select customer_id,first_name,last_name from customer where customer_id=14;
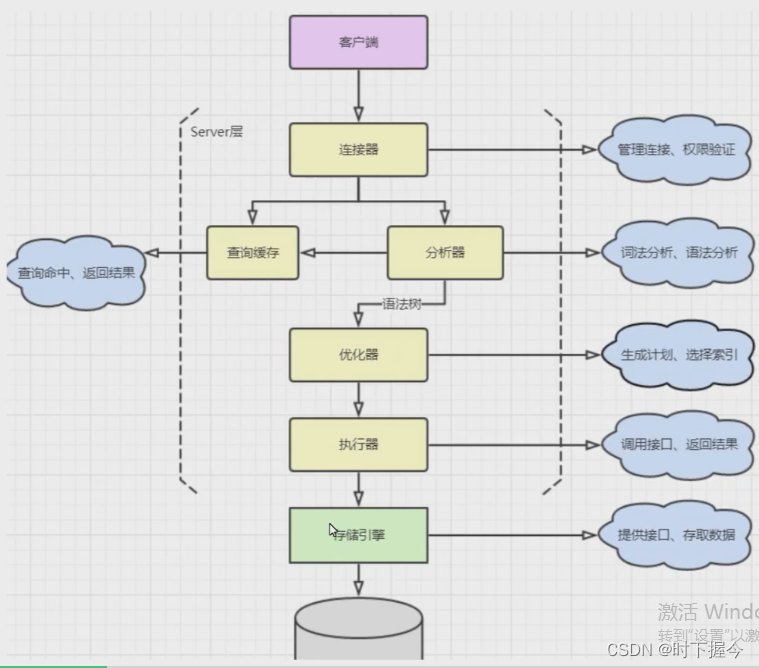
- 先连接到数据库,连接器 负责跟客户端建立连接、获取权限、维持和管理连接。
客户端再次发送请求,就会使用同一个连接,客户端如果长时间没动静,就会断开该链接。
查看连接的状态:
show processlist
sleep表示现在系统中有一个空闲链接
查看连接的保持时间:
SHOW VARIABLES LIKE ‘wait_timeout’;
不过,每个连接对象中都有一块临时内存,用来管理运行过程中的数据,长时间保持连接,会使内存涨得快 - MySQL Server 接收到这个查询请求后,先到 查询缓存器 查看,之前是否执行过这条语句。之前执行过的语句及其结果会以 key-value 对的形式,被直接缓存在内存中。key 是查询的语句hash之后的值,value是查询的结果。
查询缓存的失效非常频繁,只要有对一个表的更新,这个表上所有的查询缓存都会被清空。
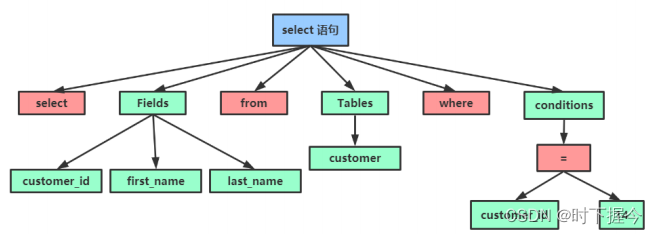
MySQL 8.0 版本直接将查询缓存的整块功能删掉了。 - 没有命中缓存,分析器 将客户端提交的一段SQL文本拆分成词,并识别每个词代表什么
select,customer_id,first_name,last_name,from,customer,where,customer_id,
=,14
如果SQL语句词法分析没有问题,就会根据词法分析的结果,对SQL语句进行语法分析,最后生成解析树
预处理器进一步对解析树检查,检查表名、字段是否存在、用户对表的操作权限,最后重新生成一个新的解析树
- 优化器 根据解析树生成 执行计划,并基于最小成本模型,从中选择一个最优执行计划。所谓最小成本模型,即IO开销和CPU开销之和最小。例如:一条Select语句用到了主键索引 和 非主键索引,那么主键索引就是最优的执行计划,因为非主键索引会有一次回表操作,回表操作会增加IO开销和CPU开销
- MySQL 通过分析器知道了你要做什么,通过优化器知道了该怎么做,得到了一个查询计划。于是就进入了执行器阶段,开始执行语句。执行器根据表的引擎定义,调用引擎提供的查询接口,提取数据。
假设customer_id 字段不是索引,select语句也没有用到索引,这时查询只能全表扫描。那么执行器的执行流程是这样的:
- 调用 InnoDB 引擎接口取这个表的第一行,判断customer_id 值是不是 14,如果不是则跳过,如果是则将这行缓存在结果集中;
- 调用引擎接口取“下一行”,重复相同的判断逻辑,直到取到这个表的最后一行。
- 执行器将上述遍历过程中所有满足条件的行组成的结果集返回给客户端。
至此,这个语句就执行完成了
Select语句在MySQL逻辑结构Service层的执行流程,如下图: