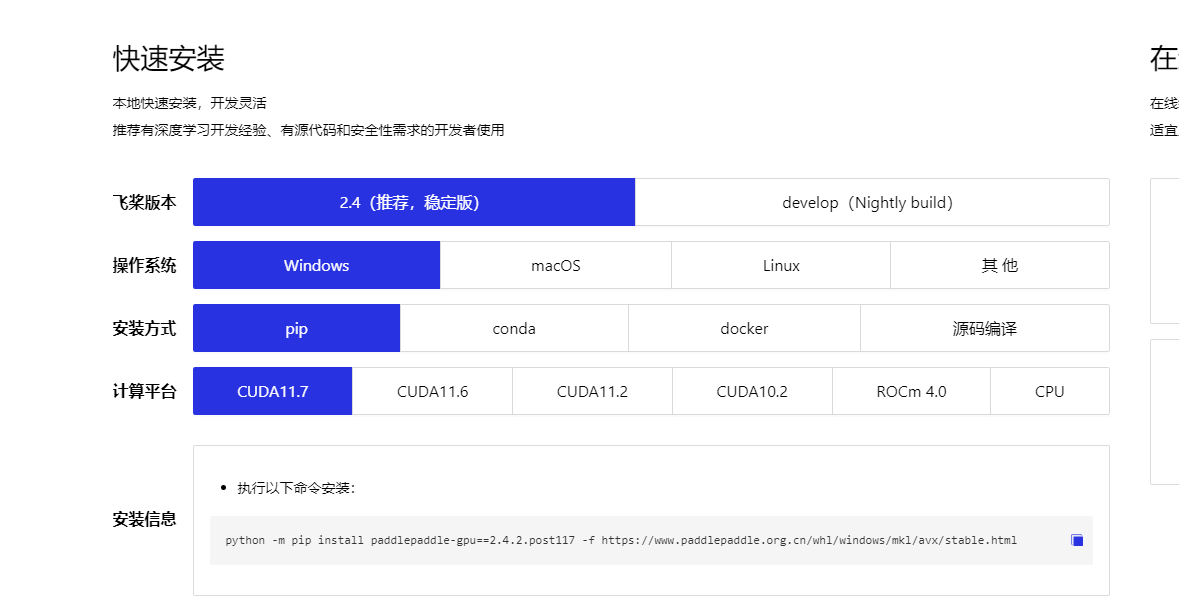
JCTools 是适用于 JVM 并发开发的工具,主要提供了一些 JDK 确实的并发数据结构,例如非阻塞 Map、非阻塞 Queue 等。其中非阻塞队列可以分为四种类型,可以根据不同的场景选择使用。
- Spsc 单生产者单消费者
- Mpsc 多生产者单消费者
- Spmc 单生产者多消费者
- Mpmc 多生产者多消费者
Netty 中直接引入了 JCTools 的 Mpsc Queue
文章目录
- 1.Mpsc Queue介绍
- 2.Mpsc Queue 源码分析
- 2.1 使用实例
- 2.2 入队 offer()
- 2.3 出队 poll()
- 3.总结
1.Mpsc Queue介绍
Mpsc 的全称是 Multi Producer Single Consumer, 多生产者单消费者。
Mpsc Queue 可以保证多个生产者同时访问队列是线程安全的, 而且同一时刻只允许一个消费者从队列中读取数据, Netty Reactor 线程中任务队列 taskQueue 必须满足多个生产者可以同时提交任务, 所以 JCTools 提供的 Mpsc Queue 非常适合 Netty Reactor 线程模型。
Mpsc Queue 有多种的实现类, MpscArrayQueue, MpscUnboundedArrayQueue, MpscChunkedArrayQueue
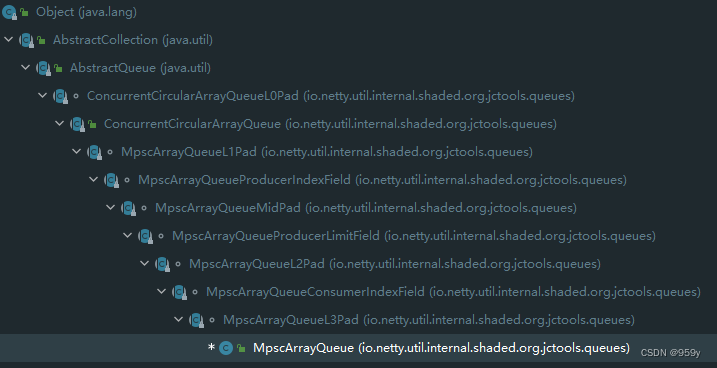
MpscArrayQueue 继承了MpscXxxPad 和 MpscXxxField。每个有包含属性的类后面都会被 MpscXxxPad 类隔开。
// ConcurrentCircularArrayQueueL0Pad
long p01, p02, p03, p04, p05, p06, p07;
long p10, p11, p12, p13, p14, p15, p16, p17;
// ConcurrentCircularArrayQueue
protected final long mask;
protected final E[] buffer;
// MpmcArrayQueueL1Pad
long p00, p01, p02, p03, p04, p05, p06, p07;
long p10, p11, p12, p13, p14, p15, p16;
// MpmcArrayQueueProducerIndexField
private volatile long producerIndex;
// MpscArrayQueueMidPad
long p01, p02, p03, p04, p05, p06, p07;
long p10, p11, p12, p13, p14, p15, p16, p17;
// MpscArrayQueueProducerLimitField
private volatile long producerLimit;
// MpscArrayQueueL2Pad
long p00, p01, p02, p03, p04, p05, p06, p07;
long p10, p11, p12, p13, p14, p15, p16;
// MpscArrayQueueConsumerIndexField
protected long consumerIndex;
// MpscArrayQueueL3Pad
long p01, p02, p03, p04, p05, p06, p07;
long p10, p11, p12, p13, p14, p15, p16, p17;
