rep
函数形式:rep(x, time = , length = , each = ,)
参数说明:
x:代表的是你要进行复制的对象,可以是一个向量或者是一个因子。
times:代表的是复制的次数,只能为正数。负数以及NA值都会为错误值。复制是指的是对整个向量进行复制。
each:代表的是对向量中的每个元素进行复制的次数。
length.out:代表的是最终输出向量的长度。
runif
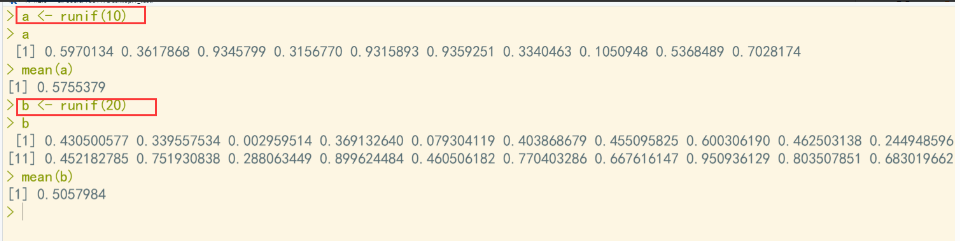
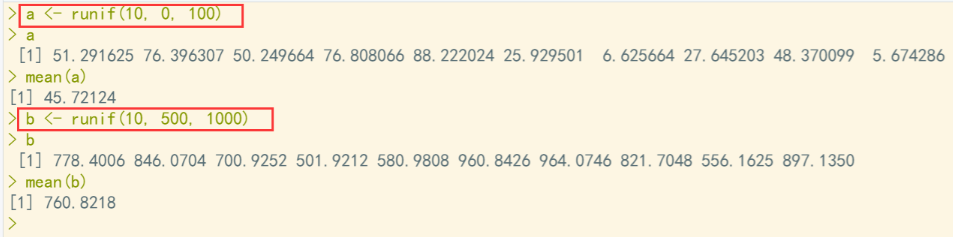
R语言中的runif ()函数用于生成从0到1区间范围内的服从正态分布的随机数,每次生成的值都不一样;set.seed ()用于生成随机数的种子元素,两个函数配合起来发挥作用。

这里的runif就是生成100个符合正态分布的随机数
matrix
R语言Matrix函数
dim
R语言中的dim()函数用于获取或设置指定矩阵、数组或 DataFrame 的维数。
用法: dim(x)
参数:
x:数组、矩阵或 DataFrame 。
范例1:
输出:
Time demand
1 1 8.3
2 2 10.3
3 3 19.0
4 4 16.0
5 5 15.6
6 7 19.8
[1] 6 2
范例2:
round
round是R里的'四舍五入'函数,具体的规则采用banker's rounding,即四舍六入五留双规则。 round的原型是round(x, digits = 0), digits设定小数点位置,默认为零即小数点后零位(取整)。
scan
R语言 扫描并从文件中读取数据 – scan() 函数
R语言中的 scan() 函数是用来扫描和读取数据的。在R语言中,它通常用于将数据读入向量、列表或从文件中读取。
语法:
scan(“data.txt”, what = “character”)
参数:
data.txt: 要扫描的文本文件
返回: 扫描的输出
因子型
R语言的数据类型中,因子(Factor)型比较特殊,也让许多初学者感到难以理解。其实就像整型用来存储整数、字符型用来存储字符或字符串类似,因子型是用来存储类别的数据类型,因子型变量因此是离散变量。 eg:五个用户月均通话次数分别是(15, 1, 63, 19, 122),存储在变量calls_num中。此时calls_num是一个数值型变量,有五个值,且理论上每个值的取值范围是0到+∞。如果想将这个变量进行离散化,根据[0,10] , (10,100] ,(100,+∞]将次数划分为低频、中频、高频三个类别,这时便可建立一个因子型变量f_calls_num记录每个用户月均通话次数所在类别,即(中频,低频,中频,中频,高频)。 因子水平(Level)表示因子的值域,因子的每个元素只能取因子水平中的值或缺失。上例中,因子水平就是(低频,中频,高频)。
attach和detach
attach和detch
数据是我们在使用R语言做统计和数据分析相关的工作经常用到的对象。但是当数据太多的时候,我们会构造数据框、列表、数组和矩阵等各种数据类型。但是数据每一列的索引就成了问题。尤其是在大量的重复性的调用时。这时候我们经常会使用attach与detach这两个函数来使我们的代码变得更简洁。本文就这两个函数进行讲解。
attach用于索引数据集
detach用于删除数据集
coef
coef

