github 地址:GitHub - memory-overflow/light-task-scheduler: 一个go语言的轻量级的快速实现任务调度的框架,并且支持有状态任务的持久化,并发控制和超时控制。
框架的设计思想和背景
业务后台开发,经常会遇到很多并发低,处理耗时长的限频任务,比如流媒体行业的视频转码、裁剪。这些任务的调度流程整体上没有差别,但是细节上又会有很多差异,以至于每新增一个任务类型,都要把调度部分的代码 copy 一份后修修改改。随着任务类型的越来越多,copy 代码的方式效率低下,且容易改出问题,这时候需要一个任务调度框架,既能够统一任务调度的流程,也能够适应差异。并且实现任务调度的同时,支持有状态任务的持久化,并发控制和超时控制。
一个任务系统的整体设计
一个完善的任务系统包含任务管理模块和任务调度模块。
任务管理负责任务的创建、启动、停止、删除、拉取状态、拉取分析数据等操作,多类型的任务是可以共用的。
任务调度负责任务限频、具体的业务执行、结果处理等流程,不同任务的类型的调度模块无法共用。
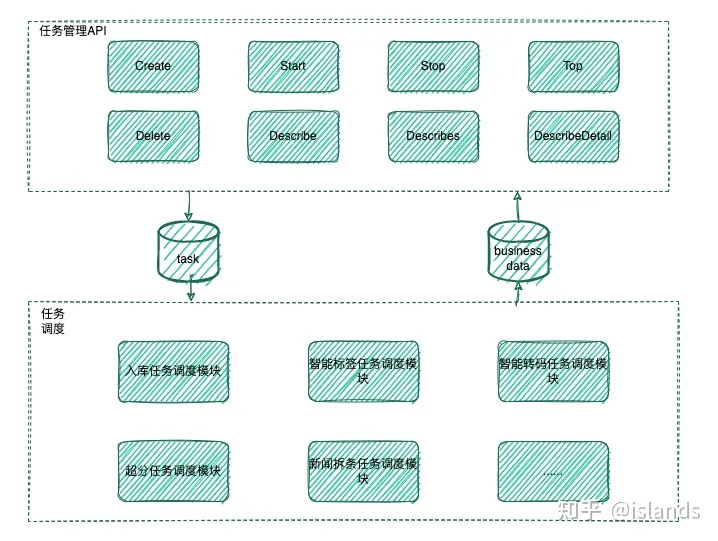
任务调度框架
作者一直想实现一个通用的任务管理框架,但是长时间陷入了应该如何存储任务的纠结境地:
- 存 DB 可以满足异步任务需要可持久化,有状态的需求,但是需要轮询DB,性能上满足不了大流量场景。
- 用 Kafka、内存等队列的方式存取任务,性能上很好,但是任务无状态,不能满足任务有状态的场景。
经过长时间的对比不同类型任务的执行流程,发现这些任务在大的流程上没有区别,细节上差别很大。最终,发现一个任务系统可以抽象成为三部分
- 任务容器——用来存储任务相关数据。
- 任务执行器——真正的执行任务的逻辑。
- 任务调度器——对任务容器和任务执行器进行一些逻辑操作和逻辑配合,完成整体的任务调度流程。
其中,容器和执行器和业务相关、可以用一系列的接口(interface)来抽象,开发者根据自己的业务实现接口。任务调度流程比较估计,可以由框架实现。
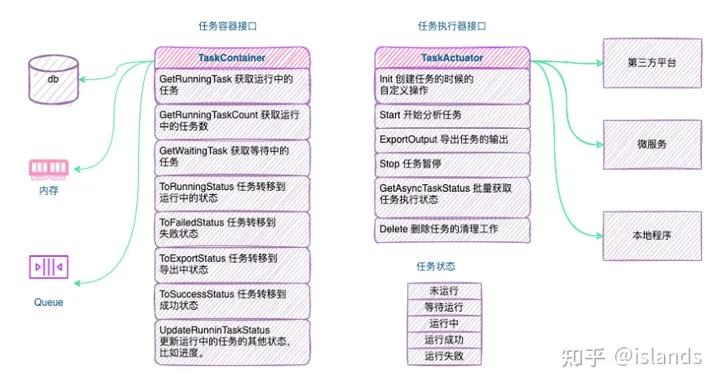
基于抽象的容器和执行器,固定的任务调度和执行的流程如下图

