背景
自从深度学习大规模应用以来,其中一个应用方向就是将深度学习视觉算法部署到嵌入式平台上,使用NPU推理。虽然已经做了很久的模型部署,但一直都是在公司默默耕耘,为了发展一下自己“边缘部署专家”这个个人品牌,打算补一下模型部署的相关经验分享,从总结过往的工作经验开始,从我最熟悉的嵌入式部署开始。
嵌入式部署一般分为几个部分:模型转换 -> 模型量化 -> 边缘端推理。这是算法部分部署的最基本组成。当然,展开的话还有很多值得深挖的地方,如模型转换实质上是深度学习编译过程,模型量化需要分析和解决量化误差的问题等等。本文先不作深入探究,先记录基本流程,更多经验留待后面文章研究。
这里以开发板VIM3(主控A311D)为例子(虽然很少人用,但这是我最熟悉的开发板),说明整个过程。
准备
在正式开始之前,需要做一些准备工作:
- 硬件平台的工具链。开发板配套资料中,一定有NPU相关的工具链。这里我用的公司从代理采购的芯片,所以使用了公版工具链。如果是VIM3,可以从https://github.com/khadas/aml_npu_sdk下载,参考https://docs.khadas.com/products/sbc/vim3/npu/npu-sdk
- 训练好的模型。模型一般由算法工程师提供,转成onnx格式,尽量根据文档手册选择onnx opset版本,一般是opset v11较为常见。如果没有算法工程师,那就自己训练一个(误)。也可以https://github.com/onnx/models下载一个,不过可能要解决的问题比较多。我这里用的自己以前积累的模型。
- 50200张图片样本。模型的输入图片,用于量化校准。一般推荐50200张涵盖主要应用场景的样本即可。
模型转换
如前面背景所述,模型转换解决的是将模型在PC端可推理的格式,转换成硬件平台NPU可运行的格式,本质上是一个编译过程。但是因为编译本身需要维护完整的规则,一般这一步厂商都会选择提供完整工具实现。为了便于大家全局地理解这个过程,我这里列出A311D和TDA4VM的转换过程,实则大同小异。
A311D
在A311D中,工具链给出的转换脚本有三个:0_import_model.sh,1_quantize_model.sh,2_export_case_code.sh,分别对应模型转换成中间表达,模型量化参数计算,模型格式打包,后续有机会再一一说明其深入含义,本文先只把其当做是一系列工具运行。其中脚本例子如下:
#!/bin/bash
NAME=test
ACUITY_PATH=../bin/
pegasus=${ACUITY_PATH}pegasus
if [ ! -e "$pegasus" ]; then
pegasus=${ACUITY_PATH}pegasus.py
fi
#Onnx
$pegasus import onnx\
--model ${NAME}.onnx \
--output-model ${NAME}.json \
--output-data ${NAME}.data
$pegasus generate inputmeta \
--model ${NAME}.json \
--input-meta-output ${NAME}_inputmeta.yml \
--channel-mean-value "0 0 0 0.0039216" \
--source-file dataset.txt
#!/bin/bash
NAME=test
ACUITY_PATH=../bin/
pegasus=${ACUITY_PATH}pegasus
if [ ! -e "$pegasus" ]; then
pegasus=${ACUITY_PATH}pegasus.py
fi
#--quantizer asymmetric_affine --qtype uint8
#--quantizer dynamic_fixed_point --qtype int8(int16,note s905d3 not support int16 quantize)
# --quantizer perchannel_symmetric_affine --qtype int8(int16, note only T3(0xBE) can support perchannel quantize)
$pegasus quantize \
--quantizer asymmetric_affine \
--qtype uint8 \
--rebuild \
--with-input-meta ${NAME}_inputmeta.yml \
