前言
对于Kafka来说,分为几个阶段,一个是消息的生产请求,以及对应的消息的消费请求。一个是生产者发送到Broker,另一个是消费者通过pull的方式 请求Broker,那么Broker是如何处理这几个请求的。细分下来主要常见的是如下,所有的请求都是通过 TCP 网络以 Socket 的方式进行通讯的。
- PRODUCE用于生产消息
- FETCH用于消费消息
- METADATA用户请求Kafka集群元数据信息
请求方式
顺序处理请求
while (true) {
Request request = accept(connection);
handle(request);
}
缺点是系统的吞吐量差,只适用于请求量不高的系统。
多线程处理
while (true) {
Request = request = accept(connection);
Thread thread = new Thread(() -> {
handle(request);});
thread.start();
}
为每个请求创建一个Thread 进行异步处理,但是频繁的创建Thread对系统的资源消耗比较好,并且没有池化。
Reactor模式
Reactor是事件驱动架构的一种实现方式,应用常见针对于大量客户端请求服务端的情况,比如Netty就是Reactor
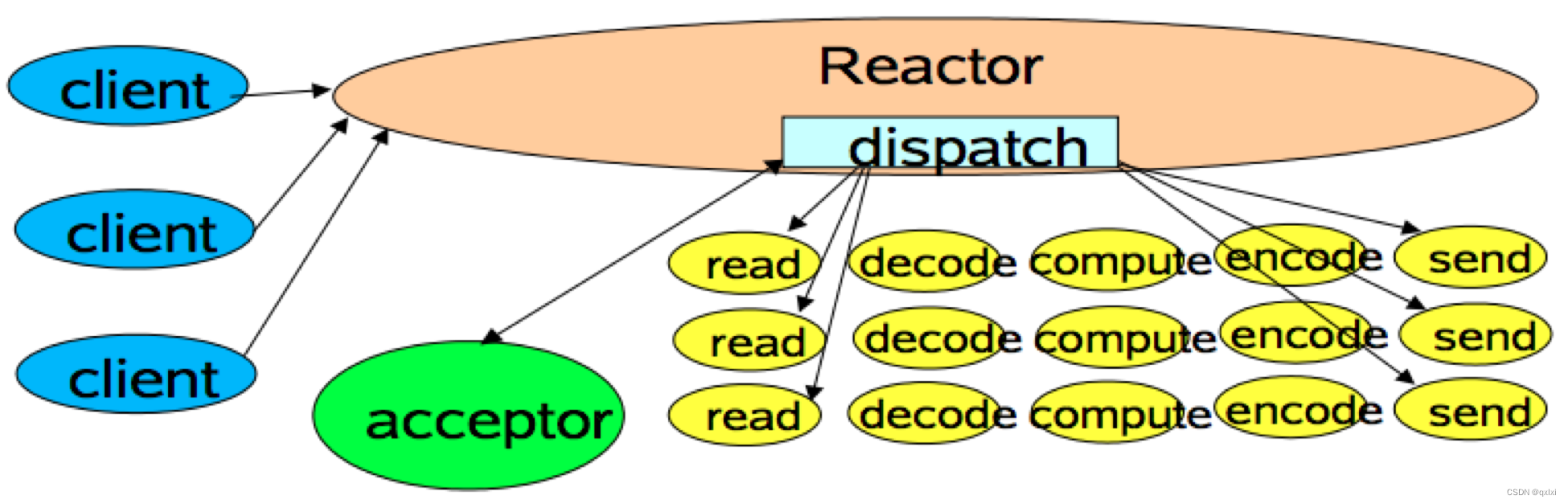
从上图可以看到多个客户端请求服务端,其中有一个分发器,acceptor进行请求的转发,具体的逻辑处理则交给不同的work工作线程处理,这种好处就是可以很好的将请求转发和具体的业务逻辑处理相耦合。
