引言
低功耗设计关乎ASIC芯片的性能稳定。对ASIC 特别是一些Soc芯片的设计有着重要的影响,随着集成规模的大幅度增加,芯片自身的功耗问题暴露也越来越明显。低功耗设计的需求和必要性也越来越值得关注。本文就《Low Power Methodology Manual For System-on-Chip Design》 书籍的学习,记录一下低功耗设计的理论知识。
参考
【1】Michael Keating • David Flynn •Robert Aitken Alan G • ibbons • Kaijian Shi. Low Power Methodology Manual For System-on-Chip Design
前文链接:
低功耗设计方法学——篇Ⅰ
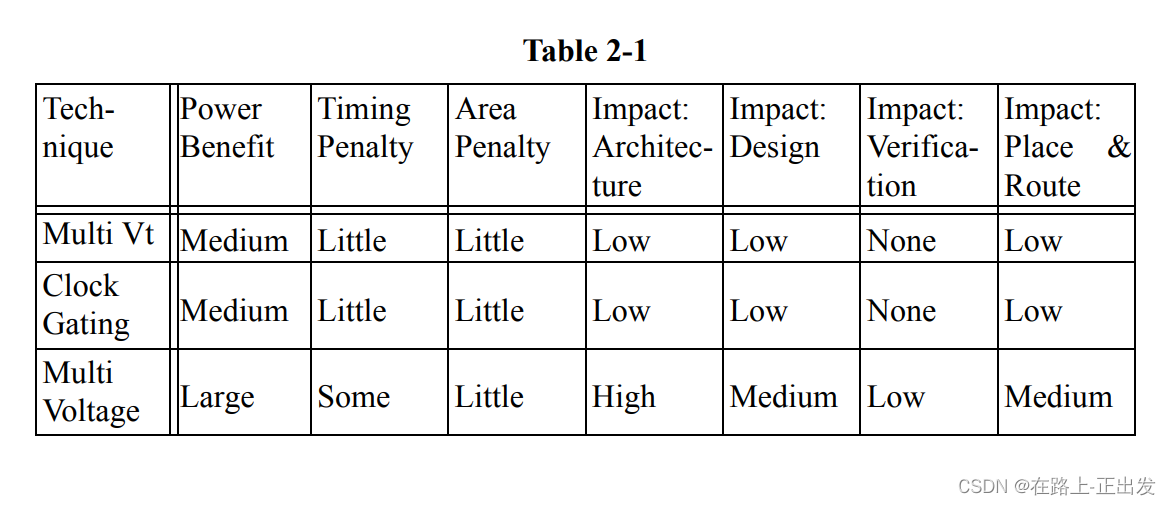
有许多功率降低方法已经使用了一段时间,并且是成熟的技术。本章介绍了其中一些低功耗设计方法:
• 时钟门控
• 门级功率优化
• 多VDD
• 多VT
时钟门控
芯片中动态功率的很大一部分在时钟的分配网络中。高达50%甚至更多的动态功率可以花费在时钟缓冲器中。这一结果具有直观意义,因为这些缓冲器在系统中具有最高的切换速率,有很多,并且它们通常具有高驱动强度,以最大限度地减少时钟延迟。此外,即使输入和输出保持不变,接收时钟的触发器也会消耗一些动态功率。
