系列文章目录
#Python&Pytorch 1.如何入门深度学习模型#Python&Pytorch 2.如何对CTG特征数据建模
我之前也写过一篇使用GBDT对UCI-CTG特征数据进行建模的博客,不过那是挺早的时候写的,只是简单贴了代码,方便了解流程而已,现在就顺着上一篇博客的代码,来试试怎么样使用torch对CTG特征数据建模吧~
建模最关键的两个部分,第一就是数据,第二就是模型。只要搞定了这两部分,那建模基本上就是洒洒水的事情。
UCI-CTG的数据就放在GitHub里面:链接
(以下数据集描述摘抄至本人的另一篇博客)
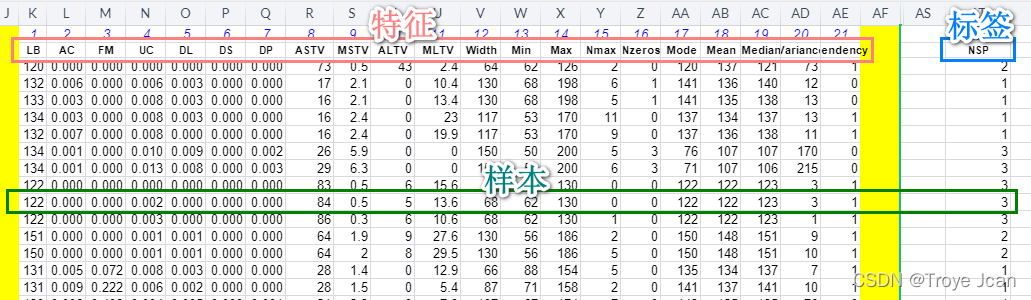
在公共CTG数据集的定义中,LB, AC, FM, UC, DL, DS, DP, ASTV, MSTV, ALTV, MLTV, Width, Min, Max,Nmax, Nzeros, Mode, Mean, Median, Variance, Tendency这21个是CTG变量,而NSP为标签(根据胎儿监护指南评价胎儿状态NSP: Normal, Suspicious, Pathological),即一个样本=21个CTG变量值+对应的NSP标签。
在训练模型时,我们使用特征作为模型的输入,使用标签来验证算法预测的结果是否准确,这就是最简单的分类问题。
有了上述的描述,我们都大致了解了CTG特征数据的构成,因此我们可以着手构建本次的代码。为了方便大家学习,我会把上一篇的代码和这一篇的代码放在一起,这样大家就能感受到如果使用自己的数据集需要修改什么地方,格式如下:
# 上一篇的代码
# ------------------------------------------------------------------------------------
# 改造后的代码
代码修改的部分
- 系列文章目录
- 1.导入所需的库
- 2.读取数据
- 3.自定义数据集
- 4.配置模型所需的基本参数
- 5.创建深度学习模型
- 6.编写训练代码
- 7.代码总结
1.导入所需的库
第一步,导入所需用到的库
因为要使用特征数据建模需要读取csv,所以导入了pandas库,然后还需要导入数据集分割函数,当然如果你已经事先分割好数据集了那就不用这个库了。
import os
import numpy as np
import torch
from sklearn.metrics import confusion_matrix, classification_report, f1_score
from torch import nn
from torch.utils.data import DataLoader, Dataset
from torchinfo import summary
from tqdm import tqdm
# ------------------------------------------------------------------------------------
import os
import numpy as np
import pandas as pd # 增加了pandas库,用于读取csv文件
import torch
from sklearn.metrics import confusion_matrix, classification_report, f1_score
from sklearn.model_selection import train_test_split # 增加了用于分割数据集的函数
from torch import nn
from torch.utils.data import DataLoader, Dataset
from torchinfo import summary
from tqdm import tqdm
2.读取数据
之后是读取数据这部分,我们需要读取数据集文件并把数据分割为训练集和测试集。代码如下:
# 读取数据
df = pd.read_csv('CTG.csv')
# 特征列名,因为数据集中除了最后一列是标签之外,其余列都是特征,因此我们直接取除了最后一列的列名作为我们的特征列
feature = df.columns.values[:-1]
print(feature)
# 用sklearn.cross_validation进行训练数据集划分,这里训练集和交叉验证集比例为8:2,可以自己根据需要设置
# NSP为标签,0表示正常,1表示可疑,3表示病理
X_train, X_test, y_train, y_test = train_test_split(
df[feature], # X
df['NSP'], # y
test_size=0.2, # 测试集比例为20%
random_state=1, # 设置随机种子以保证结果可以复现
stratify=df['NSP'] # 这里保证分割后y的比例分布与原数据一致
)
print(f"训练集的数目为 {X_train.shape[0]} 例;共有 {X_train.shape[1]} 个特征")
print(f"测试集的数目为 {X_test.shape[0]} 例;共有 {X_test.shape[1]} 个特征")
