Graphql中我们应该用什么姿势来实现Resolver?
- Graphql中我们应该用什么姿势来实现Resolver?
- 前言
- 设计数据库
- 定义 Type
- 实现 Resolver
- 按需组装查询语句请求数据库
- GraphQLResolveInfo
- 附录
前言
我最近在用 Graphql 来弥补原先写的 RESTFUL 接口的一些短板。在实践过程中遇到了一些思考,借着文章抛砖引玉,分享给大家。
为了让大家更好的理解本文的思想,我搞了一个简单的案例,源码见附录。
设计数据库
先上一个关系型数据库 ER 图。既然用 Graphql 来做数据聚合和查询,那么我们先从数据库表的设计开始,毕竟这才是数据的源头。
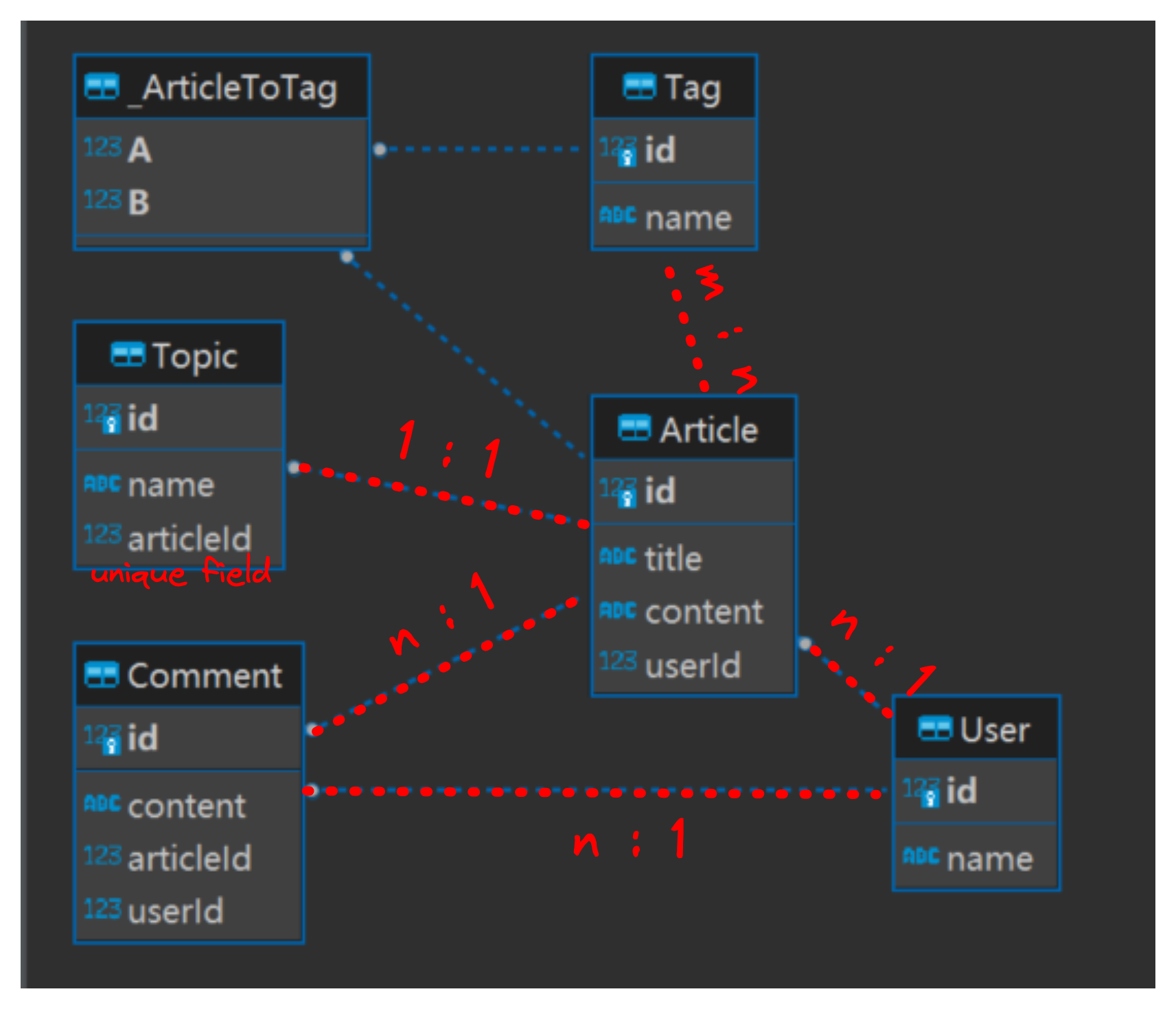
从上图可知这些实体之间所有的关系信息,接着根据ER图我们来定义 Graphql Type
定义 Type
首先我们把 ER 图,变成 Graph TypeDefs 即为:
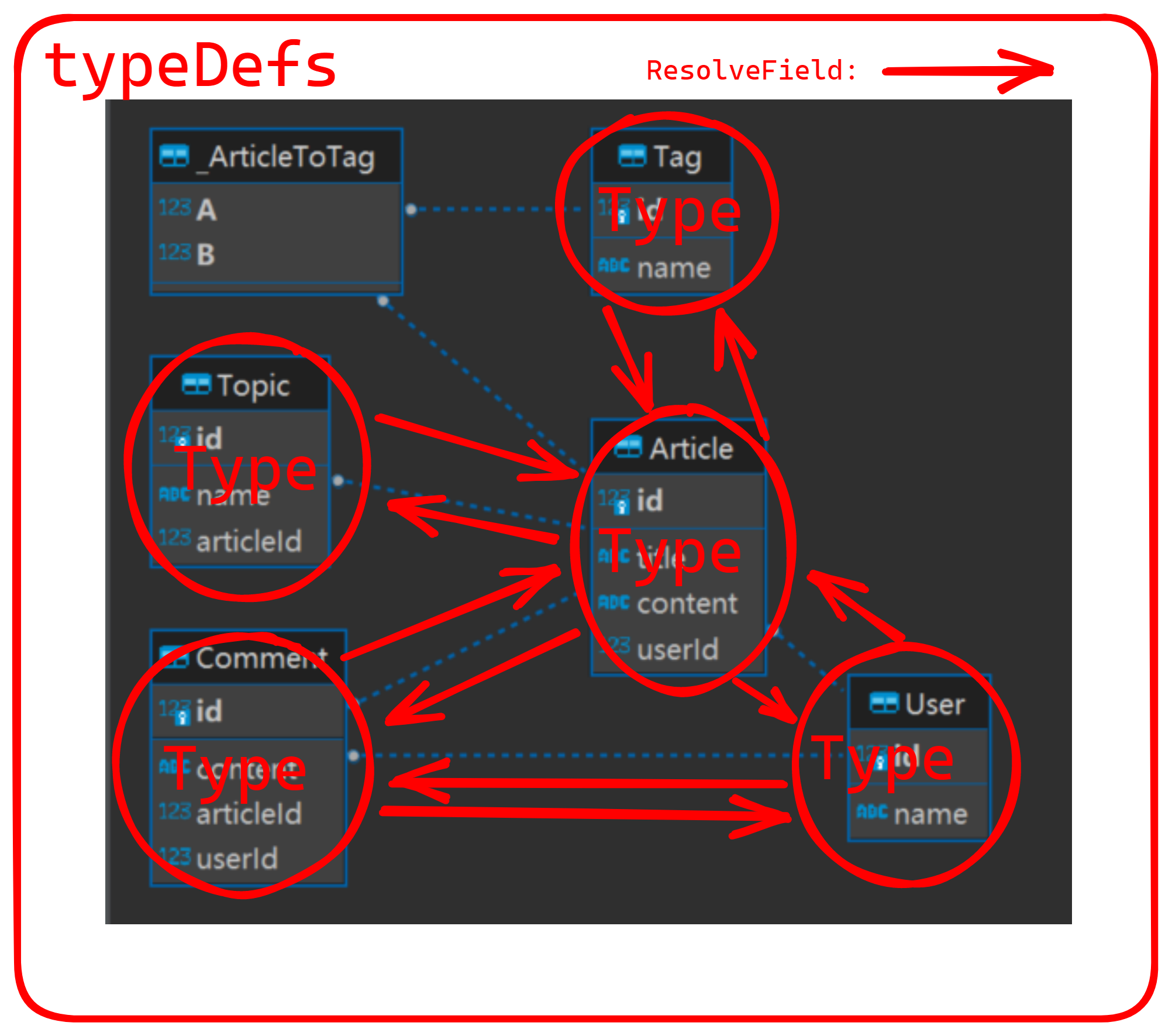
于是就能直接粗略的把 SDL 写好了:
type Article {
comments: [Comment!]!
content: String!
id: Int!
tags: [Tag!]!
title: String!
topic: Topic
user: User!
userId: Int!