减少这种功率的最常见方法是在不需要时钟时关闭时钟。这种方法被称为时钟门控。
现代设计工具支持自动时钟门控:它们可以在不改变逻辑功能的情况下识别可以插入时钟门控的电路。下图显示了这是如何工作的。
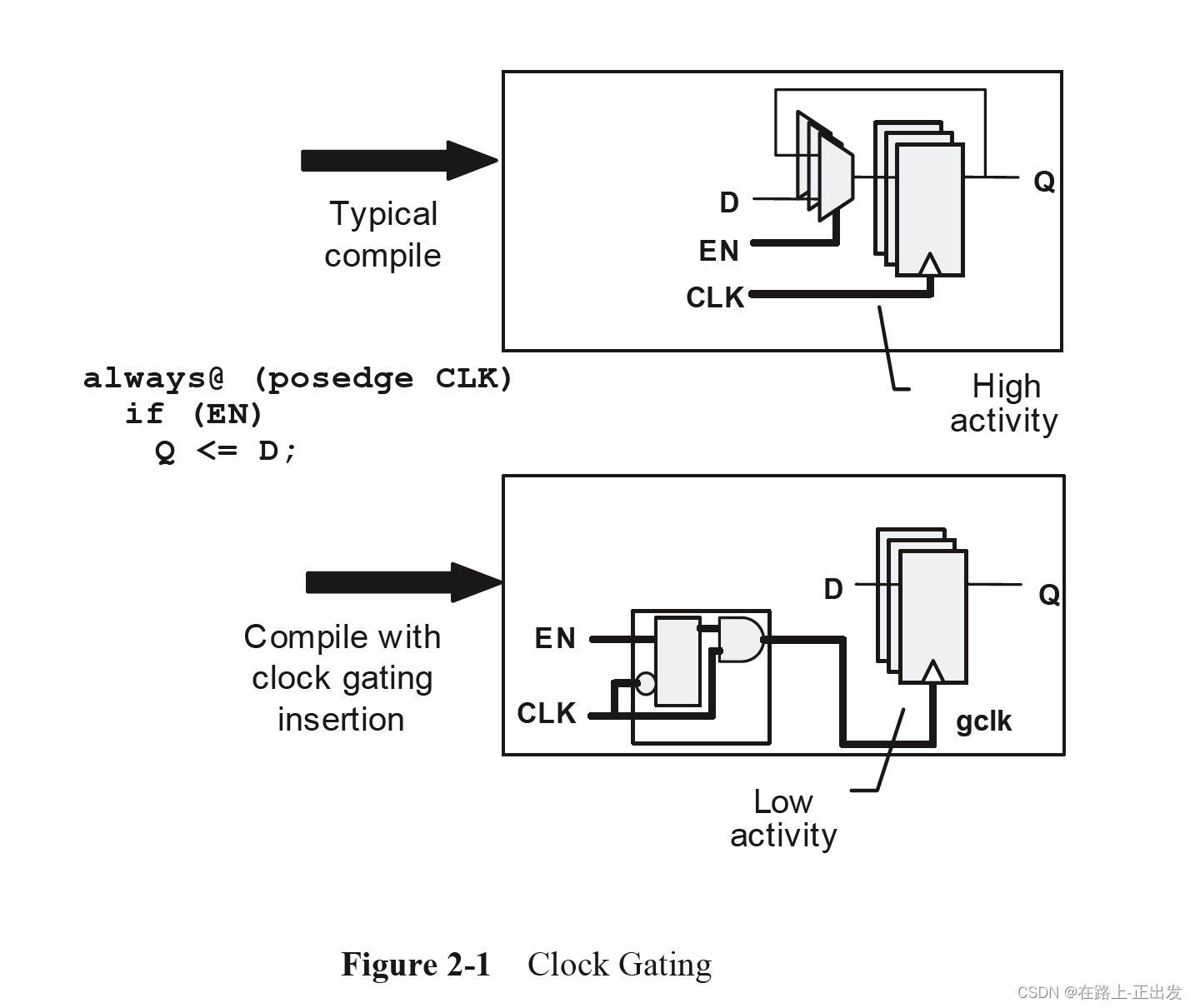
在原始RTL中,寄存器是否更新取决于变量(EN)。通过基于相同的变量对时钟进行门控可以实现相同的结果。
如果所涉及的寄存器是单个位,则会出现少量节省。如果它们是32位寄存器,那么一个时钟门控单元可以将时钟门控到所有32个寄存器(以及它们的时钟树中的任何缓冲器)。这样可以节省大量的电力。
在RTL设计的早期,工程师会在RTL中明确地对时钟门控电路进行编码。这种方法很容易出错——很容易创建一个时钟门控电路,该电路在门控过程中出现故障,从而产生功能错误。如今,大多数库都包括合成工具识别的特定时钟门控单元。显式时钟门控单元和自动插入的结合使时钟门控成为一种简单可靠的降低功率的方法。实现这种类型的时钟门控不需要对RTL进行任何更改。
结果
在最近的一篇论文[1]中,Pokhrel报告了一个独特的机会,他的团队最近不得不比较一个(几乎)相同的芯片,该芯片在有时钟门控和没有时钟门控的情况下实现。
作为一个功率降低项目,在与时钟门控相同的技术中重新实现了现有的没有时钟门控的180nm芯片。只实现了逻辑上的微小更改(删除了一些小块,并用其他块替换,以实现功能上的小幅净增加)。