# output:
# ['LB' 'AC' 'FM' 'UC' 'DL' 'DS' 'DP' 'ASTV' 'MSTV' 'ALTV' 'MLTV' 'Width'
# 'Min' 'Max' 'Nmax' 'Nzeros' 'Mode' 'Mean' 'Median' 'Variance' 'Tendency']
# 训练集的数目为 1700 例;共有 21 个特征
# 训练集的数目为 426 例;共有 21 个特征
从上面的代码运行结果可以看到,我们共有1700例训练集,426例测试集,一共有21个特征。
3.自定义数据集
数据处理完毕后,我们需要改写上篇博客的数据集函数,将它改造成可以处理我们的数据集,代码如下
# 自定义数据集,继承torch.utils.data.Dataset,一般的数据集只需要重写下面的三个方法即可
class MyDataset(Dataset):
def __init__(self, data_len, ):
""" 初始化数据集并进行必要的预处理
初始化数据集一般需要包括数据和标签:数据可以是直接可以使用的特征或路径;标签一般可以存放在csv中,可以选择读取为列表
"""
# 随机初始化一个shape为(data_len, 10)的矩阵作为输入数据x,数据类型为float
self.datas = torch.randn(size=(data_len, 10), dtype=torch.float32)
# 随机初始化一个shape为(data_len, 1)的矩阵作为标签y,数据类型为int
self.labels = torch.randint(low=0, high=10, size=(data_len, 1))
def __len__(self):
""" 返回数据集的大小,方便后续遍历取数据 """
return len(self.labels)
def __getitem__(self, item):
""" item不需要我们手动传入,后续使用dataloader时会自动预取
这个函数的作用是根据item从数据集中取出对应的数据和标签
"""
return self.datas[item], self.labels[item][0]
# ------------------------------------------------------------------------------------
# 自定义数据集,继承torch.utils.data.Dataset,一般的数据集只需要重写下面的三个方法即可
class MyDataset(Dataset):
def __init__(self, feature_data, labels, ):
""" 初始化数据集并进行必要的预处理
初始化数据集一般需要包括数据和标签:数据可以是直接可以使用的特征或路径;标签一般可以存放在csv中,可以选择读取为列表
"""
# 我们可以直接将数据集的特征作为self.datas,因为我们在__getitem__中可以直接按照index从中取值,因此不用进行其他操作
self.datas = feature_data.values # .values表示将DataFrame中的矩阵取出,取出之后格式为numpy.array
# 同理,标签和特征是一一对应的,在__getitem__中取任意一个index都能找到对应的特征和标签
self.labels = labels
# 将标签NSP规范化,原始的1、2、3分别表示正常、可疑、病理;需要将替换为0、1、2,以保证各项指标的正常计算
# 若要进行二分类,则可以将可疑和无反应的标签替换为0,即变成了二分类
# 这一步操作可以在读取数据集的时候替换,也可以在这里替换,也可以在__getitem__里面替换,inplace=True表示将替换值直接覆盖原结果
# ctg['NSP'].replace({1: 0, 2: 1, 3: 1}, inplace=True) # 二分类
self.labels.replace({1: 0, 2: 1, 3: 2}, inplace=True) # 三分类
self.labels = self.labels.values
def __len__(self):
""" 返回数据集的大小,方便后续遍历取数据 """
return len(self.labels)
def __getitem__(self, item):
""" item不需要我们手动传入,后续使用dataloader时会自动预取
这个函数的作用是根据item从数据集中取出对应的数据和标签
"""
# 由于我们这里是读取的pandas数据转成numpy,而数据集的格式要求是tensor,所以我们需要将numpy转成tensor的格式
data = torch.tensor(self.datas[item], dtype=torch.float32) # 因为模型的权重和偏置矩阵都是float32的类型,因此也要把特征转换为float32
label = torch.tensor(self.labels[item])
return data, label
可以看到,由于数据集比较简单,所以我们修改的地方其实不多,但也有以下几点需要注意:
- 特征数据一般使用pandas读取,读取后的格式为DataFrame,而DataFrame格式在 _getitem_ 函数中不能通过 self.data[item] 的方式获取索引为item的特征,因此我们需要将DataFrame的格式转换为numpy.array或使用 self.data.iloc[item] 的方式获取。如果这点没有修改的话代码会报KeyError的错误;
