.0-152.jar:/usr/hdp/3.1.5.0-152/tez/tez-history-parser-0.9.1.3.1.5.0-152.jar:/usr/hdp/3.1.5.0-152/tez/tez-javadoc-tools-0.9.1.3.1.5.0-152.jar:/usr/hdp/3.1.5.0-152/tez/tez-job-analyzer-0.9.1.3.1.5.0-152.jar:/usr/hdp/3.1.5.0-152/tez/tez-mapreduce-0.9.1.3.1.5.0-152.jar:/usr/hdp/3.1.5.0-152/tez/tez-protobuf-history-plugin-0.9.1.3.1.5.0-152.jar:/usr/hdp/3.1.5.0-152/tez/tez-runtime-internals-0.9.1.3.1.5.0-152.jar:/usr/hdp/3.1.5.0-152/tez/tez-runtime-library-0.9.1.3.1.5.0-152.jar:/usr/hdp/3.1.5.0-152/tez/tez-tests-0.9.1.3.1.5.0-152.jar:/usr/hdp/3.1.5.0-152/tez/tez-yarn-timeline-cache-plugin-0.9.1.3.1.5.0-152.jar:/usr/hdp/3.1.5.0-152/tez/tez-yarn-timeline-history-0.9.1.3.1.5.0-152.jar:/usr/hdp/3.1.5.0-152/tez/tez-yarn-timeline-history-with-acls-0.9.1.3.1.5.0-152.jar:/usr/hdp/3.1.5.0-152/tez/tez-yarn-timeline-history-with-fs-0.9.1.3.1.5.0-152.jar:/usr/hdp/3.1.5.0-152/tez/ui:/usr/hdp/3.1.5.0-152/tez/lib/async-http-client-1.9.40.jar:/usr/hdp/3.1.5.0-152/tez/lib/commons-cli-1.2.jar:/usr/hdp/3.1.5.0-152/tez/lib/commons-codec-1.4.jar:/usr/hdp/3.1.5.0-152/tez/lib/commons-collections-3.2.2.jar:/usr/hdp/3.1.5.0-152/tez/lib/commons-collections4-4.1.jar:/usr/hdp/3.1.5.0-152/tez/lib/commons-io-2.4.jar:/usr/hdp/3.1.5.0-152/tez/lib/commons-lang-2.6.jar:/usr/hdp/3.1.5.0-152/tez/lib/commons-math3-3.1.1.jar:/usr/hdp/3.1.5.0-152/tez/lib/gcs-connector-hadoop3-1.9.17.3.1.5.0-152-shaded.jar:/usr/hdp/3.1.5.0-152/tez/lib/guava-28.0-jre.jar:/usr/hdp/3.1.5.0-152/tez/lib/hadoop-aws-3.1.1.3.1.5.0-152.jar:/usr/hdp/3.1.5.0-152/tez/lib/hadoop-azure-3.1.1.3.1.5.0-152.jar:/usr/hdp/3.1.5.0-152/tez/lib/hadoop-azure-datalake-3.1.1.3.1.5.0-152.jar:/usr/hdp/3.1.5.0-152/tez/lib/hadoop-hdfs-client-3.1.1.3.1.5.0-152.jar:/usr/hdp/3.1.5.0-152/tez/lib/hadoop-mapreduce-client-common-3.1.1.3.1.5.0-152.jar:/usr/hdp/3.1.5.0-152/tez/lib/hadoop-mapreduce-client-core-3.1.1.3.1.5.0-152.jar:/usr/hdp/3.1.5.0-152/tez/lib/hadoop-yarn-server-timeline-pluginstorage-3.1.1.3.1.5.0-152.jar:/usr/hdp/3.1.5.0-152/tez/lib/jersey-client-1.19.jar:/usr/hdp/3.1.5.0-152/tez/lib/jersey-json-1.19.jar:/usr/hdp/3.1.5.0-152/tez/lib/jettison-1.3.4.jar:/usr/hdp/3.1.5.0-152/tez/lib/jetty-server-9.3.24.v20180605.jar:/usr/hdp/3.1.5.0-152/tez/lib/jetty-util-9.3.24.v20180605.jar:/usr/hdp/3.1.5.0-152/tez/lib/jsr305-3.0.0.jar:/usr/hdp/3.1.5.0-152/tez/lib/metrics-core-3.1.0.jar:/usr/hdp/3.1.5.0-152/tez/lib/protobuf-java-2.5.0.jar:/usr/hdp/3.1.5.0-152/tez/lib/RoaringBitmap-0.4.9.jar:/usr/hdp/3.1.5.0-152/tez/lib/servlet-api-2.5.jar:/usr/hdp/3.1.5.0-152/tez/lib/slf4j-api-1.7.10.jar:/usr/hdp/3.1.5.0-152/tez/lib/tez.tar.gz;
/opt/flink/bin/yarn-session.sh -d -nm flinkapp-from-ambari -n 1 -s 1 -jm 768 -tm 1024 -qu default >> /var/log/flink/flink-setup.log &
Batch模式
SET execution.runtime-mode = batch;
select * from sample;
Streaming模式
-- 设置 Flink 的运行模式为流式计算