Pokhrel报告称,根据操作模式,面积减少了20%,功率节省了34%至43%。(这种节省是在芯片的时钟门控部分实现的;处理器是一个硬宏,而不是时钟门控。当处理器处于IDLE模式时,即处理器关闭时,在整个芯片上进行功率测量。)功率测量来自实际的硅。
节省的面积是由于单个时钟门控单元取代了多个多路复用器。
Pokhrel做了几个有趣的观察:
• 经过一些分析和实验,该团队决定只在位宽至少为3bit位宽的寄存器上使用时钟门控。他们发现,一位寄存器上的时钟门控在功率或面积上都不高效。
• 节省的大部分功率是由于时钟门控单元位于时钟路径的早期。大约60%的时钟缓冲器出现在时钟门控单元之后,因此在门控期间它们的活动减少到零。
门级功率优化
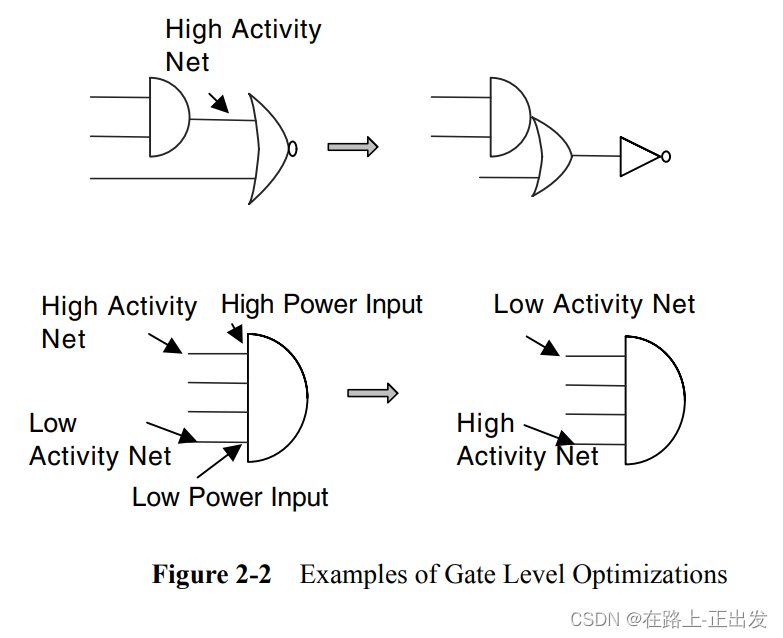
除了时钟门控之外,工具还可以执行许多逻辑优化,以最大限度地减少动态功率。下图显示了其中的两个优化。
在图的顶部,与门输出具有特别高的活动性。因为后面跟着一个NOR门,所以可以将这两个门重新映射到一个AND-OR门加上一个反相器,这样高活动性网络就变成了单元内部。现在,高活动节点(与门的输出)正在驱动更小的电容,从而降低动态功率。