}
type Comment {
article: Article!
articleId: Int!
content: String!
id: Int!
user: User!
userId: Int!
}
type Tag {
articles: [Article!]!
id: Int!
name: String!
}
type Topic {
article: Article!
articleId: Int!
id: Int!
name: String!
}
type User {
articles: [Article!]!
comments: [Comment!]!
id: Int!
name: String!
}
接下来我们就开始定义 Query 和 Mutation 这种用来提供给前端使用的 entry point 了。至此,新手部分结束,进入本篇的正文。
实现 Resolver
当我们定义好所有的 Type 之后,接下来就是去真正的实现后端的交互逻辑,也就是实现 Resolver。
那么什么是 Resolver 呢?Resolver实际上就是一个函数,它负责为我们定义的 schema 中每个字段来填充相应的数据。
那么我们需要实现哪些呢?显然每一个 GraphQL Type 都必须定义一个 Resolver 用来去获取对应格式的数据. 比如 Article 从数据表中获取就可以这么写:
添加一个 Query:
type Query {
allArticles: [Article]
}
实现对应的 Resolver
为了易于展示和理解,接下来的数据库交互部分代码都使用 prisma orm 框架来表示
Query: {
// 入参依次为 parent 节点,这里为 undefined
// 参数args
// 上下文ctx
// GraphQLResolveInfo info
allArticles(_, args, ctx, info) {
return prisma.article.findMany()
}
}
对于 Graphql 引擎来说,它会把 prisma.article.findMany() 的结果,转化成定义的 [Article]。针对2者同名字段的处理,当发现是一个 Scalar 的时候,就会去使用内部的序列化方法来处理数据。当请求query里包含另一个子 Type 时,它就会执行当前Type下对应向量的 Resolver函数。
我们来看一个例子:
query {
allArticles{
id
# 当前 type 是 Article
comments{
# 当前 type 是 Comment
id
}
}
}
这个请求,就以此调用了2个Resolver方法,第一次是 Query 的 allArticles 的 Resolver,第二次 Article->Comment 的 Resolver。
所以我们简单定义实现一下Article->Comment 的 Resolver:
Article: {
comments(parent: Article, args, ctx, info) {
return prisma.comment.findMany(
where: {
articleId: parent.id
}
)
}
},
和之前定义的Query allArticles Resolver 不同,这时候的 Resolver函数,它是有 parent 节点的,这个 parent 就是上一个 allArticles Resolver 的数组返回结果中单个的 Article。我们传入一个 where 筛选条件,来在数据库中筛选指定条件的数据,返回出来,再经过 Comment 中,每一个 Scalar 的序列化,最终组装到父节点的数据对象上。
最终 Graphql 引擎就自动的帮助我们组装好了结构化的数据了,是不是非常方便?
关于
GraphQLScalarType,GraphQL中内置了像Int,Float,String,Boolean,ID这类的GraphQLScalarType用于基础的声明与数据的处理。我们也可以自定义GraphQLScalarType,当然graphql-scalars内已经实现了许多开箱即用的Scalar,推荐使用。
那些引用其他 Type 的 Field 就组成了关系,如图所示:
图中,每一个箭头都是关系,这个关系是有向的,A->B 和 B->A,它们 虽然都在做 resolve,但是它们调用的是不同的函数方法。
这个关系可以指向其他的 Type 也可以指向自身。比如有可能会出现 A->A->A->A->... 这样无限递归的 query,也会出现那种 A->B->A->B->... 这样的请求,这种请求复杂度的计算和限制,留到以后Graphql AST章节再说。
按需组装查询语句请求数据库
上面那个Demo明眼人一眼就能看出非常不好。比如上面那个查询语句,它的语义化结果,就是找到所有文章的id,以及每篇文章中所有评论的id。然而它的调用数据库查询次数太多了!比如你有 100 篇文章,每篇文章都要插一次评论,那就是 1+100=101 次查询,我的天啊,这对于列表查询是无法忍受的!
