文章目录
- 1. Prompt Tuning含义
- 1.1 解决问题
- 1.2 语言模型分类
- 1.3 Prompt-Tuning的研究进展
- 1.4 如何挑选合适的Pattern?
- 1.5 Prompt-Tuning的本质
- 1.5.1 Prompt的本质是一种对任务的指令
- 1.5.2 Prompt的本质是一种对预训练任务的复用;
- 1.5.3 Prompt的本质是一种参数有效性学习;
- 2. 经典的预训练模型
- 2.1 Masked Language Modeling(MLM)
- 2.2 Next Sentence Prediction(NSP)
- 3. 测试Fine-tuning
- 3.1 Single-text Classification(单句分类)
- 3.2 Sentence-pair Classification(句子匹配/成对分类)
- 3.3 Span Text Prediction(区间预测)
- 3.4 Single-token Classification(字符分类)
- 3.5 Text Generation(文本生成)
1. Prompt Tuning含义
- 以GPT-3、PET为首提出一种基于预训练语言模型的新的微调范式——Prompt-Tuning ,其旨在通过添加模板的方法来避免引入额外的参数,从而让语言模型可以在小样本(Few-shot)或零样本(Zero-shot)场景下达到理想的效果。Prompt-Tuning又可以称为Prompt、Prompting、Prompt-based Fine-tuning等。
1.1 解决问题
- 降低语义差异(Bridge the gap between Pre-training and Fine-tuning) :预训练任务主要以Masked Language Modeling(MLM)为主,而下游任务则重新引入新的训练参数,因此两个阶段的目标通常有较大差异。因此需要解决如何缩小Pre-training和Fine-tuning两个阶段目标差距过大的问题;
- 避免过拟合(Overfitting of the head) :由于在Fine-tuning阶段需要新引入额外的参数以适配相应的任务需要,因此在样本数量有限的情况容易发生过拟合,降低了模型的泛化能力。因此需要面对预训练语言模型的过拟合问题。
1.2 语言模型分类
- 单向 :以GPT为首,强调 从左向右 的编码顺序,适用于Encoder-Decoder模式的自回归(Auto-regressive)模型;
- 双向 :以ELMO为首,强调从左向右和从右向左 双向编码 ,但ELMO的主体是LSTM,由于其是串形地进行编码,导致其运行速度较慢,因此最近BERT则以Transformer为主体结构作为双向语言模型的基准。
- 目前的大模型都是以TRansformer为计算推理技术.
Prompt的目的是将Fine-tuning的下游任务目标转换为Pre-training的任务.
- 构建模板(Template Construction) :通过人工定义、自动搜索、文本生成等方法,生成与给定句子相关的一个含有[MASK]标记的模板。例如It was [MASK].,并拼接到原始的文本中,获得Prompt-Tuning的输入:[CLS] I like the Disney films very much. [SEP] It was [MASK]. [SEP]。将其喂入BERT模型中,并复用预训练好的MLM分类器(在huggingface中为BertForMaskedLM),即可直接得到[MASK]预测的各个token的概率分布;
- 标签词映射(Label Word Verbalizer) :因为[MASK]部分我们只对部分词感兴趣,因此需要建立一个映射关系。例如如果[MASK]预测的词是“great”,则认为是positive类,如果是“terrible”,则认为是negative类。
1.3 Prompt-Tuning的研究进展
Prompt-Tuning起源于GPT-3的提出《Language Models are Few-Shot Learners》(NIPS2020)[3],其认为超大规模的模型只要配合好合适的模板就可以极大化地发挥其推理和理解能力。
其开创性提出 in-context learning 概念,即无须修改模型即可实现few-shot/zero-shot learning。同时引入了demonstrate learning,即让模型知道与标签相似的语义描述,提升推理能力。
- In-context Learning :是Prompt的前身。其通过从训练集中挑选一些样本作为任务的提示提示(Natural Language Prompt),来实现免参数更新的模型预测;
- Demonstration Learning :添加一些新的文本作为提示。例如在对“I like the Disney film. It was [MASK]”进行情感分析时,可以拼接一些相似场景的ground-truth文本“I like the book, it was great.”、“The music is boring. It is terrible for me.”等。此时模型在根据新添加的两个样例句子就可以“照葫芦画瓢”式地预测结果了。
1.4 如何挑选合适的Pattern?