- 分类数据的标签一般要从0开始,以保证部分指标的正常计算。这一步可以在读取数据集之后处理,也可以放在数据集函数里面处理;
- 在 _getitem_ 函数中,如果我们的在 _init_ 函数中我们的定义的数据是array的格式,那么在 _getitem_ 函数中我们就需要把我们取出来的值转换为tensor的格式。注意!有时候单纯转换格式可能还会报错,这里就是因为我们的数据集的数据类型 (float64) 跟模型的数据类型 (float32) 不一致,会报 RuntimeError 的错误,因此需要将数据类型转换为一致。如果不知道数据和模型的数据类型是什么格式的,可以通过以下代码输出:
# 在数据集函数的 __getitem__ 函数中
print(self.datas[item].dtype)
# 在模型的 forward 函数中
print(self.fc1.weight.dtype)
print(self.fc1.bias.dtype)
4.配置模型所需的基本参数
这样,我们的数据集函数也搞定了,在这里就可以来创建我们的数据集了
# 首先要定义我们需要训练多少轮,batch_size要定义为多少
EPOCHS = 2
BATCH_SIZE = 2
# 其次,torch的训练不会自动把数据和模型加载进GPU中,所以需要我们定义一个训练设备,例如device
device = torch.device('cpu') # 前期学习就只使用CPU训练
# !!重点,如果是使用GPU进行训练,那么我们需要把模型也加载进GPU中,不然就无法使用GPU训练
model = model.to(device) # 把模型加载至训练设备中
# 定义一个含有4000条数据的训练集和1000条数据的验证集
train_dataset = MyDataset(4000)
valid_dataset = MyDataset(1000)
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(valid_dataset, batch_size=BATCH_SIZE, shuffle=False) # 需要注意的是,验证集的dataloader不需要打乱数据
# ------------------------------------------------------------------------------------
# 首先要定义我们需要训练多少轮,batch_size要定义为多少
EPOCHS = 200
BATCH_SIZE = 4
# 其次,torch的训练不会自动把数据和模型加载进GPU中,所以需要我们定义一个训练设备,例如device
device = torch.device('cpu') # 前期学习就只使用CPU训练
# !!重点,如果是使用GPU进行训练,那么我们需要把模型也加载进GPU中,不然就无法使用GPU训练
model = model.to(device) # 把模型加载至训练设备中
train_dataset = MyDataset(X_train, y_train)
test_dataset = MyDataset(X_test, y_test)
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
test_loader = DataLoader(test_dataset , batch_size=BATCH_SIZE, shuffle=False) # 需要注意的是,验证集和测试集的dataloader是不需要打乱数据
定义数据集的部分改动只在创建数据集部分。另外把模型的训练轮次增加到200,批次大小增加到4,这两个改动都是无关紧要的。
5.创建深度学习模型
接下来是模型部分。
# 接着我们继续来定义一个简单的多层感知机模型
class MyModel(nn.Module):
""" 这个模型含有三个线性层,两个激活函数层和一个随机失活层 """
def __init__(self, in_channel, output_channel, drop_rate=0.0):
super().__init__()
# 定义第一个线性层,需要定义线性层的输入维度和输出维度,这里就把输出维度设置为输入维度的四倍
self.fc1 = nn.Linear(in_features=in_channel, out_features=in_channel * 4) # 线性层等价于Keras的Dense层,即全连接层
# 定义第二个线性层,将输入维度和输出维度设为in_channel的4倍
self.fc2 = nn.Linear(in_features=in_channel * 4, out_features=in_channel * 4)
# 定义最后一层的线性层(也可以称为分类层),用于分类,将数据维度压缩至output_channel的维度用于输出
self.head = nn.Linear(in_channel * 4, output_channel)
# 定义一个dropout层用于随机失活神经元
self.drop1 = nn.Dropout(drop_rate)
# 定义第一个线性层后的激活函数,处理dropout后的结果
self.act1 = nn.LeakyReLU()
# 定义第二个线性层后的激活函数,处理dropout后的结果
self.act2 = nn.LeakyReLU()