--model ${NAME}.json \
--model-data ${NAME}.data
#!/bin/bash
NAME=test
ACUITY_PATH=../bin/
pegasus=$ACUITY_PATH/pegasus
if [ ! -e "$pegasus" ]; then
pegasus=$ACUITY_PATH/pegasus.py
fi
$pegasus export ovxlib\
--model ${NAME}.json \
--model-data ${NAME}.data \
--model-quantize ${NAME}.quantize \
--with-input-meta ${NAME}_inputmeta.yml \
--dtype quantized \
--optimize VIPNANOQI_PID0X99 \
--viv-sdk ${ACUITY_PATH}vcmdtools \
--pack-nbg-unify
mkdir normal_case_demo
mv *.h *.c .project .cproject *.vcxproj *.export.data BUILD *.linux normal_case_demo
一般的工具链运行脚本由可执行程序和输入参数组成,在这里展示的A311D转换脚本中,pegasus是由芯片厂商提供的可执行程序,通过后面的参数指定运行的子功能及配置。
在使用时,需要配置相应的参数,其中较为重要的包括:
# 输入图片的归一化参数,包括均值和方差,注意要跟模型输入的通道对齐
--channel-mean-value
# 校准数据集的文件列表
--source-file
# 量化后数据类型
--qtype
配置完参数化,依次执行脚本:
./0_import_model.sh
./1_quantize_model.sh
./2_export_case_code.sh
即可得到最终转换后的模型。
注:如果运行有误,注意检查路径,保证脚本指定的相对路径下有pegasus。
TDA4VM
TDA4在模型转换这一步也是提供了模型转换应用,以文件形式传入参数:
./tidl_convert ./import_model.txt
其中import_model.txt的示例如下:
modelType = 2
inputNetFile = "test.onnx"
outputNetFile = "test_tidl_net.bin"
outputParamsFile = "test_tidl_io_"
inDataNorm = 1
inMean = 0 0 0
inScale = 0.0039215686275 0.0039215686275 0.0039215686275
resizeHeight = 320
resizeWidth = 320
inHeight = 320
inWidth = 320
inNumChannels = 3
inData = "quan_test.txt"
numParamBits = 8
转换完成后,会生成两个.bin文件,分别由outputNetFile和outputParamsFile指定生成路径,一个存储网络及参数,另一个存储网络的输入输出IO。
模型量化
量化过程
在嵌入式平台,基于成本考虑,多数平台支持的是8 bit运算,即INT8/UINT8,而PC端训练的模型一般是float32的,因此就存在模型量化这一步骤,完成模型从32位运算8位运算的转换。一般在部署工具链中,会集成到模型转换过程中。
量化实质上是一个线性映射过程,将模型的权重和特征图的从原始有效数值范围线性映射到[0,255](UINT8,如果是INT8,则是[-127,127]),进而计算出当前节点量化线性映射的zero_point和scale。
量化算法
量化过程需要计算模型的权重以及特征图的有效范围。权重有效范围由于训练后模型冻结可以直接统计,但特征图的有效范围不能直接得到,需要使用量化样本进行模型前向推理,然后根据得到的特征图进行统计计算。计算特征图有效数值范围的方法即量化算法,常用的量化算法有:
直接统计:直接统计模型推理得到的特征图范围的最大值(max)和最小值(min);
KL divergence:浮点数模型和定点数模型分别计算出特征,抽象成两个直方图分布,通过调整不同的阈值来更新浮点数和定点数的直方图分布,并根据 KL 散度衡量两个分布的相似性来确定量化范围的最大值和最小值。
由于实际的量化实践中,量化算法的影响远远不及量化样本的影响,因此量化算法一直以来没有太大的发展,不同平台使用的均是已知较为常见成熟的量化算法。
