前言
前言
推断因果性和分析异质性是统计学家在处理混杂任务中的圣杯。传统且主流的方法有:倾向性评分、分层分享、比例风险模型等。新的方法也有很多,代表就是:因果随机森林。这种算法,浅看难度一般,深入探索发现坑还是很多的。这篇博客不对算法做深入探讨,仅仅是我在阅读文献中发现确定森林模型的树木数量参数 the number of trees 这个任务,所谓研究因果森林的grf包中未能提及,因此,我对针对这个任务进行部分很浅的工作。
不过,私以为,这个参数是极为重要的,默认因果森林中是2000,而且内部提供了turn.para来直接优化参数,我认为,在一般情况下,不改其实也很ok的。2000真的很大了,一般错误率都稳定了。但是,各位研究牲们,发学术文章,扪心自问,感觉还是要有一张图,才好交差吧?
且看这篇文章中的图2,他就是一张"渐进图"来确定出最合理的树的数量。
其中,y轴是Median prediction variances x轴是 the number of trees.
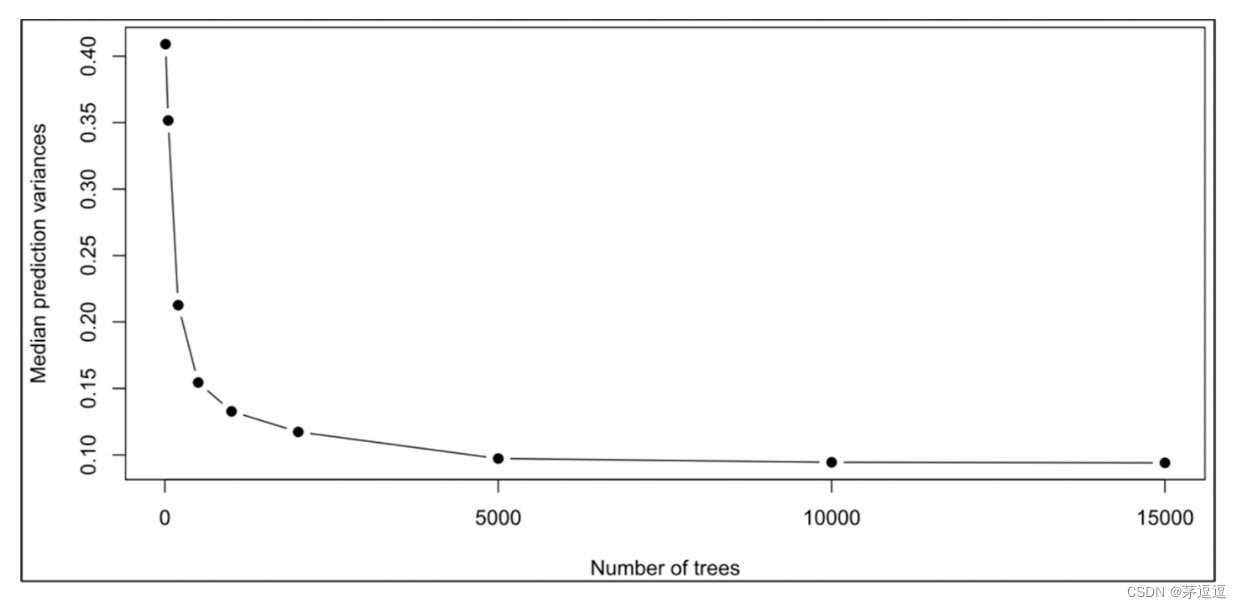
prediction varianc
![[Golang] Go语言基础一知半解??这些你容易忽视的知识点(第一期)](https://img-blog.csdnimg.cn/16222406e454480d8e866adc92cd54c9.png)