Learning Dynamic Facial Radiance Fields for Few-Shot Talking Head Synthesis 笔记
摘要
Talking head synthesis is an emerging technology with wide applications in film dubbing, virtual avatars and online education. Recent NeRF-based methods generate more natural talking videos, as they better capture the 3D structural information of faces. However, a specific model needs to be trained for each identity with a large dataset. In this paper, we propose Dynamic Facial Radiance Fields (DFRF) for few-shot talking head synthesis, which can rapidly generalize to an unseen identity with few training data. Different from the existing NeRF-based methods which directly encode the 3D geometry and appearance of a specific person into the network, our DFRF conditions face radiance field on 2D appearance images to learn the face prior. Thus the facial radiance field can be flexibly adjusted to the new identity with few reference images. Additionally, for better modeling of the facial deformations, we propose a differentiable face warping module conditioned on audio signals to deform all reference images to the query space. Extensive experiments show that with only tens of seconds of training clip available, our proposed DFRF can synthesize natural and high-quality audio-driven talking head videos for novel identities with only 40k iterations. We highly recommend readers view our supplementary video for intuitive comparisons. Code is available in https://sstzal.github.io/DFRF/.
会说话的头像合成是一项新兴的技术,在电影配音、虚拟化身和在线教育等领域有着广泛的应用。最近的基于NeRF的方法生成更自然的谈话视频,因为它们更好地捕获面部的3D结构信息。然而,需要针对具有大型数据集的每个身份训练特定模型。在本文中,我们提出了动态面部辐射场(DFRF)的几个镜头说话的头部合成,它可以快速推广到一个看不见的身份与少量的训练数据。与现有的直接将特定人的3D几何形状和外观编码到网络中的基于NeRF的方法不同,我们的DFRF条件在2D外观图像上的人脸辐射场来学习人脸先验。因此,面部辐射场可以灵活地调整到新的身份与几个参考图像。此外,为了更好地建模的面部变形,我们提出了一个可微的面部变形模块的音频信号变形的查询空间的所有参考图像。大量的实验表明,只有几十秒的训练剪辑可用,我们提出的DFRF可以合成自然和高质量的音频驱动的说话头部视频的新身份,只有40k迭代。我们强烈建议读者查看我们的补充视频,以进行直观的比较。代码可在www.example.com上获得https://sstzal.github.io/DFRF/。
GitHub:https://github.com/sstzal/DFRF
知识点
框架
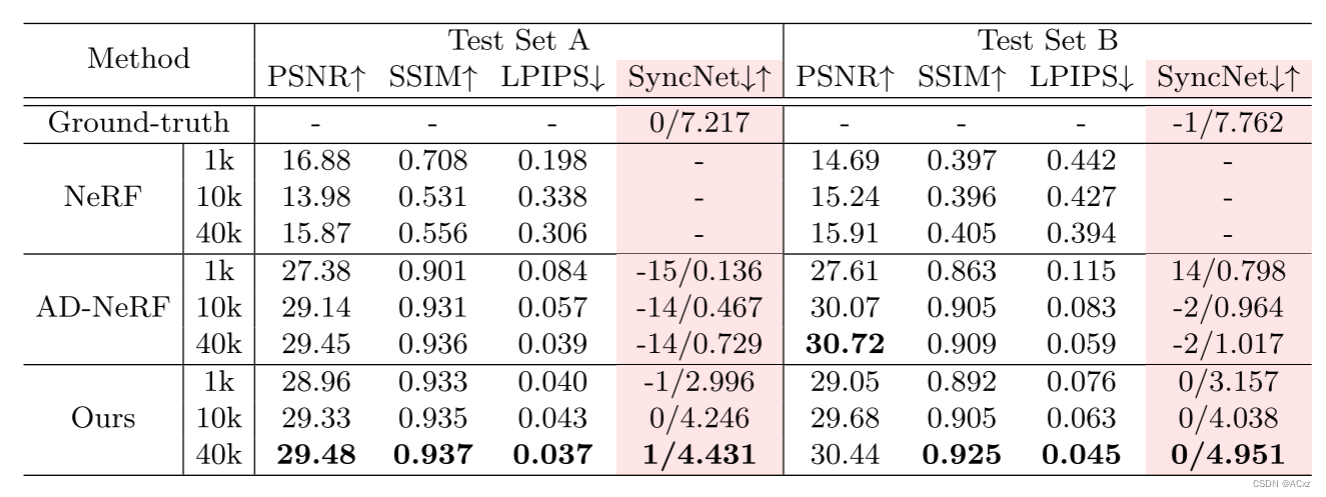