QAT
以上对量化过程的叙述主要是训练后量化,即PTQ(post-training quantization)。与此相对的,有量化感知训练,即QAT(Quantization Aware Training)。量化感知训练是指在模型训练过程中就插入量化和反量化节点,在训练过程中模拟了量化的损失,把量化造成的影响一并优化。本质上,QAT是一个模拟量化的过程,与硬件上的全整型计算依然是不同的,但QAT可以通过训练来把模型的数值范围调整至对量化友好的范围(如既存在截断误差又存在精度表达不足的情况下,只能通过训练来调整),所以对于量化而言,QAT是最有效的方法。
量化误差
以上量化过程对于不同平台及不同模型大同小异,工程实践过程中,实际上大部分时间是在解决量化误差问题。量化误差来源主要有两个,一是截断误差,即计算特征图取值范围时对范围进行舍弃带来的误差;二是取整误差,即进行线性映射时,映射到两个整数之间的数值进行取整带来的误差。
量化误差的表现多种多样,我会用另外的文章深入探讨这个问题和解决方案。
边缘端推理
得到转换好的模型后,还需要进行边缘端的推理代码编写,一般是C/C++接口,由平台SDK定义。尽管不同平台接口不同,一般可分为平台引擎初始化、模型加载(模型初始化)、模型推理、数据加载、获取输出、模型释放、平台引擎资源释放等过程,不同平台有微小差异。以下是我自己抽象的调用代码示例:
// 1. 初始化边缘引擎日志 && 实例化一个模型
xaiedge::Log(NULL, XAIEDGE_DEBUG);
Model edge_model;
int status;
// 2. 初始化边缘端引擎
status = edge_model.init_engine(model_path.c_str(), json_path.c_str());
if (status < 0)
{
std::cout << "Init xaiedge engine failed!" << std::endl;
return -1;
}
std::cout << "Init xaiedge engine from model file successfully!" << std::endl;
// 3. 预处理图片数据 & 设置网络输入
cv::Mat input_img = cv::imread(image_path, cv::IMREAD_COLOR);
cv::cvtColor(input_img, input_img, cv::COLOR_BGR2RGB); // 留意是RGB还是BGR
status = edge_model.preprocess(input_img.data, 0); // preprocess和set_input配套使用
status = edge_model.set_input(NULL, 0); // 如果使用了默认的preprocess,set_input的传参为NULL;如果使用自定义的preprocess以及不使用preprocess,传入最终给到输入节点的数据地址
if (status < 0)
{
std::cout << "Preprocess failed!" << std::endl;
return -1;
}
std::cout << "Preprocess successfully!" << std::endl;
// 4. 网络推理
int64_t start_us = getCurrentTimeUs();
for (int i = 0; i < loop_num; ++i)
{
status = edge_model.run();
std::cout << "loop count: " << i << std::endl;
}
int64_t elapse_us = getCurrentTimeUs() - start_us;
printf("Elapse Time = %.2fms\n", elapse_us / 1000.f / loop_num);
std::cout << "run graph finish" << std::endl;
// 5.释放资源
edge_model.release_engine();
后续如有机会,将以具体平台做更详细的说明。````
附:一些工具的使用
Netron
Netron是开源的模型结构可视化工具,支持多种模型格式。当需要确认模型的结构,深入排查模型的结构问题时,Netron是必须的:
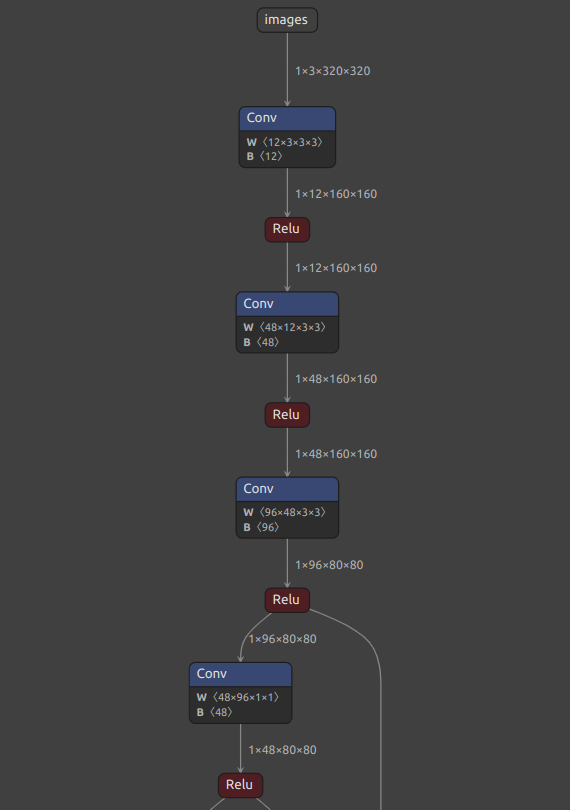
有在线版本和离线版本,可以直接在搜索引擎搜索使用。