一般我们实现 RESTFUL 列表分页查询接口,我们会使用数据库的 join 或者 lookup 操作来处理这种情况。
那么好办了,我们可以在第一次调用 allArticles Resolver 的时候就去 join Comment表把数据统统取出来不就可以了吗?我们改一下实现:
Query: {
allArticles(_, args, contextValue, info) {
return prisma.article.findMany({
include: {
comments: true
}
})
}
}
Article: {
comments(parent, args, contextValue, info) {
// 这里只是一个简略的判断,具体按类型进行判断
if (parent.comments) {
return parent.comments
}
return prisma.comment.findMany({
where: {
articleId: parent.id
}
})
}
}
这一下子就把数据库的查询次数,降低到一次了,因为即使没有找到 Article 对应的 Comment,也会返回一个空数组,从而走了直接 return 的逻辑,这似乎就完成了我们的目标?
不,路漫漫其修远兮。假设又有 query 进来是这种呢?
query {
allArticles{
id
content
}
}
这次的请求可不需要 comments,可是我们还是去 join 了 Comment,这没有丝毫意义,反而加重了数据库请求的负担,这就是没有做到按需 join。
同时我们默认 select * from table,而 query 中我们仅仅只需要那么 1-2 个字段,这意味着大量的字段的数据,从数据库中取出了之后,加载进内存里,然后交给 Graphql 引擎处理之后,便被无情的抛弃了,其实从一开始就没有从数据库里取出它们的必要。比如 Article content 每个都有 1MB 呢?那内存不是很容易溢出?所以我们同时也要实现按需 select。
那么我们怎么实现呢?接下来我们聚焦在一个对象上: GraphQLResolveInfo
GraphQLResolveInfo
GraphQLResolveInfo 这个对象里,包含着我们这次 Query 请求所有的模式和操作信息还有AST节点等等对象。
我们可以通过解析它来获取一次 Query 究竟要获取多少个字段,多少个不同的 Type 以及对应的层级,深度等等。在我们这种场景,我们只需要把 Query 在 Server 端被还原成对象,来供给我们做相对于的操作就行。
于是我们就能够封装一个方法来获取这个对象:
import { parse, simplify, type ResolveTree } from 'graphql-parse-resolve-info'
import type { GraphQLResolveInfo } from 'graphql'
export type FieldInfo<T> = Partial<Record<keyof T, ResolveTree>>
export function getFields<T = any>(info: GraphQLResolveInfo): FieldInfo<T> {
const parsedResolveInfoFragment = parse(info) as ResolveTree
const { fields } = simplify(parsedResolveInfoFragment, info.returnType)
return fields
}
获取这个层级对象之后,就能够对 Resolver 进行进一步的改进:
Query: {
allArticles(_, args, contextValue, info) {
const fields = getFields<Prisma.ArticleSelect>(info)
const commentFields = fields.comments?.fieldsByTypeName.Comment
const select: Prisma.ArticleSelect = {
id: true,
content: Boolean(fields.content),
title: Boolean(fields.title),
userId: Boolean(fields.userId || fields.user)
}
if (commentFields) {
select.comments = {
select: {
id: true,
content: Boolean(commentFields.content)
}
}
}
return prisma.article.findMany({
select
})
},
},
Article: {
comments(
parent: Prisma.ArticleGetPayload<{
include: {
comments: true
}
}>,
args,
contextValue,
info
) {
if (parent.comments) {
return parent.comments
}
const fields = getFields<Prisma.CommentSelect>(info)
return prisma.comment.findMany({
select: {
id: true,
articleId: Boolean(fields.articleId || fields.article),
content: Boolean(fields.content),
userId: Boolean(fields.userId || fields.user)
},
where: {
articleId: parent.id
}
})
}
},
当然,这种解法虽然带来了按需的方式,但是同时要比之前那种写法要复杂的多。同时随着 Query 请求层级加深,代码会变得难以维护。
另外目前这种方式,在遇到复杂请求的时候也会出现问题,比如这种 Query:
query {
allArticles {
...queryFragment
}
}
fragment queryFragment on Article {
comments {
article {
comments {
article {
comments {
articleId
}
}
}
}
}
}
这种循环嵌套的请求在业务上没有啥意义,但却是合法可解析可运行的。
又比如遇到这种 Query 我们又要在代码里实现join User 表来取数据的逻辑:
query {
allArticles{
id
comments {
id
content
user {
id
name
}
}
}
}
显然,这种按需方式大大的增加了实现的复杂度,而且也容易出错,那么究竟怎么做到性能和简单的平衡呢?