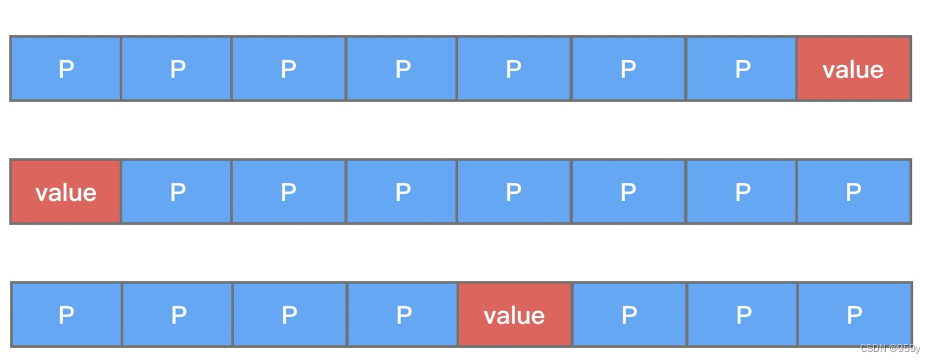
MpscXxxPad 类中使用了大量 long 类型的变量, 是为了解决伪共享(false sharing)问题。
Mpsc Queue 采取了空间换时间的策略, 让不同线程共享的对象加载到不同的缓存行。
public class FalseSharingPadding {
protected long p1, p2, p3, p4, p5, p6, p7;
protected volatile long value = 0L;
protected long p9, p10, p11, p12, p13, p14, p15;
}
变量 value 前后都填充了 7 个 long 类型的变量, 可以保证在多线程访问 value 变量时, value 与其他不相关的变量处于不同的 Cache Line。
2.Mpsc Queue 源码分析
MpscArrayQueue 属性
// ConcurrentCircularArrayQueue
protected final long mask; // 计算数组下标的掩码
protected final E[] buffer; // 存放队列数据的数组
// MpmcArrayQueueProducerIndexField
private volatile long producerIndex; // 生产者的索引
// MpscArrayQueueProducerLimitField
private volatile long producerLimit; // 生产者索引的最大值
// MpscArrayQueueConsumerIndexField
protected long consumerIndex; // 消费者索引
mask 变量表明队列中数组的容量大小肯定是 2 的次幂, Mpsc 是多生产者单消费者队列, 所有producerIndex 和 producerLimit 都是volatile修饰, 其中一个生产者线程的修改需要对其他生产者线程可见
2.1 使用实例
public class MpscArrayQueueTest {
public static final MpscArrayQueue<String> MPSC_ARRAY_QUEUE = new MpscArrayQueue<>(2);
public static void main(String[] args) {
for (int i = 1; i <= 2; i++) {
int index = i;
new Thread(() -> MPSC_ARRAY_QUEUE.offer("data" + index), "thread" + index).start();
}
try {
Thread.sleep(1000L);
MPSC_ARRAY_QUEUE.add("data3"); // 入队操作,队列满则抛出异常
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("队列大小:" + MPSC_ARRAY_QUEUE.size() + ", 队列容量:" + MPSC_ARRAY_QUEUE.capacity());
System.out.println("出队:" + MPSC_ARRAY_QUEUE.remove()); // 出队操作,队列为空则抛出异常
System.out.println("出队:" + MPSC_ARRAY_QUEUE.poll()); // 出队操作,队列为空则返回 NULL
}
}