# 定义softmax函数用于将最终的输出结果映射到(0, 1)之间,dim=1表示softmax在维度为1的数据上进行处理
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
""" 这个函数的作用是定义模型前向计算,指定了如何根据输入数据 x 计算出模型的输出结果,是定义模型结构的关键
在__init__函数中,我们只定义了我们所需要的网络层,并没有定义数据是先经过哪个网络层再经过哪个网络层。
模型前向计算也可以看作数据 x 的流动方向,先从哪里流向哪里
"""
# 输入时,x.shape=(batch_size, 10)
x = self.fc1(x) # 先将 x 输入至第一个线性层中,输出维度扩大为输入维度的4倍,此时 x.shape=(batch_size, 40)
x = self.drop1(x) # dropout并不会改变 x 的形状,所以 x.shape=(batch_size, 40)
x = self.act1(x) # 同样LeakyReLU也不会改变 x 的形状,所以 x.shape=(batch_size, 40)
x = self.fc2(x) # 第二个线性层的输入维度和输出维度一致,所以 x 的形状保持不变 x.shape=(batch_size, 40)
x = self.act2(x) # 同理 x.shape=(batch_size, 40)
output = self.head(x) # x 输入至最后一层分类层,数据的输出维度为output_channel,因此 output.shape=(batch_size, 10)
output = self.softmax(output) # softmax同样不改变数据的形状,因此 output.shape=(batch_size, 10)
return output # 最后将模型的计算结果返回
模型方面没有对比的原因是模型根本就不用改!我们只需要在创建模型的时候把输入的维度改为输入特征数 (21) ,把最终输出维度改为数据的类别数 (3) 就可以匹配我们的数据格式。这样我们的模型就是一个以21个特征为输入,3种标签为结果的模型。
我们使用torchinfo的summary函数输出一下模型结构~
model = MyModel(21, 3, drop_rate=0.0)
# summary的时候需要把input_size对应修改为输入的特征数
summary(model, input_size=[(4, 21)], dtypes=[torch.float32], col_names=["input_size", "output_size", "num_params"])
# output:
# ===================================================================================================================
# Layer (type:depth-idx) Input Shape Output Shape Param #
# ===================================================================================================================
# MyModel [4, 21] [4, 3] --
# ├─Linear: 1-1 [4, 21] [4, 84] 1,848
# ├─Dropout: 1-2 [4, 84] [4, 84] --
# ├─LeakyReLU: 1-3 [4, 84] [4, 84] --
# ├─Linear: 1-4 [4, 84] [4, 84] 7,140
# ├─LeakyReLU: 1-5 [4, 84] [4, 84] --
# ├─Linear: 1-6 [4, 84] [4, 3] 255
# ├─Softmax: 1-7 [4, 3] [4, 3] --
# ===================================================================================================================
# Total params: 9,243
# Trainable params: 9,243
# Non-trainable params: 0
# Total mult-adds (M): 0.04
# ===================================================================================================================
# Input size (MB): 0.00
# Forward/backward pass size (MB): 0.01
# Params size (MB): 0.04
# Estimated Total Size (MB): 0.04
# ===================================================================================================================
简单吧?