- 人工构建(Manual Template) :在前文已经描述过,不再详细说明;
- 启发式法(Heuristic-based Template) :通过规则、启发式搜索等方法构建合适的模板;
- 生成(Generation) :根据给定的任务训练数据(通常是小样本场景),生成出合适的模板;
- 词向量微调(Word Embedding) :显式地定义离散字符的模板,但在训练时这些模板字符的词向量参与梯度下降,初始定义的离散字符用于作为向量的初始化;
- 伪标记(Pseudo Token) :不显式地定义离散的模板,而是将模板作为可训练的参数;
1.5 Prompt-Tuning的本质
1.5.1 Prompt的本质是一种对任务的指令
Prompt本质上是对下游任务的指令,可以作为一种信息增强 。简单的来说,就是告诉模型需要做什么任务,输出什么内容。上文我们提及到的离散或连续的模板,本质上就是一种对任务的提示。当数据集不同(乃至样本不同)的时候,我们期望模型能够自适应的选择不同的模板,这也相当于说不同的任务会有其对应的提示信息。
例如在对电影评论进行二分类的时候,最简单的提示模板是“. It was [mask].”,但是其并没有突出该任务的具体特性,我们可以为其设计一个能够突出该任务特性的模板,例如“The movie review is . It was [mask].”,然后根据mask位置的输出结果通过Verbalizer映射到具体的标签上。这一类具备任务特性的模板可以称之为 指令(Instruction) 。
1.5.2 Prompt的本质是一种对预训练任务的复用;
回顾第一节我们介绍的几个预训练语言模型,我们发现目前绝大多数的双向预训练语言模型都包含Masked Language Modeling(MLM),单向预训练语言模型都包含Autoregressive Language Modeling(ALM),这些任务是预训练目标,本质上是预测被mask的位置的词,在训练时让模型理解语言的上下文信息。之所以设计Template和指令,就是希望在下游任务时能够复用这些预训练的目标,避免引入新的参数而导致过拟合。因此,我们可以将Prompt升华到一个新的高度,即 Prompt Tuning的本质是复用预训练语言模型在预训练阶段所使用的目标和参数 。
基于Huggingface的预训练模型仓库中,我们一般称之为LMhead,本质上就是一个MLP,输入为一个大小为[batch_size, sequence_length, hidden_size]的张量,输出为[batch_size, sequence_length, vocab_size]的概率分布。
由于绝大多数的语言模型都采用MLM或ALM进行训练,所以我们现如今所看到的大多数基于Prompt的分类都要设计Template和Verbalizer。那么我们是否可以极大化地利用MLM和ALM的先验知识在不同的下游任务上获得更好的表现?是否可以设计一个全新的预训练任务来满足一些下游任务的需求呢?
我们介绍两个充分利用这个思想的方法:
- 万物皆可生成 :将所有任务统一为文本生成,极大化利用单向语言模型目标;
- 万物皆可抽取 :将所有任务统一为抽取式阅读理解,并设计抽取式预训练目标;
- 万物皆可推理 :将所有任务建模为自然语言推断(Natural Language Inference)或相似度匹配任务。
1.5.3 Prompt的本质是一种参数有效性学习;
参数有效性学习的背景 :在一般的计算资源条件下,大规模的模型(例如GPT-3)很难再进行微调,因为所有的参数都需要计算梯度并进行更新,消耗时间和空间资源。为了解决这个问题,参数有效性学习被提出,其旨在确保模型效果不受太大影响的条件下尽可能地提高训练的时间和空间效率。 参数有效性训练 :在参数有效性学习过程中,大模型中只需要指定或额外添加少量的可训练参数,而其余的参数全部冻结,这样可以大大提高模型的训练效率的同时,确保指标不会受到太大影响。
2. 经典的预训练模型
2.1 Masked Language Modeling(MLM)
-
1.传统的语言模型是以word2vec、GloVe为代表的词向量模型,他们主要是以词袋(N-Gram)为基础。例如在word2vec的CBOW方法中,随机选取一个固定长度的词袋区间,然后挖掉中心部分的词后,让模型(一个简单的深度神经网络)预测该位置的词
-
- Masked Language Modeling(MLM)则采用了N-Gram的方法,不同的是,N-Gram喂入的是被截断的短文本,而MLM则是完整的文本,因此MLM更能够保留原始的语义:
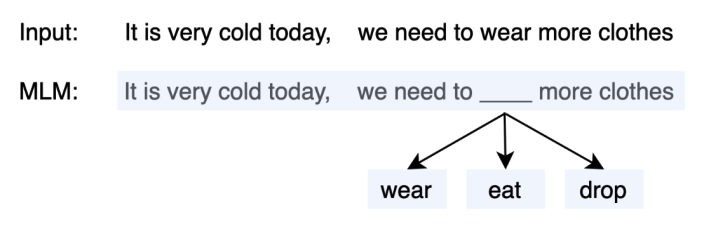
- MLM是一种自监督的训练方法,其先从大规模的无监督语料上通过固定的替换策略获得自监督语料,设计预训练的目标来训练模型,