java.lang.IllegalStateException: Queue full
at java.util.AbstractQueue.add(AbstractQueue.java:98)
at MpscArrayQueueTest.main(MpscArrayQueueTest.java:17)
队列大小:2, 队列容量:2
出队:data1
出队:data2
Disconnected from the target VM, address: '127.0.0.1:58005', transport: 'socket'
入队 offer()和出队 poll()
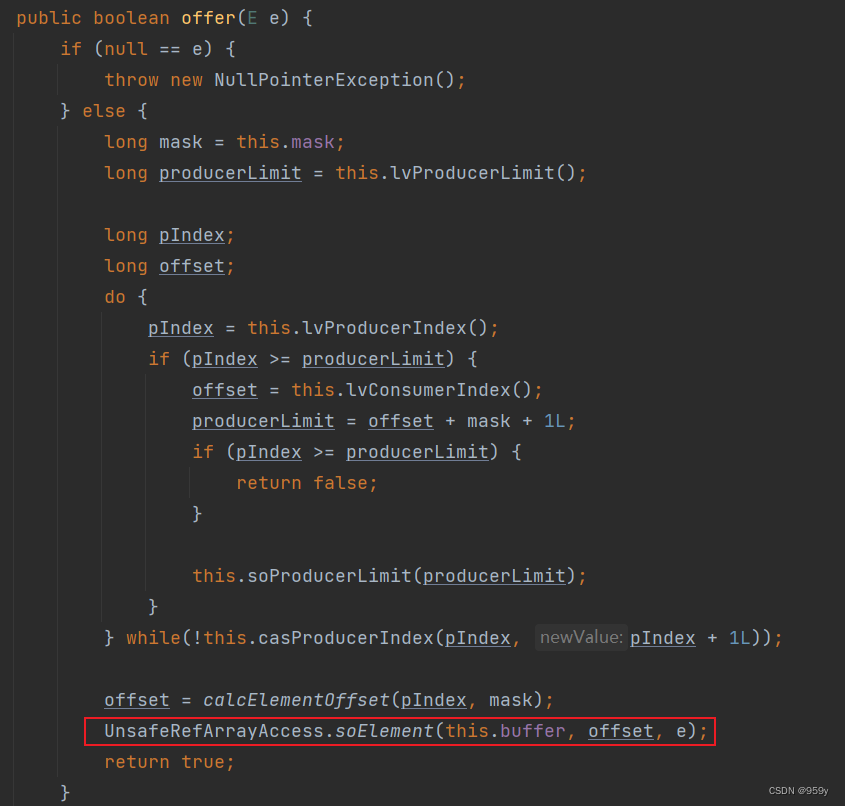
2.2 入队 offer()
public boolean offer(E e) {
if (null == e) {
throw new NullPointerException();
} else {
long mask = this.mask;
long producerLimit = this.lvProducerLimit(); // 获取生产者索引最大限制
long pIndex;
long offset;
do {
pIndex = this.lvProducerIndex(); // 获取生产者索引
if (pIndex >= producerLimit) {
offset = this.lvConsumerIndex(); // 获取消费者索引
producerLimit = offset + mask + 1L;
if (pIndex >= producerLimit) {
return false; // 队列已满
}
this.soProducerLimit(producerLimit); // 更新 producerLimit
}
} while(!this.casProducerIndex(pIndex, pIndex + 1L)); // CAS 更新生产者索引,更新成功则退出,说明当前生产者已经占领索引值
offset = calcElementOffset(pIndex, mask); // 计算生产者索引在数组中下标
UnsafeRefArrayAccess.soElement(this.buffer, offset, e); // 向数组中放入数据
return true;
}
}
producerIndex、producerLimit 以及 consumerIndex 之间的关系
public MpscArrayQueueProducerLimitField(int capacity) {
super(capacity);
this.producerLimit = capacity;
}
protected final long lvProducerLimit() {
return producerLimit;
}
初始化状态, producerLimit 队列的容量是相等的, producerIndex = consumerIndex = 0。接下来 Thread1 和 Thread2 并发向 MpscArrayQueue 中存放数据。
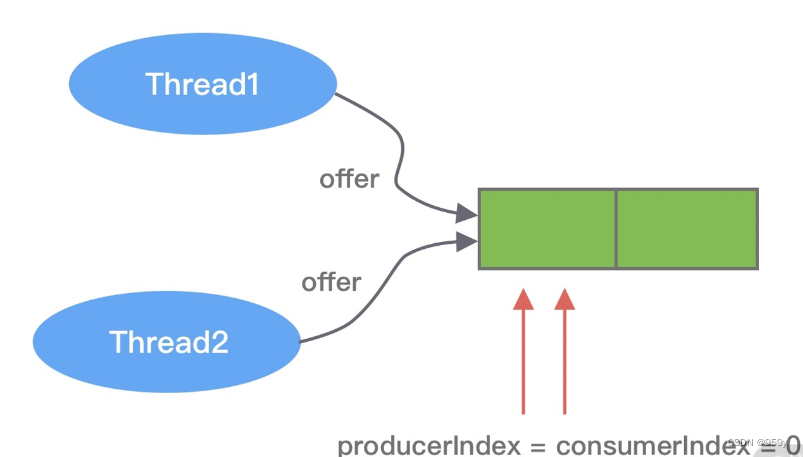
两个线程此时拿到的 producerIndex 都是 0, 小于 producerLimit, 此时两个线程都会尝试使用 CAS 操作更新 producerIndex, 一个成功, 一个失败。
假设 Thread1 执行 CAS 操作成功, Thread2失败会重新更新producerIndex。