在图的底部,最初映射了AND门,从而将高活动性网络连接到高功率输入引脚,将低活动性网络映射到低功率引脚。对于多个输入门,不同引脚的输入电容以及功率可能存在显著差异。通过重新映射输入,使高活动网络连接到低功率输入,优化工具可以降低动态功率。
栅极级功率优化的其他示例包括单元大小和缓冲器插入。在电池尺寸确定中,该工具可以在整个关键路径上选择性地增加和减少电池驱动强度,以实现定时,然后将动态功率降至最低。
在插入缓冲器时,工具可以插入缓冲器,而不是增加闸门本身的驱动强度。如果在正确的情况下进行,这可能会导致功率降低。
与时钟门控一样,门级功率优化由实现工具执行,并且对RTL设计者是透明的。
多 VDD
由于动态功率与 VDD^2 成比例,因此降低所选块上的VDD有助于显著降低功率。不幸的是,降低电压也会增加设计中栅极的延迟。
考虑下图中的示例。这里,高速缓存RAMS在最高电压下运行,因为它们位于关键时序路径上。CPU在高电压下运行,因为它的性能决定了系统性能。但它可以在比缓存略低的电压下运行,并且仍然具有由缓存速度决定的总体CPU子系统性能。芯片的其余部分可以在较低的电压下运行,而不会影响整体系统性能。通常,芯片的其余部分也以比CPU低得多的频率运行。
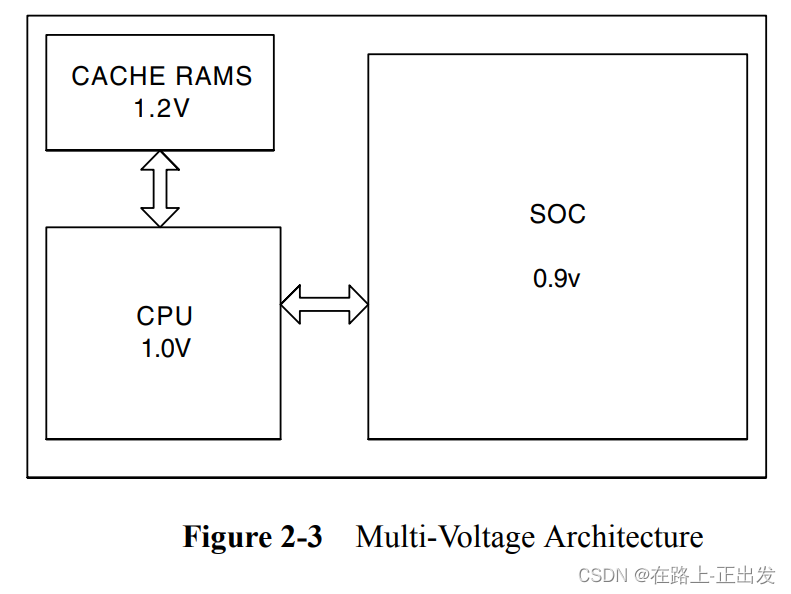
因此,系统的每个主要组件都在与满足系统时序一致的最低电压下运行。这种方法可以显著节省电力。