- 替换策略:在所有语料中,随机抽取15%的文本。被选中的文本中,则有80%的文本中,随机挑选一个token并替换为 [mask],10%的文本中则随机挑选一个token替换为其他token,10%的文本中保持不变。
- 训练目标:当模型遇见 [mask] token时,则根据学习得到的上下文语义去预测该位置可能的词,因此,训练的目标是对整个词表上的分类任务,可以使用交叉信息熵作为目标函数。

-
- Whole Word Masking(WWM) :来源于RoBERTa等,其认为BERT经过分词后得到的是word piece,而BERT的MLM则是基于word piece进行随机替换操作的,即Single-token Masking,因此被mask的token语义并不完整。而WWM则表示被mask的必须是一个完整的单词。
-
- Entity Mention Replacement(EMR) :来源于ERNIE-BAIDU等,其通常是在知识增强的预训练场景中,即给定已知的知识库(实体),对文本中的整个实体进行mask,而不是单一的token或字符。
2.2 Next Sentence Prediction(NSP)
在BERT原文中,还添加了NSP任务,其主要目标是给定两个句子,来判断他们之间的关系,属于一种自然语言推理(NLI)任务。在NSP中则存在三种关系,分别是:
- entailment(isNext):存在蕴含关系,NSP中则认为紧相邻的两个句子属于entailment,即isNext关系;
- contradiction(isNotNext):矛盾关系,NSP中则认为这两个句子不存在前后关系,例如两个句子来自于不同的文章;
- Neutral:中性关系,NSP中认为当前的两个句子可能来自于同一篇文章,但是不属于isNext关系的

3. 测试Fine-tuning
3.1 Single-text Classification(单句分类)
- 常见的单句分类任务有短文本分类、长文本分类、意图识别、情感分析、关系抽取等。给定一个文本,喂入多层Transformer模型中,获得最后一层的隐状态向量后,再输入到新添加的分类器MLP中进行分类。在Fine-tuning阶段,则通过交叉信息熵损失函数训练分类器;
- 短/长文本分类:直接对句子进行归类,例如新闻归类、主题分类、场景识别等;
- 意图识别:根据给定的问句判断其意图,常用于检索式问答、多轮对话、知识图谱问答等;
- 情感分析:对评论类型的文本进行情感取向分类或打分;
- 关系抽取:给定两个实体及对应的一个描述类句子,判断这两个实体的关系类型;
3.2 Sentence-pair Classification(句子匹配/成对分类)
- 常见的匹配类型任务有语义推理、语义蕴含、文本匹配与检索等。给定两个文本,用于判断其是否存在匹配关系。此时将两个文本拼接后喂入模型中,训练策略则与Single-text Classification一样;
- 语义推理/蕴含:判断两个句子是否存在推理关系,例如entailment、contradiction,neutral三种推理关系;
- 文本匹配与检索:输入一个文本,并从数据库中检索与之高相似度匹配的其他句子
3.3 Span Text Prediction(区间预测)
- 常见的任务类型有抽取式阅读理解、实体抽取、抽取式摘要等。给定一个passage和query,根据query寻找passage中可靠的字序列作为预测答案。通常该类任务需要模型预测区间的起始位置,因此在Transformer头部添加两个分类器以预测两个位置。
- 抽取式阅读理解:给定query和passage,寻找passage中的一个文本区间作为答案;
- 实体抽取:对一段文本中寻找所有可能的实体;
- 抽取式摘要:给定一个长文本段落,寻找一个或多个区间作为该段落的摘要;
3.4 Single-token Classification(字符分类)
- 此类涵盖序列标注、完形填空、拼写检测等任务。获得给定文本的隐状态向量后,喂入MLP中,获得每个token对应的预测结果,并采用交叉熵进行训练。
- 序列标注:对给定的文本每个token进行标注,通常有词性标注、槽位填充、句法分析、实体识别等;
- 完形填空:与MLM一致,预测给定文本中空位处可能的词
- 拼写检测:对给定的文本中寻找在语法或语义上的错误拼写,并进行纠正;
3.5 Text Generation(文本生成)
- 文本生成任务常用于生成式摘要、机器翻译、问答等。通常选择单向的预训练语言模型实现文本的自回归生成,当然也有部分研究探索非自回归的双向Transformer进行文本生成任务。BART等模型则结合单向和双向实现生成任务。
- 生成式摘要:在文本摘要中,通过生成方法获得摘要;
- 机器翻译:给定原始语言的文本,来生成目标语言的翻译句子;
- 问答:给定query,直接生成答案;