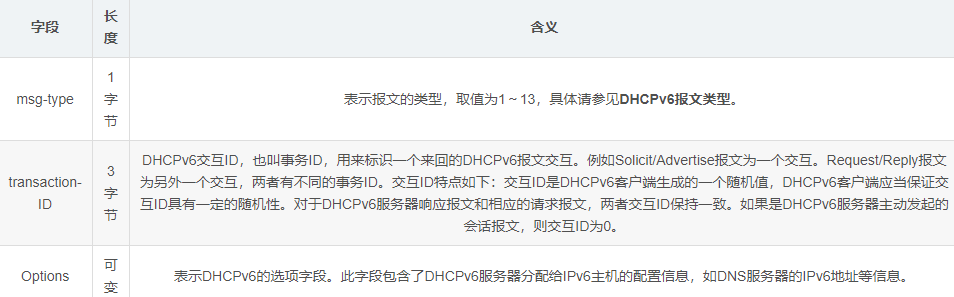
在这篇文章中,我们生成了 2 亿条时序人工数据,有 4 列,大小接近 12GB。使用 Pandas 库无法读取数据集并对其进行探索和可视化。与 pandas 相比,能够将字符串处理速度提高10-1000 倍。比spark快近十倍。
Pandas是用于数据科学案例研究的最受欢迎的库之一。它是探索性数据分析和数据整理的最佳工具之一。Pandas 可以高效地处理最适合内存的中小型数据集。对于核心数据集或大型数据集,熊猫执行操作效率低下。人们需要花费大量时间使用 pandas 数据框对大型数据集执行探索性数据分析。


![[python][pcl]python-pcl案例之兔子显示](https://img-blog.csdnimg.cn/4cb2f825db3949cca7ab16ba0a859bb0.png)