6.编写训练代码
最后,我们的代码还差最后一个地方,改完就能训练我们的模型了,就是训练代码和测试代码的指标运算部分
print(confusion_matrix(targets, predictions, labels=range(0, 10)))
print(classification_report(targets, predictions, labels=range(0, 10)))
f1 = f1_score(targets, predictions, average='macro', labels=range(0, 10))
# ------------------------------------------------------------------------------------
print(confusion_matrix(targets, predictions, labels=range(0, 3)))
print(classification_report(targets, predictions, labels=range(0, 3)))
f1 = f1_score(targets, predictions, average='macro', labels=range(0, 3))
就是这样,只需要把类别改成CTG数据的标签就可以了。
7.代码总结
所以总体的代码就搞定啦~其他地方都不用改,直接就能运行。代码总结如下:
# -*- coding: utf-8 -*-
"""
Created on 2023/4/24 11:11
Location CellsVision
@author: Troye Jcan
"""
import os
import numpy as np
import pandas as pd
import torch
from sklearn.metrics import confusion_matrix, classification_report, f1_score
from sklearn.model_selection import train_test_split
from torch import nn
from torch.utils.data import DataLoader, Dataset
from torchinfo import summary
from tqdm import tqdm
# 读取数据
df = pd.read_csv('CTG.csv')
# 特征列名,因为数据集中除了最后一列是标签之外,其余列都是特征,因此我们直接取除了最后一列的列名作为我们的特征列
feature = df.columns.values[:-1]
print(feature)
# 用sklearn.cross_validation进行训练数据集划分,这里训练集和交叉验证集比例为8:2,可以自己根据需要设置
# NSP为标签,0表示正常,1表示可疑,3表示病理
X_train, X_test, y_train, y_test = train_test_split(
df[feature], # X
df['NSP'], # y
test_size=0.2, # 测试集比例为20%
random_state=1, # 设置随机种子以保证结果可以复现
stratify=df['NSP'] # 这里保证分割后y的比例分布与原数据一致
)
print(f"训练集的数目为 {X_train.shape[0]} 例;共有 {X_train.shape[1]} 个特征")
print(f"训练集的数目为 {X_test.shape[0]} 例;共有 {X_test.shape[1]} 个特征")
# output:
# ['LB' 'AC' 'FM' 'UC' 'DL' 'DS' 'DP' 'ASTV' 'MSTV' 'ALTV' 'MLTV' 'Width'
# 'Min' 'Max' 'Nmax' 'Nzeros' 'Mode' 'Mean' 'Median' 'Variance' 'Tendency']
# 训练集的数目为 1700 例;共有 21 个特征
# 训练集的数目为 426 例;共有 21 个特征
class MyDataset(Dataset):
def __init__(self, feature_data, labels, ):
""" 初始化数据集并进行必要的预处理
初始化数据集一般需要包括数据和标签:数据可以是直接可以使用的特征或路径;标签一般可以存放在csv中,可以选择读取为列表
"""
# 我们可以直接将数据集的特征作为self.datas,因为我们在__getitem__中可以直接按照index从中取值,因此不用进行其他操作
self.datas = feature_data.values # .values表示将DataFrame中的矩阵取出,取出之后格式为numpy.array
# 同理,标签和特征是一一对应的,在__getitem__中取任意一个index都能找到对应的特征和标签
self.labels = labels
# 将标签NSP规范化,原始的1、2、3分别表示正常、可疑、病理;需要将替换为0、1、2,以保证各项指标的正常计算
# 若要进行二分类,则可以将可疑和无反应的标签替换为0,即变成了二分类
# 这一步操作可以在读取数据集的时候替换,也可以在这里替换,也可以在__getitem__里面替换,inplace=True表示将替换值直接覆盖原结果
# ctg['NSP'].replace({1: 0, 2: 1, 3: 1}, inplace=True) # 二分类
self.labels.replace({1: 0, 2: 1, 3: 2}, inplace=True) # 三分类
self.labels = self.labels.values
def __len__(self):
""" 返回数据集的大小,方便后续遍历取数据 """
return len(self.labels)
def __getitem__(self, item):
""" item不需要我们手动传入,后续使用dataloader时会自动预取
这个函数的作用是根据item从数据集中取出对应的数据和标签
"""
