【C++入门必备知识:内联函数+指针空值nullptr】
- ①.内联函数
- Ⅰ.概念
- Ⅱ.宏与内联
- Ⅲ.总结
- ②.指针空值nullptr(C++11)
- Ⅰ.C++98中的指针空值
- Ⅱ.注意:

①.内联函数
Ⅰ.概念
用inline修饰的函数就叫做内联函数,编译时C++编译器会在调用内联函数的地方将函数直接展开,而不是去调用函数,没有建立函数栈帧的开销,跟C语言的宏的方式类似,内联函数提高了程序运行的效率。
using namespace std;
int Add(int x, int y)
{
return x + y;
}
int main()
{
int ret = 0;
ret = Add(2, 3);
return 0;
}
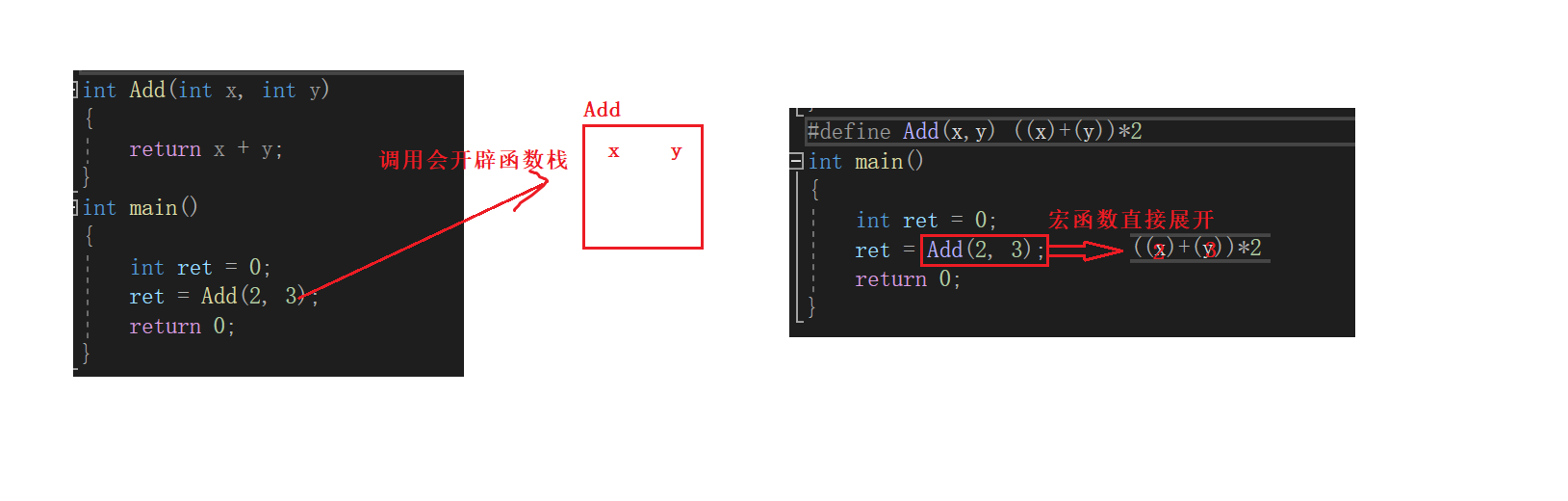
我们知道调用一个函数需要给这个函数建立函数栈帧。
当我们需要调用很多次该函数时,就需要花费大量的空间。
在C语言中我们是使用宏定义一个函数来解决这样的问题的。
int Add(int x, int y)
{
return (x + y);
}
我们要是有宏定义上面的函数该如何定义呢?
正确的写法应该是这样:
#define Add(x,y) (((x)+(y))
注意这里最最后没有分号。
当我们使用宏函数时,可以避免调用函数时建立栈帧的开销,因为当编译时,编译器会将宏函数直接展开,不会去调用开辟栈帧。
不过定义宏函数有很多易错点:
1.不加括号会引起很多错误
1.#define Add(x,y) x+y
当没有括号时
Add(1,2)*5;
因为Add是直接替换
所以结果就变成了1+2*5
2.#define Add(x,y) (x+y)
这种场景虽然外面加了括号,但里面没有仍然会出错
比如这样的场景,当x,y为表达式时呢?