Kafka Reactor原理详解
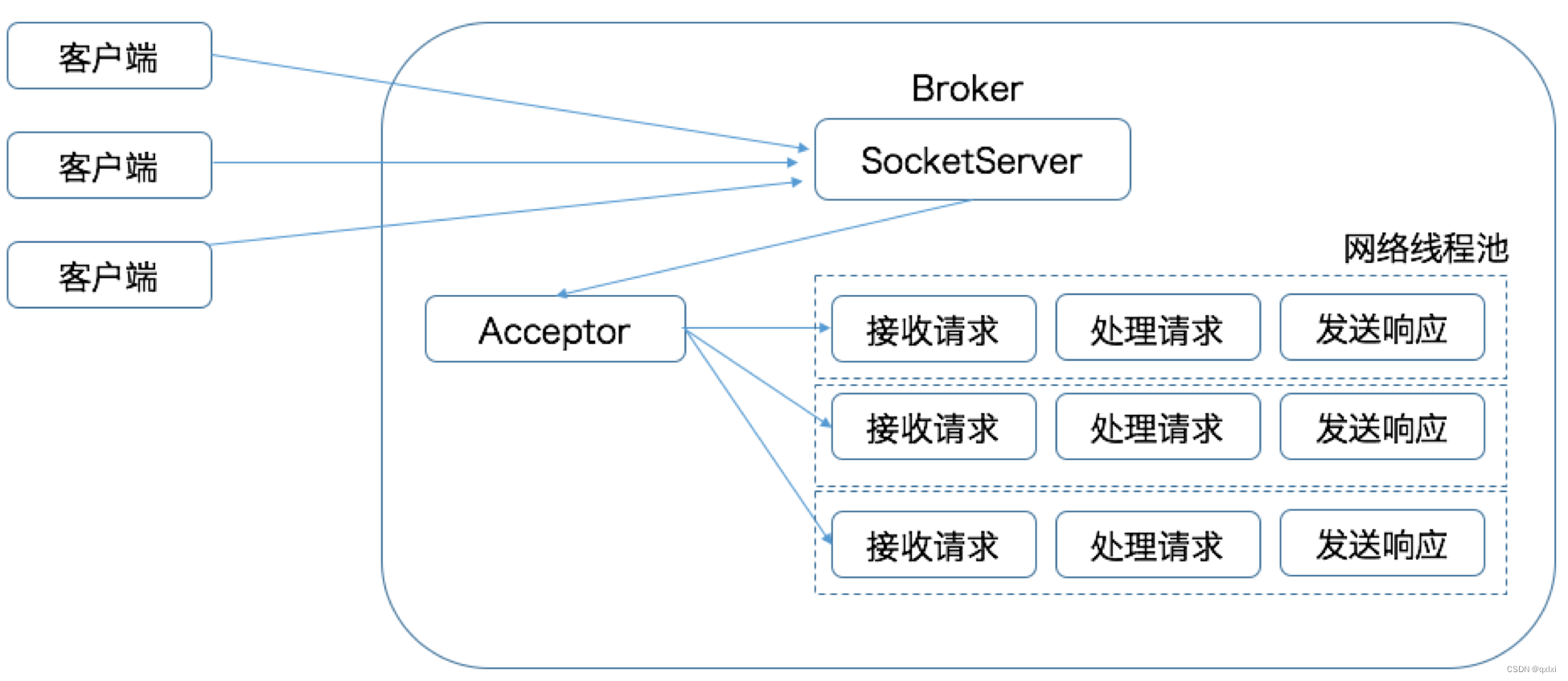
这就是Kafka类似的Reactor模式的图,可以看到请求到Broker后,也会通过类似于请求转发的组件Acceptor转发到对应的工作线程上,但是Kafka中被称为网络线程池,一般默认每个Broker上为3个工作线程,可以通过参数 num.network.threads 进行配置。并且采用轮询的策略,可以很均匀的将请求分发到不同的网络线程中进行处理。
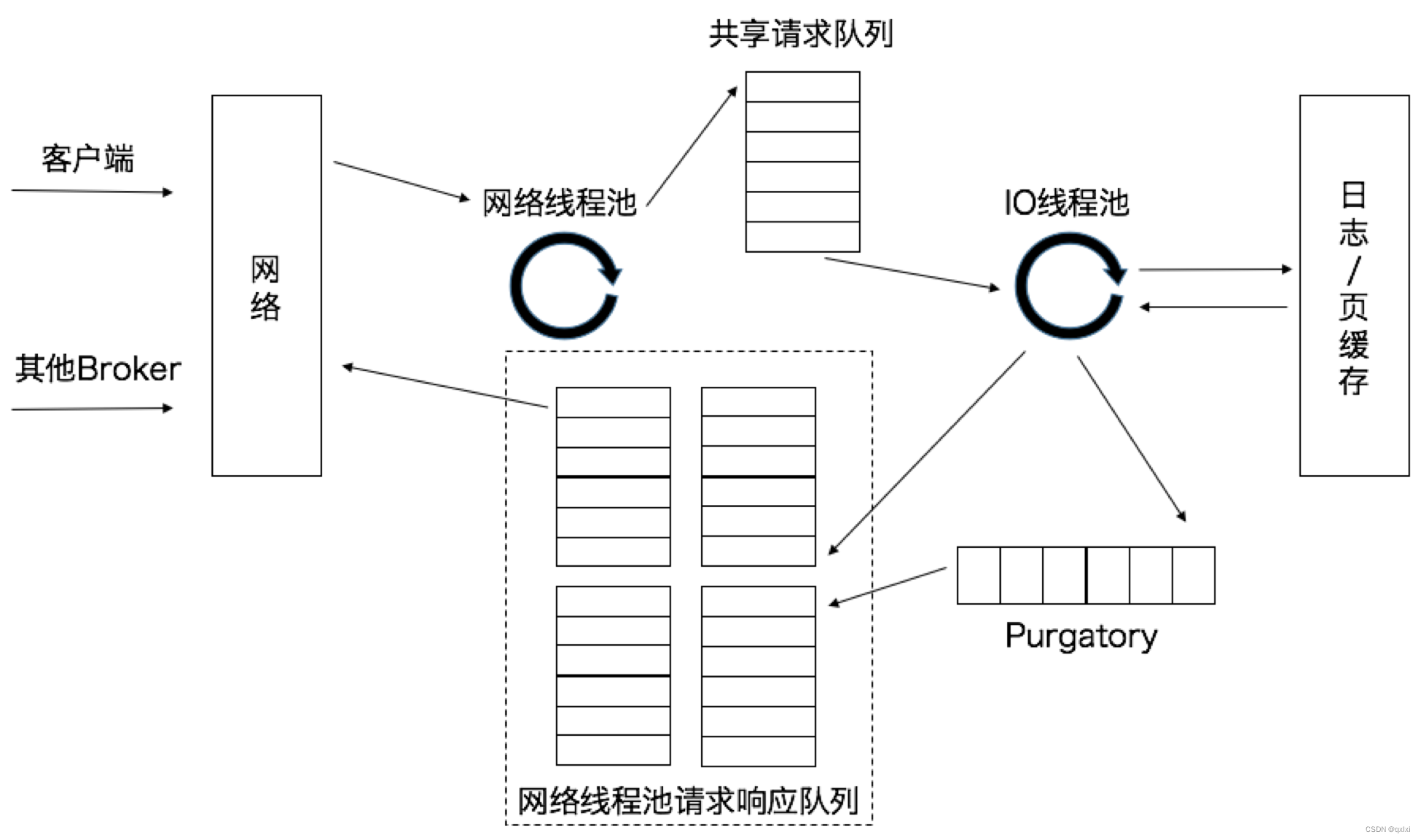
但是实际的处理请求并不是由网络线程池进行处理的,而是会交给后续的IO线程池,当网络线程接受到请求的时候,会将请求写入到共享的请求队列中,而IO线程池会进行异步的处理,默认情况下是8个,可以通过 num.io.threads 进行配置。
IO线程池会进行判断,如果是PRODUCT请求,则将消息写入到底层的磁盘日志文件中,如果是FETCH请求,则会从日志或者页缓存中读取到消息,这个时候会将请求写入到请求响应队列中。
细心的朋友可能发现了请求队列是共享的,但是请求响应队列确实非共享的,这是因为请求队列只是转发,而响应队列需要根据不同的请求,返回其对应的结果值,比如请求A返回的是成功,而请求B返回的是失败。A和B的响应结果不能融合在一起。