主要分成两个主线程
- 维护任务状态线程:主要负责感知运行中的任务执行情况,状态的转移,以及运行成功后结果的导出过程(资源转存、数据落库等)。
- 调度线程:负责对等待中的任务进行限频和调度。
总结下来,整体的设计思想是通过抽象出任务容器和任务执行器接口来实现调度流程的共享。
开发者只需要实现自己的任务容器接口和任务执行器接口,用任务容器和任务执行器创建任务调度器,即可轻易的实现任务调度。该框架可以支持多副本的调度器,如果使用关系型 db 作为容器,注意使用 db 的原子性防止任务重复调度。
任务容器分类
任务根据不同的维度,任务可以分成
1. 同步任务和异步任务
本框架主要实现了任务异步化,可以轻易的通过执行器的实现把同步任务转换成异步任务。注意:实现同步任务执行器的时候,不要阻塞 Start 方法,而是在单独的协程执行任务。
2. 可持久任务和不可持久化任务
任务的是否可持久化,通俗来说,就是任务执行完成以后,是否还能查询到任务相关的信息和记录。
- 不可持久化任务——比如存储在内存队列里面的任务,执行完成以后,或者服务宕机、重启以后,任务相关的数据消失,无迹可寻。
- 可持久化任务——一般是存储在 DB 里面的任务。
根据是否可持久化,我们继续对任务容器抽象,分成两类任务容器:
- MemeoryContainer——内存型任务容器,优点:可以快读快写,缺点:不可持久化。MemeoryContainer 实际上是可以和业务无关的,所以框架预置了三种MemeoryContainer——queueContainer,orderedMapContainer,redisContainer。
- queueContainer:queueContainer 队列型容器,任务无状态,无优先级,先进先出,任务数据,多进程数据无法共享数据
- orderedMapContainer:OrderedMap 作为容器,支持任务优先级,多进程数据无法共享数据
- redisContainer:redis 作为容器,支持任务优先级,并且可以多进程,多副本共享数据
- PersistContainer——可持久化任务容器,优点:可持久化存储,缺点:依赖db、需要扫描表,对 db 压力比较大。开发者可以参考exampleSQLContainer 实现自己的 SQLContainer,修改数据表的结构。
由于 MemeoryContainer 和 PersistContainer 各有优缺点,如果可以组合两种容器,生成一种新的任务容器combinationContainer,既能够通过内存实现快写快读,又能够通过DB实现可持久化。

例子
使用内存容器实现 a+b 任务调度
有一个计算 a+b 的服务,由于该 a+b 是一种新的高维空间的计算规则,计算非常耗时耗资源,所以该服务设计成为异步的。该服务主要有三个接口
- /add, 输入 a, b,返回 taskId。
- /status,输入 taskId, 返回该任务的状态,是否已经完成,或者计算失败。
- /result,输入 taskId,如果任务已经完成,返回计算结果。
服务代码参考 add_service.go。
现在我们通过本任务调度框架实现一个 a+b 任务调度系统,可以控制任务并发数,并且按照队列依次调度。
实现 a+b 任务执行器
首先,需要实现一个 a+b 任务的执行器,执行器实际上就是调用 a+b 服务的接口。执行器的实现参考example_actuator.go
实现 a+b 任务容器
这里,我们直接使用队列来作为任务容器,所以可以直接用框架预置的 queueContainer 作为任务容器,无需单独实现。
实现调度
参考代码main.go
// 构建任务容器,队列长度 10000
container := memeorycontainer.MakeQueueContainer(10000, 100*time.Millisecond)
// 构建任务执行器
actuator := actuator.MakeExampleActuator()
// 构建调度器,自动开启调度
sch := lighttaskscheduler.MakeNewScheduler(
context.Background(),
container, actuator,
lighttaskscheduler.Config{
TaskLimit: 5, // 任务并发限制
ScanInterval: 100*time.Millisecond, // 系统扫描轮询周期,内存容器可以快速扫描,如果是 db 容器要注意配置合理的扫描间隔,防止对 db 造成比较大压力。
})
// 添加任务
for i := 0; i < 1000; i++ {
sch.AddTask(context.Background(),
lighttaskscheduler.Task{
TaskId: strconv.Itoa(i), // 每个任务都需要绑定一个唯一 id
TaskItem: task.ExampleTask{
TaskId: uint32(i),
A: r.Int31() % 1000,
B: r.Int31() % 1000,
},
})
}任务流
该任务框架已经实际投入到项目中稳定生产了很长时间。基于上面的任务调度,可以轻易的实现一个任务流以及其调度。任务流部分的代码脱敏以后,后续也会开源。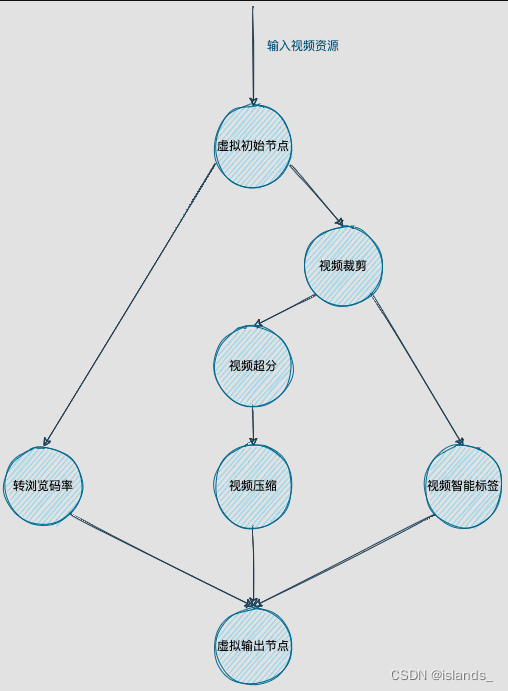









![[渗透教程]-013-网络实体标识及网络监听](https://img-blog.csdnimg.cn/img_convert/a418c6f8f4a3c6eb43a0c5580d3ea7b3.jpeg)