Thread1 更新后 producerIndex 的值为 1, 由于 producerIndex 是 volatile 修饰的, 对于Thread2 可见, 当 Thread1 和 Thread2 都通过 CAS 抢占成功后, 拿到的 pIndex 分别是 0 和 1, 根据 pIndex 进行位运算计算得到数组对应的下标, 然后通过 UNSAFE.putOrderedObject() 方法将数据写入到数组中。
public static <E> void soElement(E[] buffer, long offset, E e) {
UnsafeAccess.UNSAFE.putOrderedObject(buffer, offset, e);
}
putOrderedObject() 不会立刻将数据更新到内存中, 并把其他 Cache Line 置为失效, 使用的是LazySet 延迟更新机制。性能比putObject() 高。
Java 中有四种类型的内存屏障, LoadLoad、StoreStore、LoadStore 和 StoreLoad, putOrderedObject() 使用了 StoreStore, 对于 Store1,StoreStore,Store2 这样的操作序列, 在 Store2 进行写入之前, 会保证 Store1 的写操作对其他处理器可见。
LazySet 机制是有代价的, 是写操作结果有纳秒级的延迟, 不会立刻被其他线程以及自身线程可见。在Mpsc Queue的使用场景中, 多个生产者只负责写入数据, 并没有写入之后立刻读取的需求, 所以使用 LazySet 机制是没有问题的, 只需StoreStore Barrier 保证多线程写入的顺序即可。
对于 do-while 循环内的逻辑, 为什么需要两次 if(pIndex >= producerLimit) 判断呢, 说明当生产者索引大于 producerLimit 阈值时, 可能存在 1> producerLimit 缓存值过期了或者队列已经满了, 需要读取最新的消费者索引 consumerIndex, 重新做一次 producerLimit 计算, 2> 生产者索引还是大于 producerLimit 阈值, 说明队列的真的满了。
因为生产者有多个线程, 所以 MpscArrayQueue 采用了 UNSAFE.getLongVolatile() 方法保证获取消费者索引 consumerIndex 的准确性。
getLongVolatile() 使用了 StoreLoad Barrier, 在 Load2 以及后续的读取操作之前, 会保证 Store1 的写入操作对其他处理器可见。
StoreLoad 是四种内存屏障开销最大的, 引入producerLimit 的好处在于, 假设我们的消费速度和生产速度比较均衡的情况下, 差不多走完一圈数组才需要获取一次消费者索引 consumerIndex, 从而减少了getLongVolatile() 方法的使用次数。
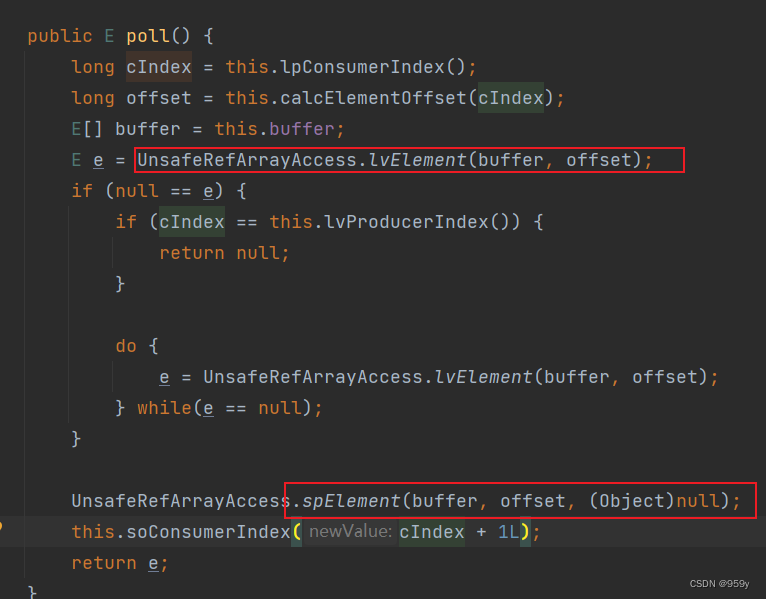
2.3 出队 poll()
移除队列的首个元素并返回, 如果队列为空, 返回Null
public E poll() {
long cIndex = this.lpConsumerIndex(); // 直接返回消费者索引 consumerIndex
long offset = this.calcElementOffset(cIndex); // 计算数组对应的偏移量
E[] buffer = this.buffer;
E e = UnsafeRefArrayAccess.lvElement(buffer, offset); // 取出数组中 offset 对应的元素
if (null == e) {