缓存延时请求: 之前文章中提到过,请求的时候可能ack=All 那么这个时候比如A生产者发送了1条消息,有三个Broker,对应三个副本,那么必须所有Broker都返回成功后(也就是ISR),才可以将请求返回给生产者,这个时候就需要将请求暂存到Purgatory中,等到所有副本都成功之后,才返回请求给客户端。
控制与数据请求分离
说到这里,我们了解到其实Kafka内部有两类请求,一类是数据类请求,PRODUCT和FETCH。以及控制类请求 元数据的操作,leader 副本的选举的等都属于控制类请求。控制类请求可能导致数据类请求数据失效。
我们举一个极端的情况下,比如一个Topic有两个Broker,Broker1是Leader副本,Broker0是follower副本,Leader副本积压了很多的PRODUCT消息,但是当我们强制将follower副本变更为Leader副本的时候,Kafka内部控制器会发送LeaderAndISR请求给Leader副本告诉它不是leader,而是follower副本,这个时候如果在提交LeaderAndISR之前的PRODUCT可能就处理不了,一直在Purgatory中不断重试。直至超时失败。如果可以很好的将控制类请求和数据类请求分离开,那么可以很好的解决这个问题。
解决方案
一般遇到这种问题,我们可能尝试使用优先级队列进行解决,但是当队列满了之后没办法保证后续被拒绝的请求优先级。
社区如何解决的呢,其实采用了一套完全和上述图中的流程,只不过是后台异步执行的。
复盘
本篇文章,主要接受了请求方式以及Kafka内部的实现机制,其中Acceptor线程、网络线程池、IO线程池、Purgatory组件是构成处理请求的核心模块。