你如何确定是+的优先级高还是x和y里面表达式的运算符优先级高呢?
比如Add(1|2,3&4);
直接替换为1|2+3&4,这里+号的优先级是比|和&高的。
2.注意宏函数定义,最后没有分号。
Ⅱ.宏与内联
优点:
1.可以增强代码的复用性
2.可以提高效率
缺点:
1.不方便调试,因为编译期间进行了替换
2.代码复杂,可读性差,容易误读
3.没有类型检查,安全性差。
虽然宏具有优势,但是它的缺点也是很多的,所以在C++中改变这样方法,引入了内联函数的概念。
我们只要在函数的前面加上关键字inline就变成了内联函数了。
而且内联函数既可以提高效率,可读性也好。
接下来让我们看看内联函数到底是如何使用的。
using namespace std;
inline int Add(int x, int y)
{
return x + y;
}
int main()
{
int ret = 0;
ret = Add(2, 3);
return 0;
}
如何查看?
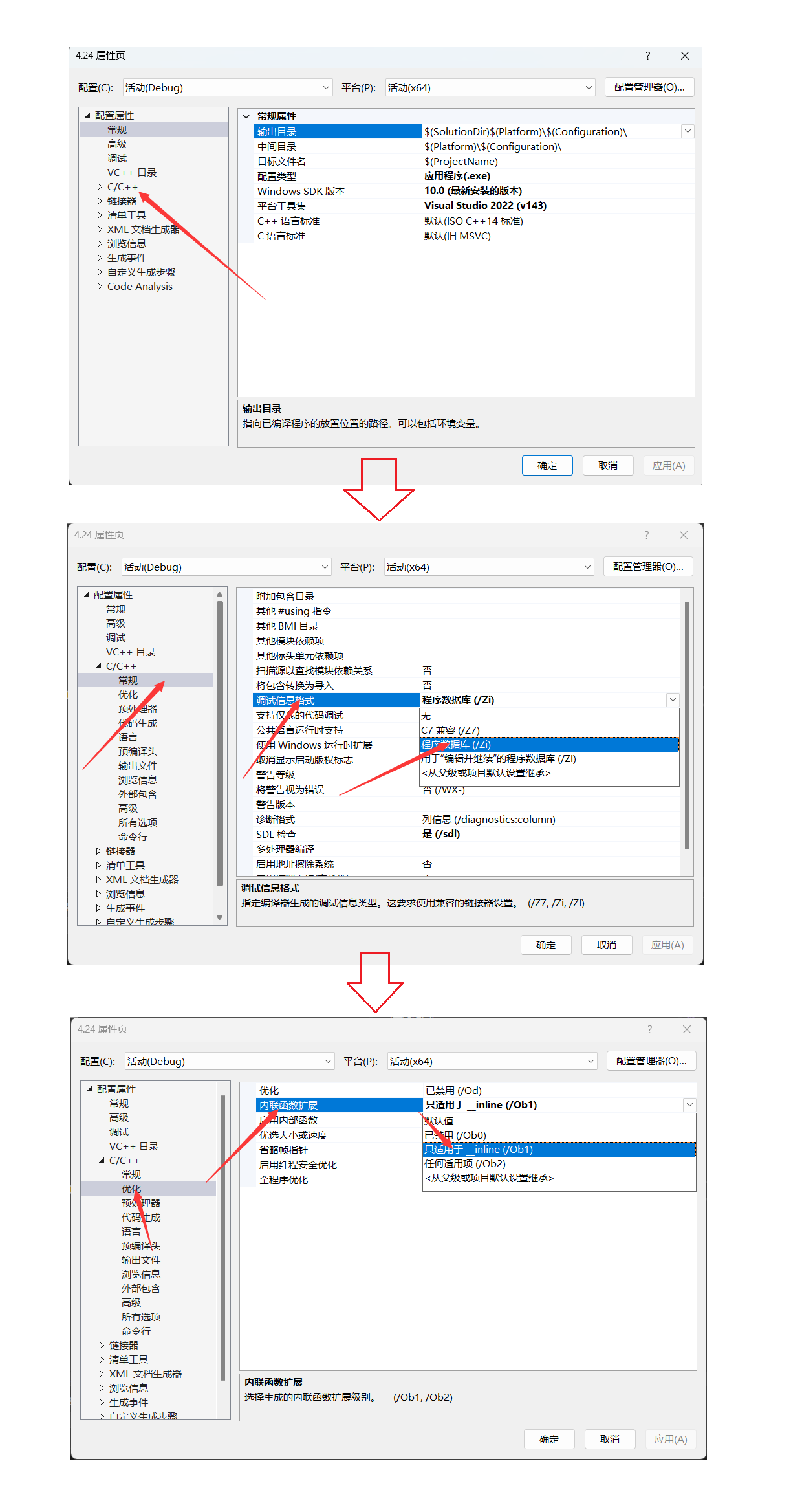
1.在release模式下,查看编译器生成的汇编代码中是否存在call Add,但在release版本下,不支持调试。
2.在debug版本下,因为编译器系统原因无法查看内联函数展开,所以我们需要对编译器进行一些调整