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XpvxyoE0-1682325914139)(C:\Users\dell\AppData\Roaming\Typora\typora-user-images\image-20230424154122197.png)]](https://img-blog.csdnimg.cn/3323b1f80b934343bdc703a4f88a8086.png)
Overview of the proposed Dynamic Facial Radiance Fields (DFRF)所提出的动态面部辐射场(DFRF)的概述。
使用预训练的基于RNN的DeepSpeech模块来提取每帧音频特征。对于帧间一致性,进一步引入时间滤波模块[39]以计算平滑音频流图像流投影基于注意力的特征融合音频特征A,其可以表示为其相邻音频特征的基于自注意力的融合。以这些音频特征序列A为条件,我们可以学习音频-嘴唇映射。该音频驱动的面部辐射场可以表示为 ( c , σ ) = F θ ( p , d , A ) \quad(c,\sigma)=\mathcal{F}_{\theta}\left(p,d,A\right) (c,σ)=Fθ(p,d,A)。
由于身份信息被隐式编码到面部辐射场中,并且在渲染时不提供显式身份特征,因此该面部辐射场是人特定的。对于每个新身份,都需要在大型数据集上从头开始优化。这导致昂贵的计算成本并且需要长的训练视频。为了摆脱这些限制,我们设计了一个参考机制,使训练有素的基础模型能够快速泛化到新的人员类别,只有一小段目标人员可用。图2中示出了这种基于参考的架构的概述。具体地,取N个参考图像
M
=
{
M
n
∈
R
H
×
W
∣
1
≤
n
≤
N
}
M=\left\{M_n\in\mathbb{R}^{H\times W}\text{}|1\leq n\leq N\right\}
M={Mn∈RH×W∣1≤n≤N}及其对应的摄像机位置
{
T
n
}
\{T_n\}
{Tn}作为输入,用一个两层卷积网络计算其像素对齐的图像特征
F
=
{
F
n
∈
R
H
×
W
×
D
∣
1
≤
n
≤
N
}
F=\left\{F_n\in\mathbb{R}^{H\times W\times D}|1\leq n\leq N\right\}
F={Fn∈RH×W×D∣1≤n≤N},无下采样。在本工作中,特征尺寸D被设置为128,并且H、W分别表示图像的高度和宽度。多个参考图像的使用提供了更好的多视图信息。对于一个3D查询点
p
=
(
x
,
y
,
z
)
∈
P
p=\left(x,y,z\right)\in\mathcal{P}
p=(x,y,z)∈P,我们使用本征函数
{
K
n
}
\{K_n\}
{Kn}和相机姿态
{
R
n
,
T
n
}
\{R_n,T_n\}
{Rn,Tn}将其投影回这些参考的2D图像空间,并得到相应的2D坐标。使用
p
n
r
e
f
=
(
u
n
,
v
n
)
\begin{matrix}p_n^{ref}=(u_n,v_n)\end{matrix}
pnref=(un,vn)来表示第n幅参考图像中的2D坐标,该投影可以被公式化为:
p
n
r
e
f
=
M
(
p
,
K
n
,
R
n
,
T
n
)
,
(1)
p_n^{ref}=\mathcal{M}(p,K_n,R_n,T_n),\tag1
pnref=M(p,Kn,Rn,Tn),(1)
其中
M
\text{}\mathcal{M}
M是从世界空间到图像空间的传统映射。然后,在舍入操作之后对来自N个参考的这些对应的像素级特征
{
F
n
(
u
n
,
v
n
)
}
∈
R
N
×
D
{\{F_n}(u_n,v_n)\}\in{\mathbb{R}^{N\times D}}
{Fn(un,vn)}∈RN×D进行采样,并与基于注意力的模块融合,以获得最终特征
F
~
=
A
g
g
r
e
g
a
t
i
o
n
(
{
F
n
(
u
n
,
v
n
)
}
)
∈
R
D
\tilde{F}=A g g r e g a t i o n(\{F_{n}(u_{n},v_{n})\})\in\mathbb{R}^{D}
F~=Aggregation({Fn(un,vn)})∈RD。这些要素网格包含有关身份和外观的丰富信息。使用它们作为我们的面部辐射场的附加条件,使得模型可以从几个观察到的帧快速概括为新的面部外观。该双驱动面部辐射场最终可以被公式化为:
(
c
,
σ
)
=
F
θ
(
p
,
d
,
A
,
F
~
)
.