这是一个值得思考的问题,我有一个想法,既然要简单,那肯定是最初的那种101次调用数据库的方式最简单,假设这 101 次的数据都在缓存里呢?调用足够快,一次 redis pipe 调用就能把所有数据取出来,同时假如没有的数据,会自己去从数据库里,进行同步,置缓存之后再返回。
同时也有设计合理的数据预热机制与缓存刷新机制,那架构应该是怎么样的呢?如图所示:
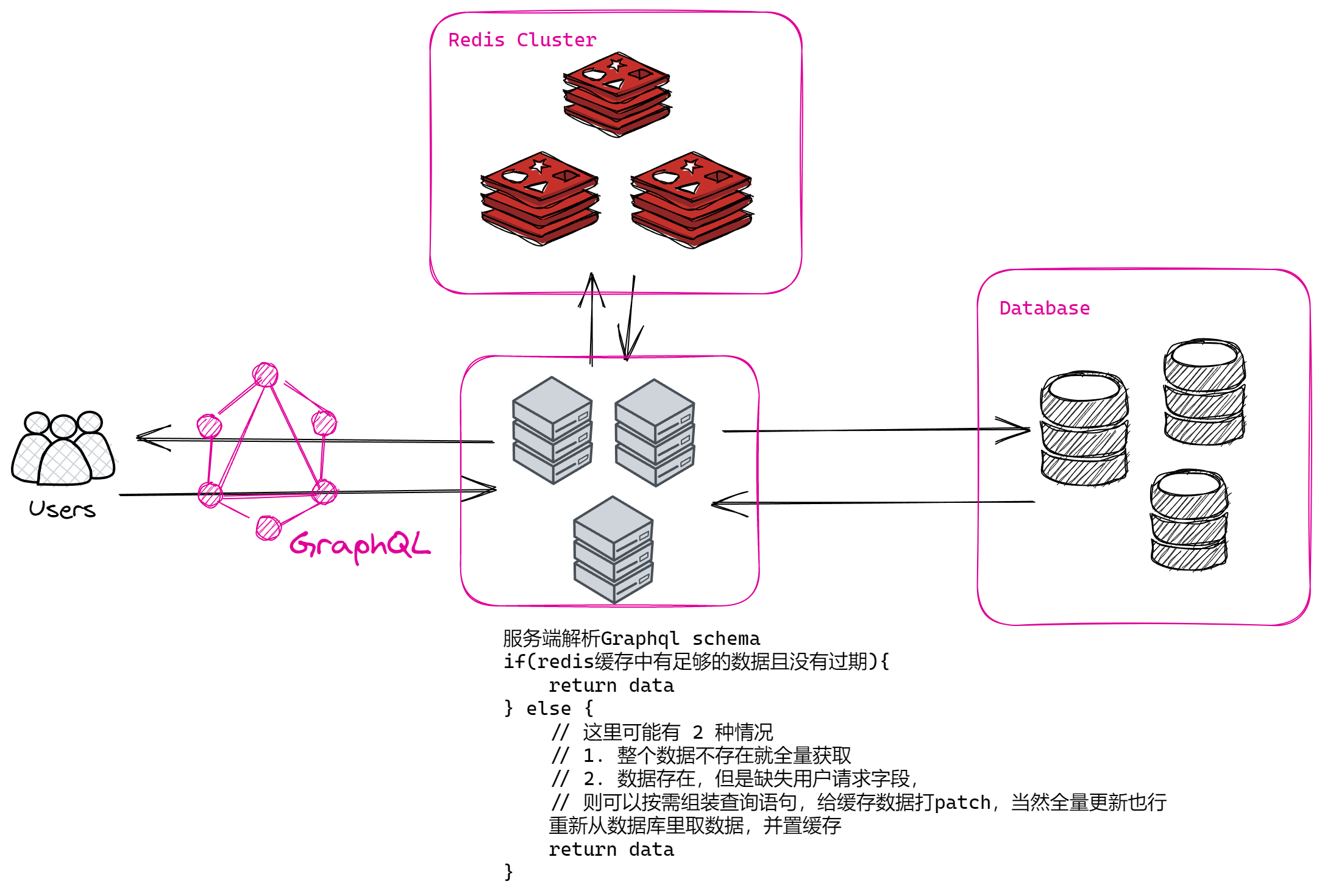
同时在预热和数据库请求方面,也要尽量的合并请求来减小调用次数。这个问题就留到我们以后去探讨了。也欢迎大家分享各自的思考和想法。
附录
apollo-graphql-prisma-template