对于内联函数来说,函数在编译时期直接展开了。
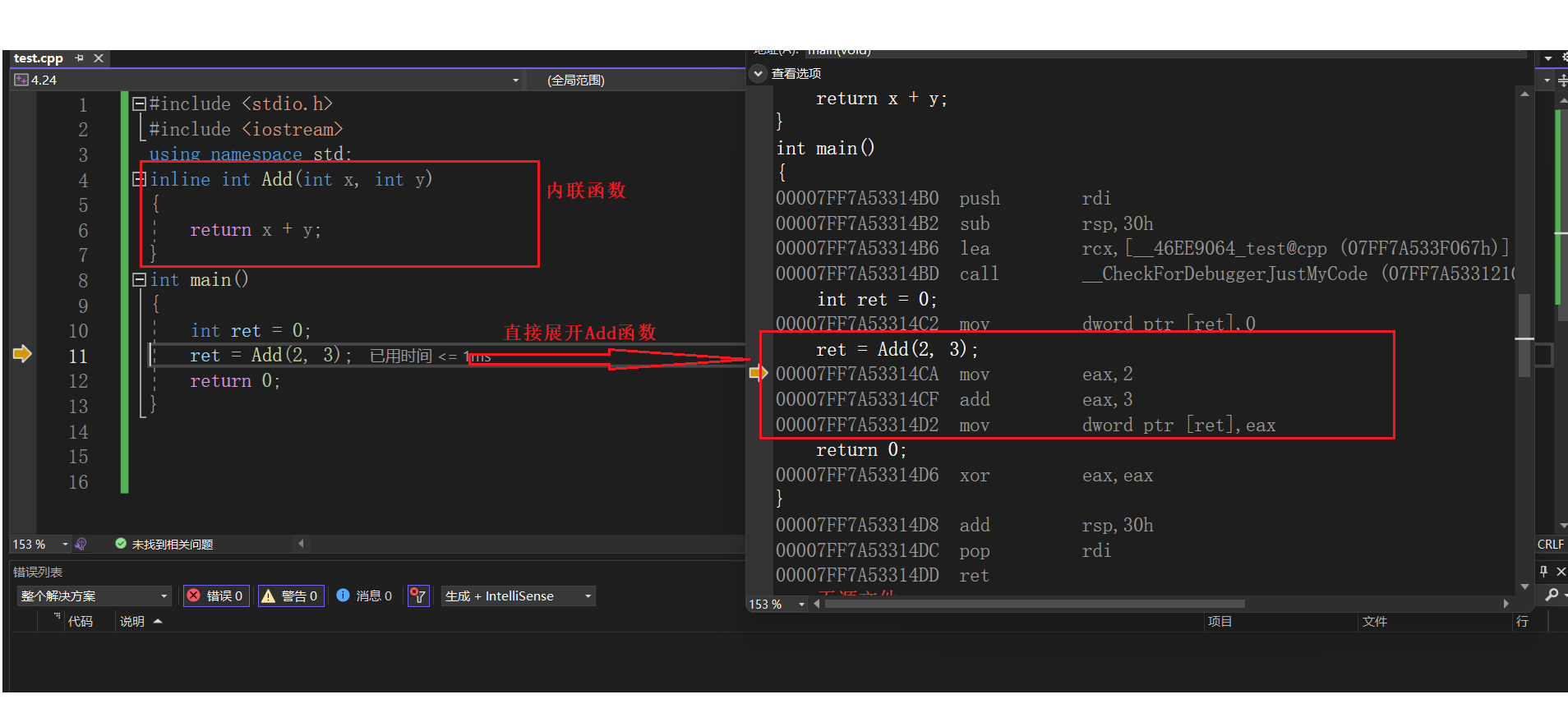
如果不是内联函数就需要调用函数,建立函数栈帧。
using namespace std;
int Add(int x, int y)
{
return x + y;
}
int main()
{
int ret = 0;
ret = Add(2, 3);
return 0;
}
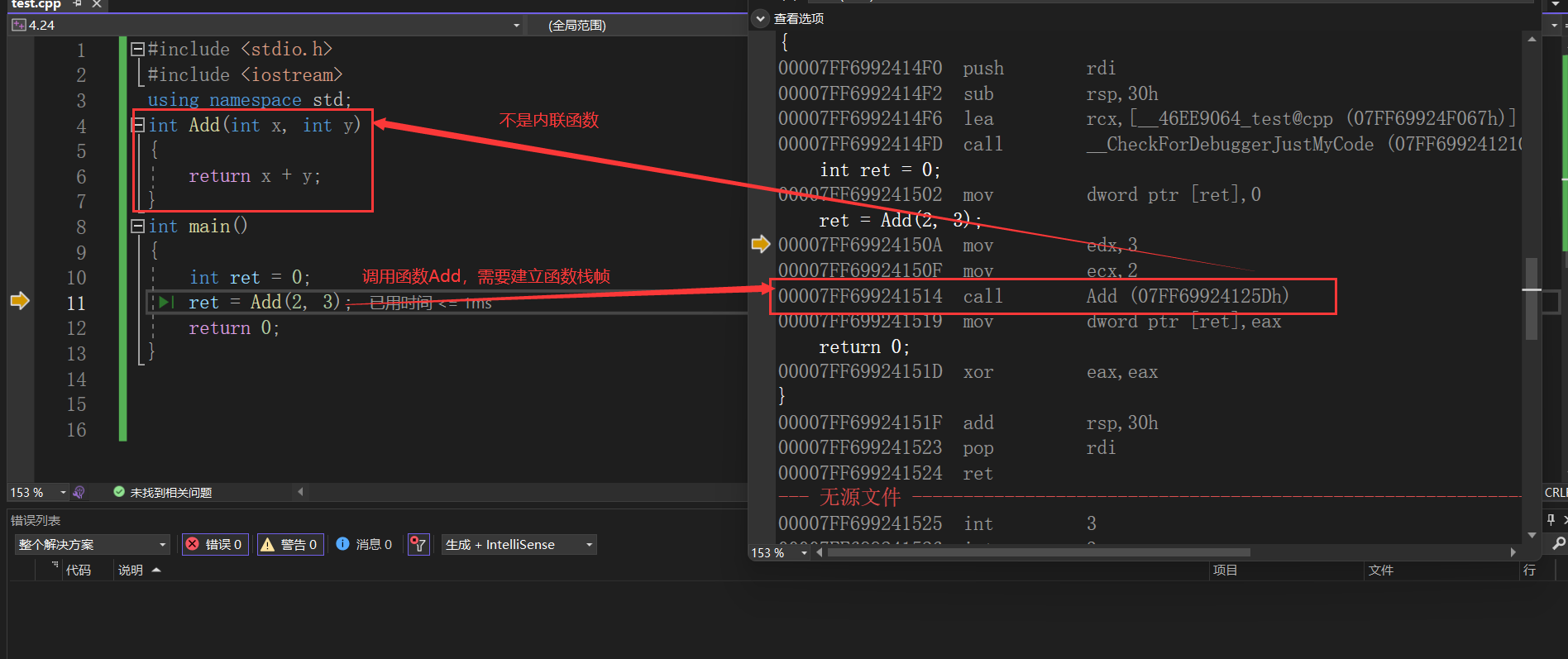
那内联函数这么好用,那以后是个函数都搞成内联函数可以吗?