# 由于我们这里是读取的pandas数据转成numpy,而数据集的格式要求是tensor,所以我们需要将numpy转成tensor的格式
data = torch.tensor(self.datas[item], dtype=torch.float32) # 因为模型的权重和偏置矩阵都是float32的类型,因此也要把特征转换为float32
label = torch.tensor(self.labels[item])
return data, label
# 接着我们继续来定义一个简单的多层感知机模型
class MyModel(nn.Module):
""" 这个模型含有三个线性层,两个激活函数层和一个随机失活层 """
def __init__(self, in_channel, output_channel, drop_rate=0.0):
super().__init__()
# 定义第一个线性层,需要定义线性层的输入维度和输出维度,这里就把输出维度设置为输入维度的四倍
self.fc1 = nn.Linear(in_features=in_channel, out_features=in_channel * 4) # 线性层等价于Keras的Dense层,即全连接层
# 定义第二个线性层,将输入维度和输出维度设为in_channel的4倍
self.fc2 = nn.Linear(in_features=in_channel * 4, out_features=in_channel * 4)
# 定义最后一层的线性层(也可以称为分类层),用于分类,将数据维度压缩至output_channel的维度用于输出
self.head = nn.Linear(in_channel * 4, output_channel)
# 定义一个dropout层用于随机失活神经元
self.drop1 = nn.Dropout(drop_rate)
# 定义第一个线性层后的激活函数,处理dropout后的结果
self.act1 = nn.LeakyReLU()
# 定义第二个线性层后的激活函数,处理dropout后的结果
self.act2 = nn.LeakyReLU()
# 定义softmax函数用于将最终的输出结果映射到(0, 1)之间,dim=1表示softmax在维度为1的数据上进行处理
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
""" 这个函数的作用是定义模型前向计算,指定了如何根据输入数据 x 计算出模型的输出结果,是定义模型结构的关键
在__init__函数中,我们只定义了我们所需要的网络层,并没有定义数据是先经过哪个网络层再经过哪个网络层。
模型前向计算也可以看作数据 x 的流动方向,先从哪里流向哪里
"""
# 输入时,x.shape=(batch_size, 10)
x = self.fc1(x) # 先将 x 输入至第一个线性层中,输出维度扩大为输入维度的4倍,此时 x.shape=(batch_size, 40)
x = self.drop1(x) # dropout并不会改变 x 的形状,所以 x.shape=(batch_size, 40)
x = self.act1(x) # 同样LeakyReLU也不会改变 x 的形状,所以 x.shape=(batch_size, 40)
x = self.fc2(x) # 第二个线性层的输入维度和输出维度一致,所以 x 的形状保持不变 x.shape=(batch_size, 40)
x = self.act2(x) # 同理 x.shape=(batch_size, 40)
output = self.head(x) # x 输入至最后一层分类层,数据的输出维度为output_channel,因此 output.shape=(batch_size, 10)
output = self.softmax(output) # softmax同样不改变数据的形状,因此 output.shape=(batch_size, 10)
return output # 最后将模型的计算结果返回
model = MyModel(21, 3, drop_rate=0.0)
# torchinfo的summary方法可以使得模型的结构按照类似表格的方式输出,非常方便我们查看每个层的输入输出维度,强烈推荐!
summary(model, input_size=[(2, 21)], dtypes=[torch.float32], col_names=["input_size", "output_size", "num_params"])
# 交叉熵是最常用的分类损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器可以使用Adam,需要输入模型的参数和学习率
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
# 首先要定义我们需要训练多少轮,batch_size要定义为多少
EPOCHS = 100
BATCH_SIZE = 4
# 其次,torch的训练不会自动把数据和模型加载进GPU中,所以需要我们定义一个训练设备,例如device
device = torch.device('cpu') # 前期学习就只使用CPU训练
# !!重点,如果是使用GPU进行训练,那么我们需要把模型也加载进GPU中,不然就无法使用GPU训练
model = model.to(device) # 把模型加载至训练设备中
# 定义一个含有4000条数据的训练集和1000条数据的验证集
train_dataset = MyDataset(X_train, y_train)
valid_dataset = MyDataset(X_test, y_test)
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(valid_dataset, batch_size=BATCH_SIZE, shuffle=False) # 需要注意的是,验证集的dataloader不需要打乱数据
def simple_train(dataloader, model, loss_fn, optimizer):
model.train() # 将模型调整为训练模式
average_loss = 0. # 定义平均损失为0.