SET execution.runtime-mode = streaming;
-- 启用动态表选项
SET table.dynamic-table-options.enabled=true;
-- 设置 Flink SQL 执行结果的输出格式为 Tableau
SET sql-client.execution.result-mode=tableau;
-- 查询 Hive Catalog 中的 Iceberg 表 sample 中的所有数据
select * from hive_catalog.iceberg_db.sample;
SET table.dynamic-table-options.enabled=true;从 1.11 开始,用户可以通过动态参数的形式灵活地设置表的属性参数,覆盖或者追加原表的 WITH (…) 语句内定义的 table options。
基本语法为:
table_path /*+ OPTIONS(key=val [, key=val]*) */
动态参数的使用没有语境限制,只要是引用表的地方都可以追加定义。在指定的表后面追加的动态参数会自动追加到原表定义中
从当前快照读取所有记录,然后从该快照读取增量数据
SELECT * FROM sample5 /*+ OPTIONS('streaming'='true', 'monitor-interval'='1s')*/ ;
返回格式(会根据新增数据持续滚动)
Flink SQL> SELECT * FROM hive_catalog.iceberg_db.sample /*+ OPTIONS('streaming'='true', 'monitor-interval'='1s')*/ ;
2023-04-21 15:43:33,819 INFO org.apache.hadoop.yarn.client.RMProxy [] - Connecting to ResourceManager at bigdata-24-194/172.16.24.194:8050
2023-04-21 15:43:33,821 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2023-04-21 15:43:33,822 WARN org.apache.flink.yarn.YarnClusterDescriptor [] - Neither the HADOOP_CONF_DIR nor the YARN_CONF_DIR environment variable is set.The Flink YARN Client needs one of these to be set to properly load the Hadoop configuration for accessing YARN.
2023-04-21 15:43:33,830 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface bigdata-24-196:6588 of application 'application_1675237371712_0532'.
+----+----------------------+--------------------------------+
| op | id | data |
+----+----------------------+--------------------------------+
| +I | 34 | aeefb |
| +I | 34 | ae |
| +I | 1 | a |
| +I | 1 | a |
| +I | 34 | aee |
| +I | 34 | aeeefdsfafb |
读取指定快照id(不包含)后的增量数据
SELECT * FROM sample /*+ OPTIONS('streaming'='true', 'monitor-interval'='1s', 'start-snapshot-id'='3821550127947089987')*/ ;
-
monitor-interval: 连续监控新提交数据文件的时间间隔(默认为10s)。
-
start-snapshot-id: 流作业开始的快照id。
注意:如果是无界数据流式upsert进iceberg表(读kafka,upsert进iceberg表),那么再去流读iceberg表会存在读不出数据的问题。如果无界数据流式append进iceberg表(读kafka,append进iceberg表),那么流读该iceberg表可以正常看到结果。
插入数据
INSERT INTO
INSERT INTO `hive_catalog`.`iceberg_db`.`sample` VALUES (1, 'a');
INSERT INTO `hive_catalog`.`iceberg_db`.`sample` SELECT id, data from sample2;
INSERT OVERWRITE
仅支持Flink的Batch模式
SET execution.runtime-mode = batch;
INSERT OVERWRITE sample VALUES (1, 'a');
INSERT OVERWRITE `hive_catalog`.`default`.`sample` PARTITION(data='a') SELECT 6;
UPSERT
当将数据写入v2表格式时,Iceberg支持基于主键的UPSERT。有两种方法可以启用upsert。
建表时指定
CREATE TABLE `hive_catalog`.`iceberg_db`.`sample5` (
`id` INT UNIQUE COMMENT 'unique id',
`data` STRING NOT NULL,
PRIMARY KEY(`id`) NOT ENFORCED
) with (
'format-version'='2',
'write.upsert.enabled'='true'
);
插入时指定
INSERT INTO `hive_catalog`.`iceberg_db`.`sample5` /*+ OPTIONS('upsert-enabled'='true') */ values(1,'a'),(2,'b'),(3,'c');
结果:
+----+-------------+--------------------------------+