当然不可以,内联函数和宏函数都是有使用范围的。
都适合于那些短小的频繁调用的函数,如果不是这样的函数,那么可能会造成代码膨胀的。
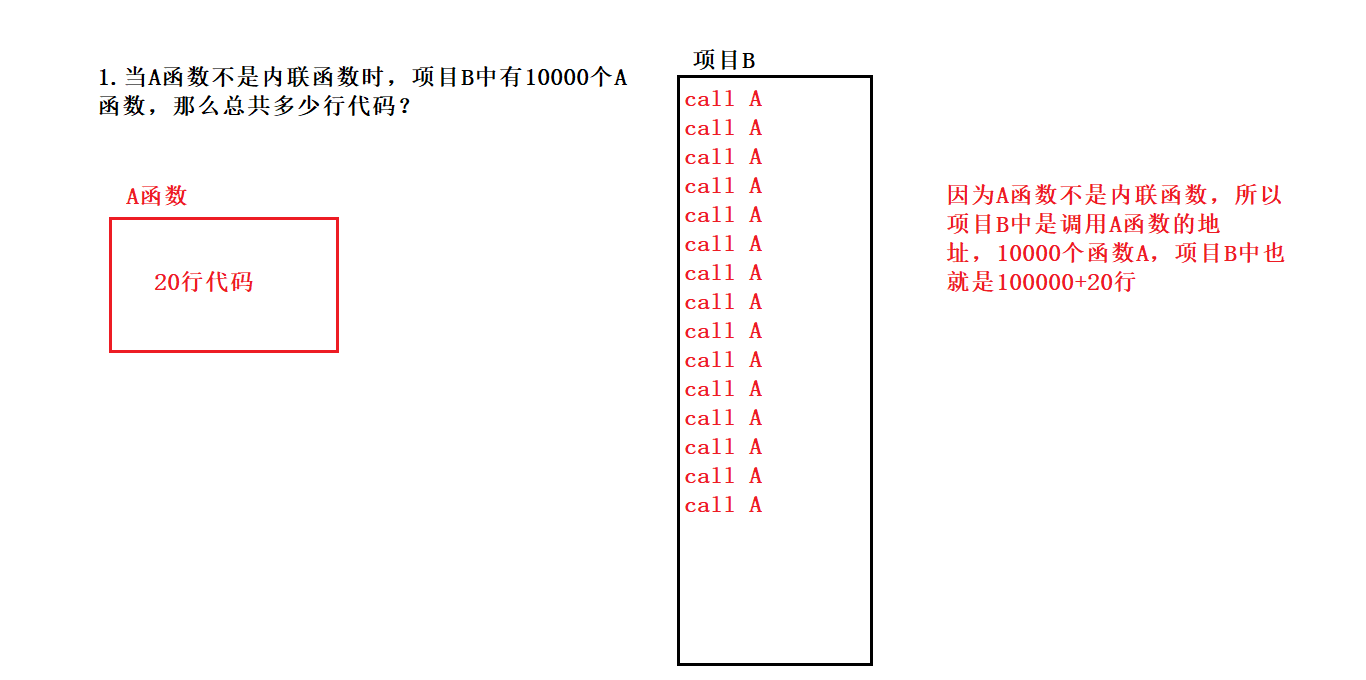
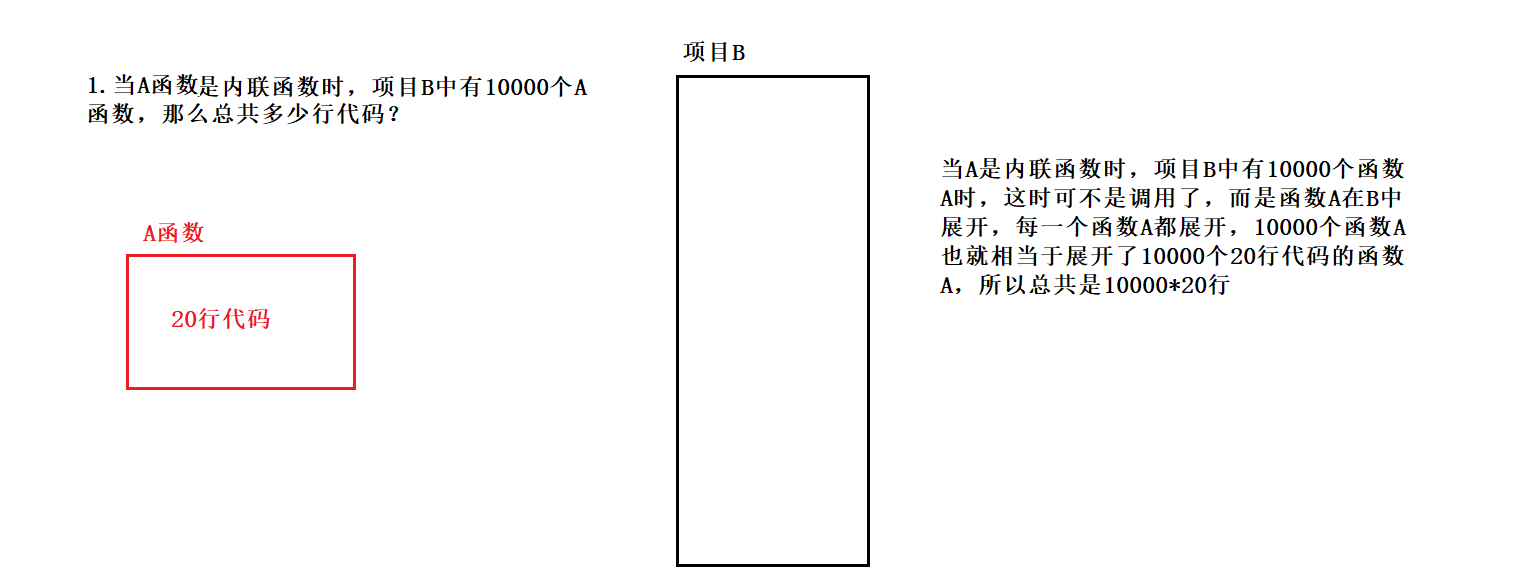
而当函数A代码量很时,又是内联函数,结果会使项目B中生成的可执行程序变大,使代码膨胀。所以长的函数不适合作为内联函数。
但其实编译器设计者也注意到这点,所以在设计时就规定,inline对于编译器仅仅只是一个建议,最终是否会成为内联函数,编译器自己决定,也就是编译器不相信你,大千世界无奇不有,谁知道哪个程序员整幺子然后还要编译器背锅呢。
所以像比较长的函数,递归函数类似的函数就算加了inline,编译器也会将之否决掉。
还有定义内联函数时,声明和定义不能分开定义。不然会存在链接问题。
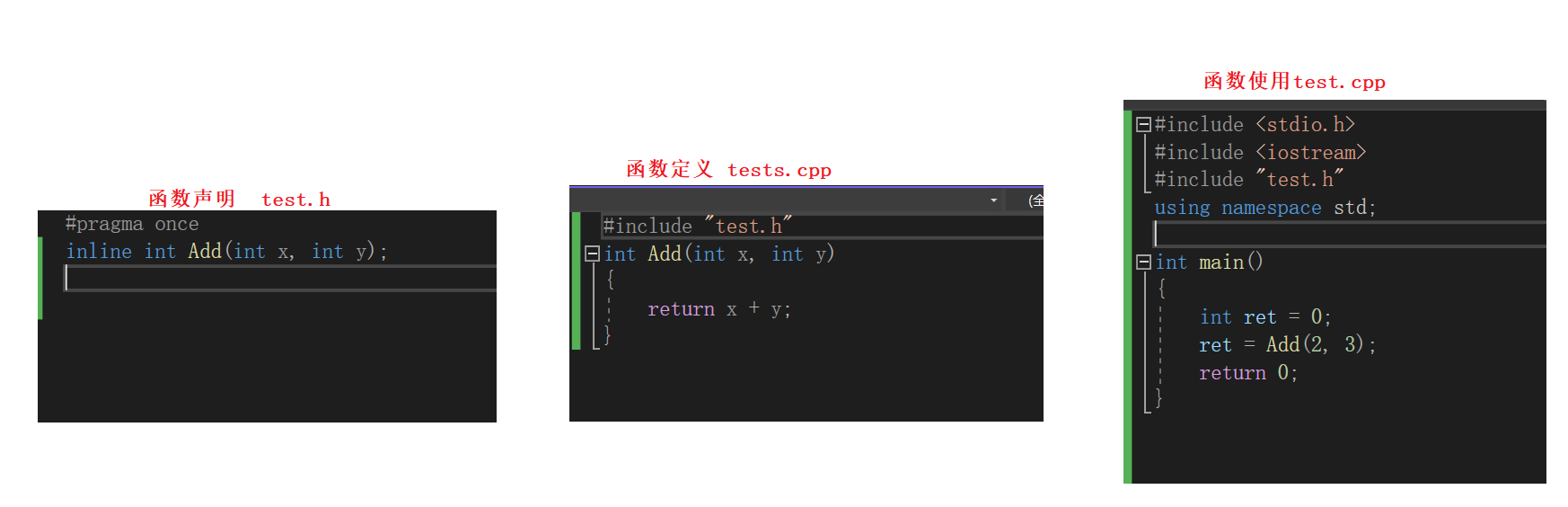
因为在编译期间内联函数就已经展开,哪里函数没有地址,也不会进入符号表,但是当使用函数时,只要函数的声明,没有函数的地址,那么就要去定义里去找函数的地址,但遗憾的是,内联函数已经展开,所以没有地址存在,所以最终是无法编译通过的。
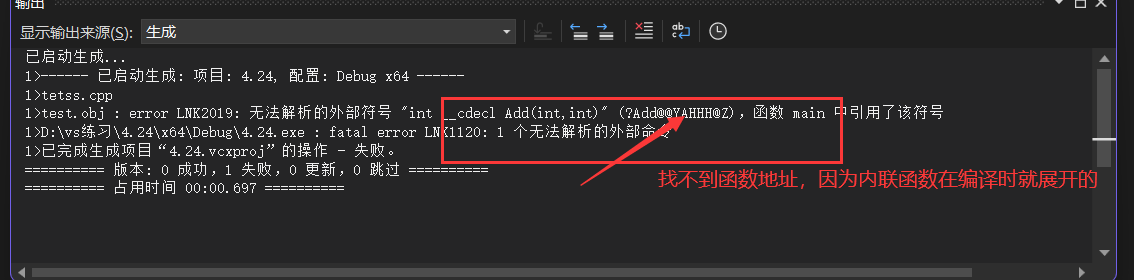