在不同VDD电源上混合块会增加设计的复杂性——我们不仅需要添加IO引脚来为不同的电源轨供电,而且还需要更复杂的电网和块之间信号的电平移位器。这些问题将在本书后面进行更详细的描述。
多阈值逻辑
随着几何结构缩小到130nm、90nm及以下,使用具有多个VT的库已成为降低泄漏电压的常见方式。
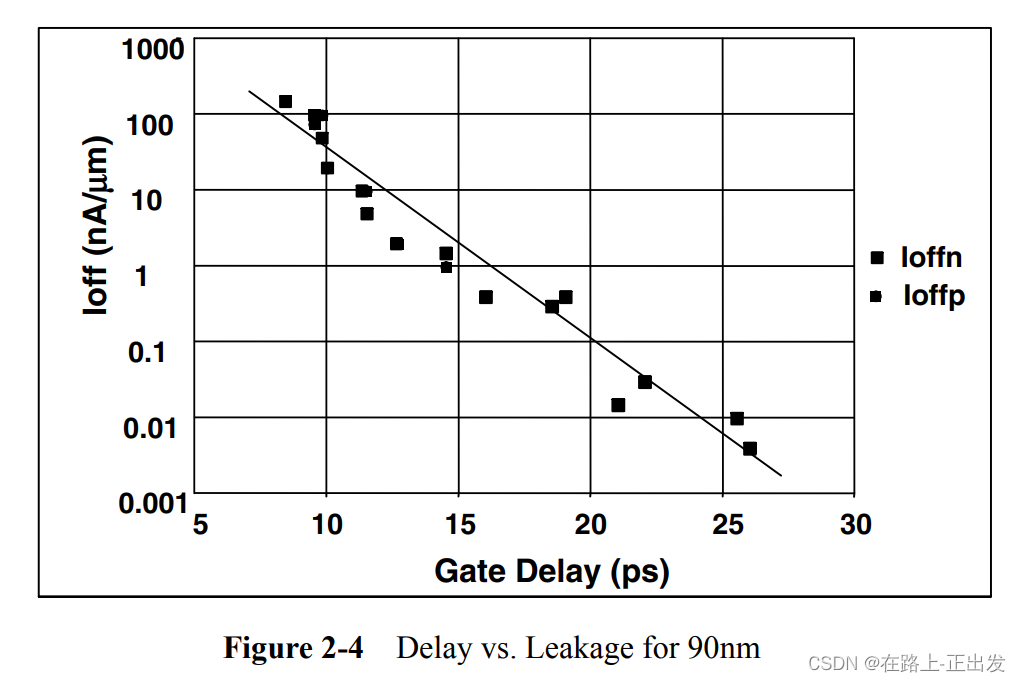
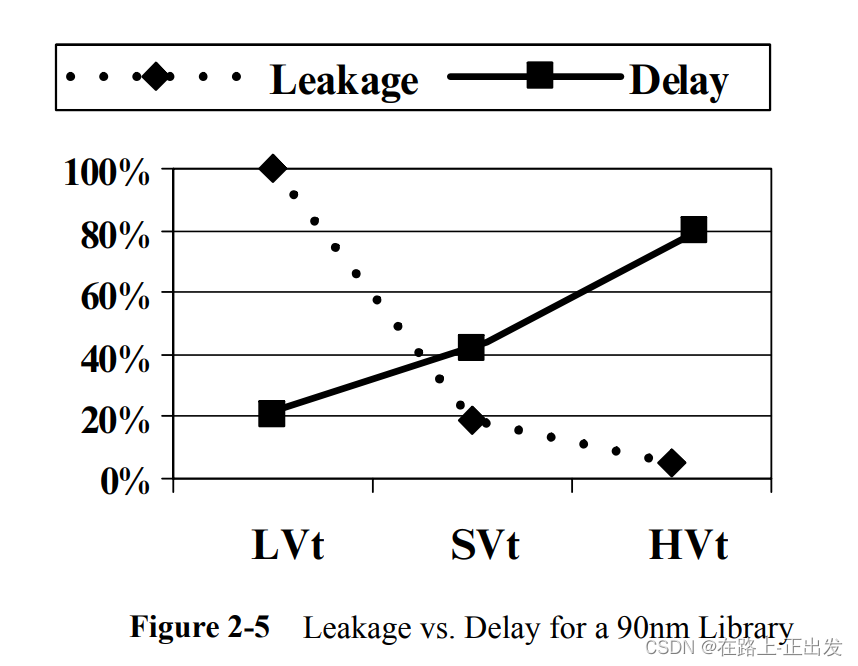
图2-4显示了90nm工艺的延迟和泄漏之间的关系。图2-5显示了多VT库的泄漏与延迟的一些代表性曲线。如前所述,亚阈值泄漏指数依赖于VT。延迟对VT的依赖性要弱得多。
如今,许多库提供两个或三个版本的单元:低VT、标准VT和高VT。实现工具可以利用这些库同时优化时序和功率。
现在,在合成过程中使用“双VT”流是很常见的。这种方法的目标是通过仅在需要满足定时的情况下部署快速、泄漏的低VT晶体管来最小化它们的总数。这通常包括针对一个主库的初始合成,然后针对一个(或多个)具有不同阈值的附加库的优化步骤。
通常,在优化功率之前,必须满足最低性能要求。在实践中,这通常意味着首先用高性能、高泄漏库进行合成,然后通过将不在关键路径上的任何单元交换为性能较低、泄漏较低的等效单元来放松它们。
如果最小化泄漏比实现最低性能更重要,那么这个过程可以反过来进行:我们可以首先瞄准低泄漏库,然后在速度关键区域交换性能更高、高泄漏的等效物。
总结