| op | id | data |
+----+-------------+--------------------------------+
| +I | 1 | a |
| +I | 2 | b |
| +I | 3 | c |
+----+-------------+--------------------------------+
插入
INSERT INTO `hive_catalog`.`iceberg_db`.`sample5` /*+ OPTIONS('upsert-enabled'='true') */ values(1,'abc'));
结果
+----+-------------+--------------------------------+
| op | id | data |
+----+-------------+--------------------------------+
| +I | 1 | abc |
| +I | 2 | b |
| +I | 3 | c |
+----+-------------+--------------------------------+
插入的表,format-version需要为2。
OVERWRITE和UPSERT不能同时设置。在UPSERT模式下,如果对表进行分区,则分区字段必须也是主键。
读取Kafka流,upsert插入到iceberg表中
下载:https://repo1.maven.org/maven2/org/apache/flink/flink-sql-connector-kafka_2.12/1.14.3/flink-sql-connector-kafka_2.12-1.14.3.jar
将jar包放到$FLINK_HOME/lib目录下,重启Flink On Yarn
这里先说一个大坑,Iceberg现阶段的一个Bug
Kafka表必须要在default_catalog.default_database下,即catalog名为default_catalog,数据库(命名空间)为default_database下,否则kafka类型的表读取不到数据。
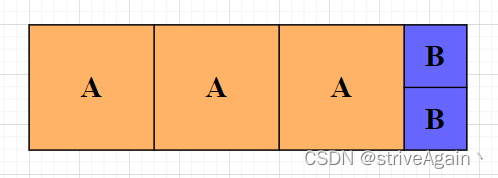
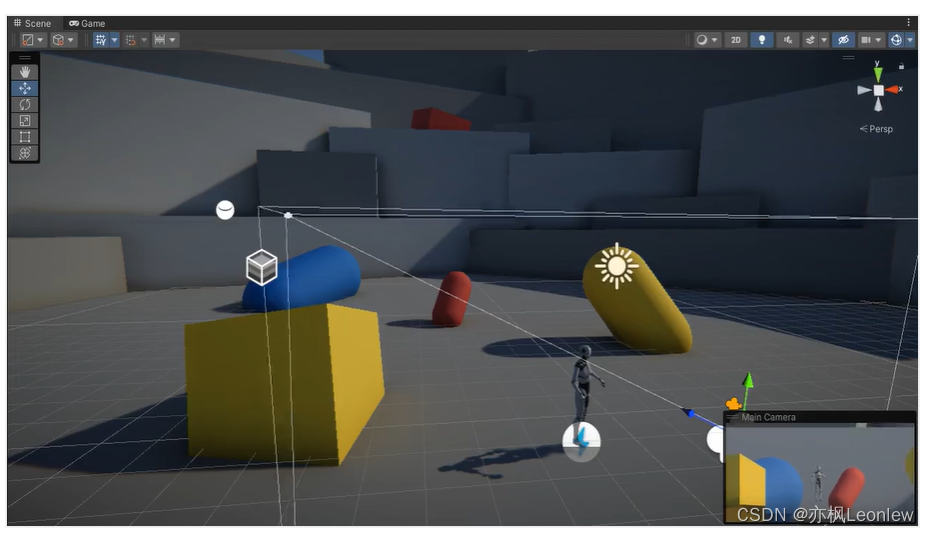
如果都在我们自己创建的catalog下创建,则执行INSERT INTO hadoop_catalog.iceberg_db.sample6 SELECT * FROM default_catalog.default_database.kafka1;后,在Flink任务中看不到一个持续执行的Flink Job,而正常执行该命令Flink会执行一个持续执行的任务,去消费kafka数据写入Iceberg,正常情况如下图:

所以这里我们kafka表在default_catalog.default_database下,写入数据的表在我们自己创建的hadoop_catalog.iceberg_db下
create table default_catalog.default_database.kafka1(
id int,
data string
) with (
'connector' = 'kafka'
,'topic' = 'ttt'
,'properties.zookeeper.connect' = '172.16.24.194:2181'
,'properties.bootstrap.servers' = '172.16.24.194:9092'
,'format' = 'json'
,'properties.group.id'='iceberg1'
,'scan.startup.mode'='earliest-offset'
);
CREATE TABLE `hadoop_catalog`.`iceberg_db`.`sample6` (
`id` INT UNIQUE COMMENT 'unique id',
`data` STRING NOT NULL,
PRIMARY KEY(`id`) NOT ENFORCED
) with (
'format-version'='2',
'write.upsert.enabled'='true'
);
INSERT INTO hadoop_catalog.iceberg_db.sample6 SELECT * FROM default_catalog.default_database.kafka1;
此时我们往Kafka发送数据:
{"id":123,"data":"llalalala"}
{"id":1123,"data":"asdfasfds"}
查看表中数据可以看到写入成功
select * from hadoop_catalog.iceberg_db.sample6;

再次发送数据
{"id":123,"data":"JastData"}
查看表中数据,发现修改成功

与Flink集成的不足
| 支持的特性 | Flink | 备注 |
|---|---|---|
| SQL create catalog | √ | |
| SQL create database | √ | |
| SQL create table | √ | |
| SQL create table like | √ | |
| SQL alter table | √ | 只支持修改表属性,不支持更改列和分区 |
| SQL drop_table | √ | |
| SQL select | √ | 支持流式和批处理模式 |
| SQL insert into | √ | 支持流式和批处理模式 |
| SQL insert overwrite | √ | |
| DataStream read | √ | |
| DataStream append | √ | |
| DataStream overwrite | √ | |
| Metadata tables | 支持Java API,不支持Flink SQL | |
| Rewrite files action | √ |
- 不支持创建隐藏分区的Iceberg表。
- 不支持创建带有计算列的Iceberg表。
- 不支持创建带watermark的Iceberg表。
- 不支持添加列,删除列,重命名列,更改列。
- Iceberg目前不支持Flink SQL 查询表的元数据信息,需要使用Java API 实现。