所以正确的写法是,定义和声明不分开,也就是直接在.h文件里将函数的声明和定义一起写即可。
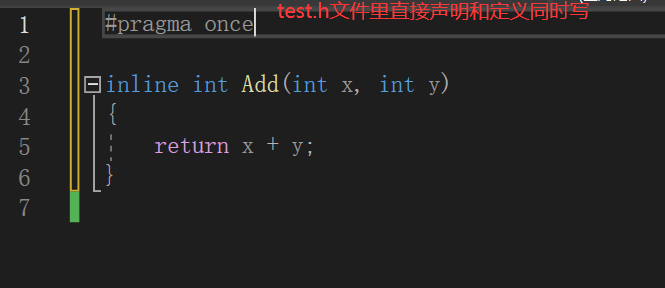
所有要用该函数的地方,直接在头文件里声明定义就可以了。这样就不存在链接的问题。
Ⅲ.总结
- 1.inline是一种以空间换时间的做法,如果编译器将函数当作内联函数处理,那么在编译阶段,会用函数体替换函数调用。
缺陷:目标文件会变大。
优势:减少调用开销,提高程序运行效率。
- 2.inline 对于编译器只是一个建议,不同编译器关于inline实现机制不同,一般对于函数规模较小的(即函数不是长的),不是递归,并且是频繁调用的函数采取inline修饰,否则编译器会忽略inline的特性。
在C++prime中也说过:内联函数只是向编译器发出的一个请求,编译器可以选择忽略这个请求。
3.inline内联函数不能声明和定义分离,分离会导致链接问题,因为inline分离,内联函数在编译时就展开,没有函数地址,而声明又没有地址,在链接时找不到定义里的地址。
②.指针空值nullptr(C++11)
Ⅰ.C++98中的指针空值
在良好的C/C++编程习惯中,声明一个变量时最好给该变量一个合适的初始值,否则可能会出现不可预料的错误,比如未初始化的指针。如果一个指针没有合法的指向,那么我们是用NULL来对其初始化的。