(2)
(c,\sigma)=\mathcal F_\theta\left(p,d,A,\tilde F\right).\tag2
(c,σ)=Fθ(p,d,A,F~).(2)
可微分面变形
我们将查询3D点投影回这些参考图像的2D图像空间,如等式(1)所示。(1)以得到经调节的像素特征。该操作基于NeRF中的先验知识,即从不同视点投射的相交光线应对应于相同的物理位置,从而产生相同的颜色。这种严格的空间映射关系适用于刚性场景,但说话的脸是动态的。说话时,嘴唇和其他面部肌肉会根据发音而运动。应用等式(1)直接在可变形的说话面部上可能导致关键点不匹配。例如,标准体积空间中的嘴角附近的3D点被映射回参考图像的像素空间。如果参考面示出不同的嘴部形状,则映射点可能远离期望的真实的嘴角。这种不准确的映射导致来自参考图像的不正确的像素特征条件,这进一步影响对说话嘴的变形的预测。
为了解决这个限制,我们建议一个audio-conditioned和3D逐点面变形模块
D
η
\mathcal{D}_{\eta}
Dη。退化抵消
Δ
o
=
(
Δ
u
,
Δ
v
)
\Delta o=(\Delta u,\Delta v)
Δo=(Δu,Δv)为每个投影点”在特定的变形,就像图像流图2所示。具体来说,
D
η
\mathcal{D}_{\eta}
Dη实现变形场与中长期规划三层,其中
η
\eta
η是可学的参数。回归抵消
Δ
o
\Delta o
Δo,动态查询图像和参考图像之间的差异需要有效地利用。查询的音频信息反映了动态图像,而变形的参考图片可以看到通过
{
F
n
}
\{F_n\}
{Fn}隐式的图像特征。因此,我们将这两个部分与查询3D点坐标P-起作为
D
η
\mathcal{D}_{\eta}
Dη的输入。面变形的过程来预测补偿模块
D
η
\mathcal{D}_{\eta}
Dη可以制定为:
Δ
o
n
=
D
η
(
p
,
A
,
F
n
(
u
n
,
v
n
)
)
.
(3)
\Delta o_n=\mathcal{D}_\eta(p,A,F_n(u_n,v_n)).\tag3
Δon=Dη(p,A,Fn(un,vn)).(3)
然后,如图3所示,将预测的偏移
o
n
o_n
on添加到
p
n
r
e
f
p^{ref}_n
pnref,如图3所示,以得到如图3所示的精确对应坐标
p
n
r
e
f
‘
p^{ref^{`}}_n
pnref‘,以得到3D查询点
p
p
p,
p
n
r
e
f
=
p
n
r
e
f
+
Δ
o
n
=
(
u
n
′
,
v
n
′
)
,
(
where
u
n
′
=
u
n
+
Δ
u
n
a
n
d
v
n
′
=
v
n
+
Δ
v
n
.
)
(4)
p_n^{ref}=p_n^{ref}+\Delta o_n=(u_n',v_n'),(\text{where}\ \ u'_n=u_n+\varDelta u_n\mathrm{\ \ and\ \ }v'_n=v_n+\varDelta v_n.)\tag4
pnref=pnref+Δon=(un′,vn′),(where un′=un+Δun and vn′=vn+Δvn.)(4)
由于硬索引操作
F
n
(
u
n
′
,
v
n
′
)
F_{n}({u_{n}}^{\prime},{v_{n}}^{\prime})
Fn(un′,vn′)不可微,因此梯度不能被反向传播到该扭曲模块。因此,我们引入了一个软指标函数来实现可微翘曲,其中每个像素的特征是通过双线性采样的特征插值其周围的点。以这种方式,可以端到端地联合优化变形场
D
η
\mathcal{D}_{\eta}
Dη和面部辐射场
F
θ
\mathcal{F}_{\theta}
Fθ。该软索引操作的可视化在图3中示出。对于绿点,其像素特征通过其四个最近邻居的特征通过双线性插值来计算。为了更好地约束该扭曲模块的训练过程,我们引入正则化项
L
r
L_r
Lr以将预测偏移的值限制在合理的范围内以防止失真。
L
r
=
1
N
⋅
∣
P
∣
∑
p
∈
P
∑
n
=
1
N
Δ
u
n
2
+
Δ
v
n
2
,
(5)
L_r=\dfrac{1}{N\cdot|\mathcal{P}|}\sum\limits_{p\in\mathcal{P}}\sum\limits_{n=1}^N\sqrt{\Delta u_n^2+\Delta v_n^2},\tag5
Lr=N⋅∣P∣1p∈P∑n=1∑NΔun2+Δvn2,(5)