if (cIndex == this.lvProducerIndex()) { // 队列为空
return null;
}
do {
e = UnsafeRefArrayAccess.lvElement(buffer, offset);
} while(e == null); // 等待生产者填充元素
}
UnsafeRefArrayAccess.spElement(buffer, offset, (Object)null); // 消费成功后将当前位置置为 NULL
this.soConsumerIndex(cIndex + 1L); // 更新 consumerIndex 到下一个位置
return e;
}
只有一个消费者线程, 所以么有CAS操作, 核心思路是获取消费者索引 consumerIndex, 然后根据 consumerIndex 计算得出数组对应的偏移量, 将数组对应位置的元素取出并返回, 最后将 consumerIndex 移动到环形数组下一个位置。
public static <E> E lvElement(E[] buffer, long offset) {
return (E) UNSAFE.getObjectVolatile(buffer, offset);
}
getObjectVolatile() 方法则使用的是 LoadLoad Barrier, 对于 Load1, LoadLoad, Load2 来说, 在 Load2 以及后续读取操作之前, Load1读取操作执行完毕。所以 getObjectVolatile() 方法可以保证每次读取数据都可以从内存中拿到最新值。
当调用 lvElement() 方法获取到的元素为 NULL 时,
- 队列为空或者生产者填充的元素还没有对消费者可见。
- 如果消费者索引 consumerIndex 等于生产者 producerIndex, 说明队列为空。
- 只要两者不相等, 消费者需要等待生产者填充数据完毕。
当成功消费数组中的元素之后, 把当前消费者索引 consumerIndex 的位置置为 NULL, 把 consumerIndex 移动到数组下一个位置。
public static <E> void spElement(E[] buffer, long offset, E e) {
UNSAFE.putObject(buffer, offset, e);
}
protected void soConsumerIndex(long newValue) {
UNSAFE.putOrderedLong(this, C_INDEX_OFFSET, newValue);
}
putObject() 不会使用任何内存屏障, 会直接更新对象对应偏移量的值。而 putOrderedLong 与 putOrderedObject() 是一样的, 都使用了 StoreStore Barrier。
3.总结
- 通过大量填充 long 类型变量解决伪共享问题
- 环形数组的容量设置为 2 的次幂,可以通过位运算快速定位到数组对应下标
- 入队 offer() 操作中 producerLimit 的巧妙设计,大幅度减少了主动获取消费者索引 consumerIndex 的次数,性能提升显著
- 入队和出队操作中都大量使用了 UNSAFE 系列方法,针对生产者和消费者的场景不同,使用的 UNSAFE 方法也是不一样的。Jctools 在底层操作的运用上也是有的放矢,把性能发挥到极致




![[网络原理] 详解Cookie与Session](https://img-blog.csdnimg.cn/410357148cd74a068872b6481bf8fb4e.png)