int *a =NULL;
//指针不知道指向
NULL实际上是一个宏,在传统的C头文件(stddef.h)中是这样定义的:
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif
可以看到,NULL可能被定义为字面常量0,或者被定义为无类线指针(void*)的常量。
但是不论是哪种定义,在C++中使用空值的指针时,都会不可避免的遇到一些问题。
void f(int)
{
cout << "f(int)" << endl;
}
void f(int*)
{
cout << "f(int*)" << endl;
}
两个同名函数构成重载,一个参数是int 类型,一个参数是int*类型
如果我们调用这两个函数该如何调用呢?
int main()
{
f(0);//调用第一个
f(NULL);//这个调用第几个函数呢?
return 0;
}
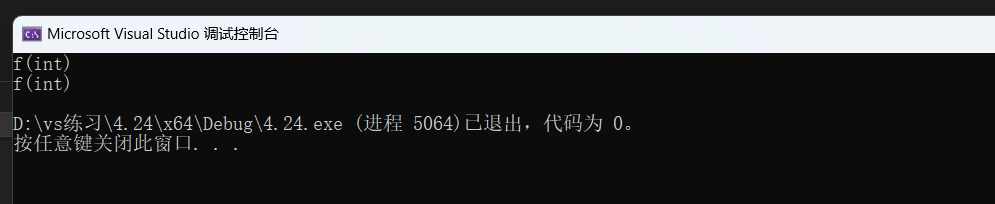
从结果我们可以知道,f(0)和f(NULL)都调用的是第一个函数,可是我们本意是向f(NULL)调用第二个函数的。