train_bar = tqdm(enumerate(dataloader), total=len(dataloader), desc='Train')
for batch, (X, y) in train_bar:
X, y = X.to(device), y.to(device) # 将数据和标签都加载至训练设备中
pred = model(X) # 将 X 输入至模型中计算结果
loss = loss_fn(pred, y) # 用损失函数对模型的预测结果和标签进行计算
average_loss += loss.item() # 把损失加到平均损失中,可以用在进度条上实时显示该batch的损失
optimizer.zero_grad() # 首先需要将优化器的梯度初始化为0,如果没有初始化,之前每个batch计算的梯度就会累积起来
loss.backward() # 之后损失函数计算输出的梯度(误差),同时将梯度从输出层向输入层反向传播,并通过链式法则计算每个神经元的梯度
optimizer.step() # 最后根据梯度下降法计算损失函数关于每个参数的梯度,并更新模型的参数
# set_postfix可以给进度条的后面加上后缀,参数名称写什么进度条的后面就会显示什么
train_bar.set_postfix(loss=average_loss / (batch + 1))
train_bar.update() # 立即更新进度条,方便看到训练进度
def simple_valid(dataloader, model, best_score):
model.eval() # 将模型调整为验证模式,加快推理速度
pred_list, target_list = [], []
with torch.no_grad(): # 在验证时使用,使得模型在推理过程中不计算梯度,大大加快推理速度
for X, y in dataloader: # 因为在验证过程中并不需要观察验证中间过程的损失值等,所以不需要使用枚举,直接循环
X, y = X.to(device), y.to(device) # 同样也需要把数据和标签都加载至训练设备中
pred = model(X) # 将 X 输入至模型中进行推理,计算预测结果
# 将每个样本的预测结果概率中最大值的索引当成预测结果取出
# 如果是用GPU训练的话还要加上.cpu()表示把数据传输到cpu上,因为在GPU上没法处理;之后再用.numpy()表示只取预测结果的数值
pred_list.append(pred.argmax(1).cpu().numpy()) # 预测结果列表
target_list.append(y.cpu().numpy()) # 标签列表
# 预测结果列表和标签列表都是按batch拼接的,因此我们需要使用numpy转换成按样本拼接,这样才能计算混淆矩阵和分类报告
predictions = np.concatenate(pred_list, axis=0)
targets = np.concatenate(target_list, axis=0)
# 接下来就可以把标签和预测结果输入函数中啦,记得不要搞反了~ 还有labels建议也要输入,否则混淆矩阵和分类报告的行列都会随机,不方便统计结果
print(confusion_matrix(targets, predictions, labels=range(0, 3)))
print(classification_report(targets, predictions, labels=range(0, 3)))
f1 = f1_score(targets, predictions, average='macro', labels=range(0, 3))
if f1 > best_score:
print(f'------ The best result improved from {best_score} to {f1} -----')
best_score = f1
torch.save(model.state_dict(), 'best.pth')
else:
if os.path.exists(f'best.pth'):
model.load_state_dict(torch.load('best.pth'))
print(f'model restore the best.pth')
print(f'best m_score till now: {best_score}')
return best_score
best_score = 0.
for epoch in range(EPOCHS):
print(f"Epoch {epoch+1} / {EPOCHS}\n-------------------------------")
simple_train(train_loader, model, loss_fn, optimizer)
best_score = simple_valid(valid_loader, model, best_score)
最终模型训练了100轮,最佳f1的结果在第88epoch,f1=0.7515
# output:
# Epoch 88 / 100
# -------------------------------
# Train: 100%|██████████| 425/425 [00:00<00:00, 692.15it/s, loss=0.69]
# [[302 22 8]
# [ 27 31 1]
# [ 0 5 30]]
# precision recall f1-score support
#
# 0 0.92 0.91 0.91 332
# 1 0.53 0.53 0.53 59
# 2 0.77 0.86 0.81 35
#
# accuracy 0.85 426
# macro avg 0.74 0.76 0.75 426
# weighted avg 0.85 0.85 0.85 426
#
# ------ The best result improved from 0.7473452473452472 to 0.7514974534641704 -----
从上面的流程大家也可以看到,其实写代码训练模型的过程是不难的。首先只要你有了一个框架,那你只需解决两个问题:
- 数据集读取问题:像这个例子中我们将csv格式的数据作为数据集划分为训练集和测试集,然后构造一个可以按索引从数据集中读取样本的数据集函数,之后就可以用dataloader把它包装起来使用。在这一步一定要检查数据的格式和类型跟模型匹不匹配;
- 模型输入输出问题:我们需要理清楚模型的输入的shape和输出的shape。网络层会对输入产生什么影响是可以直接在forward函数里面print出来的,例如我们可以直接通过
print(self.fc1(x).shape)来查看 x 在经过 fc1 层之后形状发生了什么变化,以此来判断输入下一个网络层之前需要进行什么操作。
理清楚上面两点后,剩下的就是一些小修小补的事情了,类似于计算指标时 labels 要及时更改呀、epoch和batch_size设置为多少啊这种。建议动手试试!
!如果copy了上面的总结代码但是运行不成功的朋友,一定要跟我说!我会及时修改,谢谢~
下一篇就写怎么使用torch对CTU-CHB信号数据建模吧~
有疑惑的朋友一定欢迎在评论区留言~都会回复的
End



![观察者设计模式(Observer Design Pattern)[论点:概念、组成角色、相关图示、示例代码、框架中的运用、适用场景]](https://img-blog.csdnimg.cn/2494a74a45d9427eb407be9fa6702265.png)