其中 P \mathcal{P} P是体素空间中所有3D点的集合, N N N是参考图像的数量。此外,我们认为,低密度的点更有可能是背景区域,应该有低变形偏移。在这些区域中,应施加更强的正则化约束。为了更合理的约束,我们将上述 L r L_r Lr改变为:
L
r
′
=
(
1
−
σ
)
⋅
L
r
,
(6)
L_r{'}=(1-\sigma)\cdot L_r,\tag6
Lr′=(1−σ)⋅Lr,(6)
其中
σ
\sigma
σ表示这些点的密度。动态面部辐射场最终可以被公式化为:
(
c
,
σ
)
=
F
θ
(
p
,
d
,
A
,
F
~
′
)
,
(7)
(c,\sigma)=\mathcal F_\theta\left(p,d,A,\tilde F'\right),\tag7
(c,σ)=Fθ(p,d,A,F~′),(7)
其中
F
~
=
A
g
g
r
e
g
a
t
i
o
n
(
{
F
n
(
u
n
′
,
v
n
′
)
}
)
\tilde{F}=A g g r e g a t i o n(\{F_{n}(u'_{n},v'_{n})\})
F~=Aggregation({Fn(un′,vn′)})。
利用该面部变形模块,可以将所有参考图像变换到查询空间,以更好地对说话面部变形进行建模。消融研究已经证明了该组件在产生更准确和音频同步的嘴部运动方面的有效性。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Q3iijfVI-1682325914139)(C:\Users\dell\AppData\Roaming\Typora\typora-user-images\image-20230424153431907.png)]](https://img-blog.csdnimg.cn/ed02e0c77ff44c5db73715d8b5e32dfc.png)
可微分面翘曲的可视化(Visualization of the differentiable face warping.)。查询3D点(紫色)被投影到参考图像空间(红色)。然后,学习偏移Δ o以将其扭曲到查询空间(绿色),其中其特征通过双线性插值来计算。
体渲染
体绘制用于对来自等式(7)的颜色c和密度σ进行积分转化成人脸图像。我们将背景、躯干和颈部部分一起作为渲染“背景”,并从原始视频中逐帧恢复。我们将每条射线的最后一个点的颜色设置为相应的背景像素,以渲染包括躯干部分的自然背景。这里,我们按照原始NeRF中的设置,在音频信号A和图像特征
F
′
~
\tilde{F^{\prime}}
F′~的条件下,相机光线
r
r
r的累积颜色
C
C
C为:
C
(
r
;
θ
,
η
,
R
,
T
,
A
,
F
~
′
)
=
∫
z
n
e
a
r
z
f
a
r
σ
(
t
)
⋅
c
(
t
)
⋅
T
(
t
)
d
t
,
(8)
C\left(r;\theta,\eta,R,T,A,\tilde{F}'\right)=\int_{z_{near}}^{z_{far}}\sigma\left(t\right)\cdot c(t)\cdot T\left(t\right)dt,\tag8
C(r;θ,η,R,T,A,F~′)=∫znearzfarσ(t)⋅c(t)⋅T(t)dt,(8)
其中
θ
\theta
θ和
η
\eta
η分别是面部辐射场
F
θ
\mathcal F_{\theta}
Fθ和面部扭曲模块
D
η
\mathcal{D}_{\eta}
Dη的可学习参数。
R
R
R是旋转矩阵,
T
T
T是平移向量。
T
(
t
)
=
e
x
p
(
−
∫
z
n
e
a
r
t
σ
(
r
(
s
)
)
d
s
)
T\left(t\right)=e x p\left(-\int_{z_{n e a r}}^{t}\sigma\left(r\left(s\right)\right)d s\right)
T(t)=exp(−∫zneartσ(r(s))ds)是沿着相机光线的积分透射率,其中
z
n
e
a
r
z_{near}
znear和
z
f
a
r
z_{far}
zfar是相机光线的近边界和远边界。我们按照NeRF设计MSE损失为
L
M
S
E
=
∥
C
−
I
∥
2
L_{MSE} =\left\|C-I\right\|^{2}
LMSE=∥C−I∥2,其中I是地面真值颜色。与方程中的正则化项耦合。(6),总损失函数可以公式化为:
L = L M S E + λ ⋅ L r ′ . (9) L=L_{MSE}+\lambda\cdot L_r{'}.\tag9 L=LMSE+λ⋅Lr′.(9)
效果