线性回归概览
傻瓜式线性回归
confint
R语言函数名:confint() R语言函数功能:模型参数的置信区间
cbind&rbind
cbind: 根据列进行合并,即叠加所有列,m列的矩阵与n列的矩阵cbind()最后变成m+n列,合并前提:cbind(a, c)中矩阵a、c的行数必需相符
rbind: 根据行进行合并,就是行的叠加,m行的矩阵与n行的矩阵rbind()最后变成m+n行,合并前提:rbind(a, c)中矩阵a、c的列数必需相符
solve
R语言中的solve()函数用于求解线性代数方程。这里的方程类似于 a*x = b,其中 b 是向量或矩阵,x 是将要计算其值的变量。
solve(a,b)
参数: a:方程的系数 b:方程的向量或矩阵
范例1:
范例2:
t转置函数
t():给定矩阵或数据框x,t函数返回x的转置。
在对data.frame进行t()操作时需要注意,避免数字变成字符串。
矩阵里面所有内容都是相同类型数据,使用t()不会有问题。
数值类型矩阵转置:
可以看出来就是行变列,列变行了。数值型还是数值型。
字符串类型转置:
数据框转置:
数值型数据框和矩阵差不多,转置不会有太大问题。
但是转置前是data.frame,转置后的结果是matrix
混合型数据框转置
如果data.frame里面既有数值型,又有字符串,t()转置后得到的matrix里面全部都会变成字符串。
可以看到原来的Score的数值型被转换成chr字符串类型了,不能再进行针对数值型的操作了。
这个时候如果还希望保持原来的数据类型,则需要用到as.data.frame函数
这时候转化后的Score行里面的数字都是数值型了。
因此,在对保护复杂数据类型的data.frame进行转置时,最好使用as.data.frame(t(x))来操作。
summary
summary():获取描述性统计量,可以提供最小值、最大值、四分位数和数值型变量的均值,以及因子向量和逻辑型向量的频数统计等。结果解读如下:
1. 调用:Call
2. 残差统计量:Residuals
3. 系数:Coefficients
4. Multiple R-squared和Adjusted R-squared
5. F-statistic
1. 调用:Call
lm(formula = DstValue ~ Month + RecentVal1 + RecentVal4 + RecentVal6 + RecentVal8 + RecentVal12, data = trainData)
当创建模型时,以上代码表明lm是如何被调用的。
2. 残差统计量:Residuals
Min 1Q Median 3Q Max
-4806.5 -1549.1 -171.8 1368.7 6763.3
残差第一四分位数(1Q)和第三分位数(Q3)有大约相同的幅度,意味着有较对称的钟形分布。
3. 系数:Coefficients
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.345e+06 5.659e+05 2.377 0.01879 *
Month 8.941e+02 2.072e+02 4.316 3.00e-05 ***
分别表示: 估值 标准误差 T值 P值
Intercept:表示截距
Month:影响因子/特征
Estimate的列:包含由普通最小二乘法计算出来的估计回归系数。
Std. Error的列:估计的回归系数的标准误差。
P值估计系数不显著的可能性,有较大P值的变量是可以从模型中移除的候选变量。
t 统计量和P值:从理论上说,如果一个变量的系数是0,那么该变量是无意义的,它对模型毫无贡献。然而,这里显示的系数只是估计,它们不会正好为0。因此,我们不禁会问:从统计的角度而言,真正的系数为0的可能性有多大?这是t统计量和P值的目的,在汇总中被标记为t value和Pr(>|t|)。
其 中,我们可以直接通过P值与我们预设的0.05进行比较,来判定对应的解释变量的显著性,我们检验的原假设是:该系数显著为0;若P<0.05,则拒绝原假设,即对应的变量显著不为0。可以看到Month、RecentVal4、RecentVal8都可以认为是在P为0.05的水平下显著不为0,通过显著性检验;Intercept的P值为0.26714,不显著。
4. Multiple R-squared和Adjusted R-squared
这两个值,即R^{2},常称之为“拟合优度”和“修正的拟合优度”,指回归方程对样本的拟合程度几何,这里我们可以看到,修正的拟合优 度=0.8416,表示拟合程度良好,这个值当然是越高越好。当然,提升拟合优度的方法很多,当达到某个程度,我们也就认为差不多了。具体还有很复杂的判定内容,有兴趣的可以看看:http://baike.baidu.com/view/657906.htm
5. F-statistic
F-statistic,是我们常说的F统计量,也成为F检验,常常用于判断方程整体的显著性检验,其值越大越显著;其P值为p-value: < 2.2e-16,显然是<0.05的,可以认为方程在P=0.05的水平上还是通过显著性检验的。

若有收获,就点个赞吧
![[oeasy]python0139_尝试捕获异常_ try_except_traceback](https://img-blog.csdnimg.cn/img_convert/0b3e929819bc1dede35fa1c189390127.png)