因为NULL定义就是字母常量0或者无类型的(void*)常量,所以它会调用第一个函数,而第二个函数的参数是int *类型的。
在C++98中,字面常量0既可以是一个整形数字,也可以是无类型的指针常量,但是编译器默认情况下将其看成一个整形常量,如果要将其按照指针方式使用,必须要对其进行强制转化由NULL强制转化为int*类型
f((int*)NULL);
这样才可以调用第二个函数。
但在C++中引入nullptr关键字,表示指针空值。
所以我们直接这样写f(nullptr)就可以调用第二个函数
void f(int)
{
cout << "f(int)" << endl;
}
void f(int*)
{
cout << "f(int*)" << endl;
}
int main()
{
f(0);
f(NULL);
f((int*)NULL);
f(nullptr);
return 0;
}
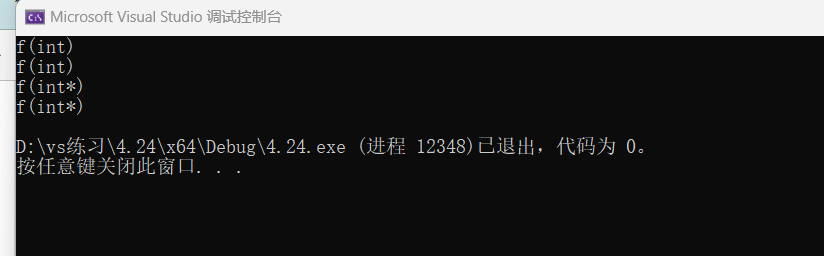
Ⅱ.注意:
1.在使用nullptr表示指针空值时,不需要包含头文件,因为nullptr是C++11作为新关键字引入的。
2.在C++11中,sizeof(nullptr)与sizeof((void)0)所占的字节数相同。
3.为了提高代码的健壮性,在代码中最好使用nullptr表示指针空值。