文章目录
- 前言
- 例题
- 一、最后一块石头的重量
- 二、数据流中的第 K 大元素
- 三、前K个高频单词
- 四、数据流的中位数
- 结语

前言
什么是优先级队列算法呢?它的算法原理又该怎么解释?
优先级队列(堆)算法是一种特殊的数据结构和算法,它就像一个特殊的排队系统,在这个系统中,每个元素都有一个优先级,优先级高的元素会先被处理。下面用一个形象的例子来解释它的原理。
想象有一个幼儿园的小朋友们要排队领糖果。一般的排队是按照先来后到的顺序,但是在这个特殊的队列里,是按照小朋友的 “乖巧程度” 来决定谁先领糖果的,“乖巧程度” 就是我们说的优先级。
堆这种数据结构,就像是一个特殊的队伍形状,它通常是用一个完全二叉树来实现的。简单来说,完全二叉树就是一种很有规律的树状结构,它的每一层都是填满的,只有最下面一层可能从右到左缺少一些节点。
在这个 “小朋友排队领糖果” 的例子里,我们把每个小朋友看作是树中的一个节点,而小朋友的 “乖巧程度” 就是节点的值。在堆中,有两种常见的类型,一种是大根堆,一种是小根堆。大根堆的特点是每个节点的值都大于或等于它的子节点的值,就好像在这个排队系统中,每个位置上的小朋友都比他后面的小朋友更乖巧(或者一样乖巧)。小根堆则相反,每个节点的值都小于或等于它的子节点的值。
当有新的小朋友要加入排队时,我们会把他放在树的最后一个位置,然后再根据他的 “乖巧程度” 来调整他的位置,让他和他的 “家长”(父节点)比较。如果他比他的 “家长” 更乖巧,就会和 “家长” 交换位置,一直到找到他合适的位置,保证堆的特性不变。这就好比在排队时,来了一个新小朋友,我们要看看他是不是比前面的小朋友更乖巧,如果是,就让他往前排,直到他找到自己合适的位置。
当要给小朋友发糖果时,我们总是先从队首(也就是树的根节点)开始,因为那里是最乖巧的小朋友。然后,我们把最后一个位置的小朋友放到根节点的位置,再重新调整堆,让它再次满足堆的特性。这样,我们就可以保证每次发糖果都是先发给最乖巧的小朋友,而且整个排队系统(堆)始终保持有序。
通过这样的方式,优先级队列(堆)算法能够高效地处理元素的插入和删除操作,快速找到优先级最高(或最低)的元素,在很多需要根据元素优先级来进行操作的场景中都非常有用,比如任务调度、数据排序等。
下面本文将通过例题来为大家详细讲解有关优先级队列算法的算法问题
例题
一、最后一块石头的重量
- 题目链接:最后一块石头的重量
- 题目描述:
有一堆石头,每块石头的重量都是正整数。 每⼀回合,从中选出两块最重的石头,然后将它们⼀起粉碎。假设石头的重量分别为 x 和 y,且 x<= y。那么粉碎的可能结果如下:
• 如果 x == y,那么两块石头都会被完全粉碎;
• 如果 x != y,那么重量为 x 的石头将会完全粉碎,而重量为 y 的石头新重量为 y-x。 最后,最多只会剩下一块石头。返回此石头的重量。如果没有石头剩下,就返回 0。
示例:
输入:[2,7,4,1,8,1]
输出:1
解释:先选出 7 和 8,得到 1,所以数组转换为 [2,4,1,1,1], 再选出 2 和 4,得到 2,所以数组转换为 [2,1,1,1], 接着是 2 和 1,得到 1,所以数组转换为 [1,1,1], 最后选出 1 和 1,得到 0,最终数组转换为 [1],这就是最后剩下那块石头的重量。 提示:
1 <= stones.length <= 30
1 <= stones[i] <= 1000
- 解法:(利用堆):
算法思路: 其实就是⼀个模拟的过程:
• 每次从石堆中拿出最大的元素以及次大的元素,然后将它们粉碎;
• 如果还有剩余,就将剩余的⽯头继续放在原始的石堆里面
重复上面的操作,直到石堆里面只剩下⼀个元素,或者没有元素(因为所有的石头可能全部抵消了) 那么主要的问题就是解决:
• 如何顺利的拿出最⼤的石头以及次大的石头;
• 并且将粉碎后的石头放入石堆中之后,也能快速找到下⼀轮粉碎的最大石头和次大石头; 这不正好可以利用堆的特性来实现嘛?
• 我们可以创建⼀个大根堆;
• 然后将所有的石头放入大根堆中;
• 每次拿出前两个堆顶元素粉碎⼀下,如果还有剩余,就将剩余的石头继续放入堆中; 这样就能快速的模拟出这个过程。 - 代码示例:
public int lastStoneWeight(int[] stones) {
// 1. 创建⼀个⼤根堆
PriorityQueue<Integer> heap = new PriorityQueue<>((a, b) -> b - a);
// 2. 把所有的⽯头放进堆⾥⾯
for (int x : stones) {
heap.offer(x);
}
// 3. 模拟
while (heap.size() > 1) {
int a = heap.poll();
int b = heap.poll();
if (a > b) {
heap.offer(a - b);
}
}
return heap.isEmpty() ? 0 : heap.peek();
}
二、数据流中的第 K 大元素
- 题目链接:数据流的第K大元素
- 题目描述:
设计一个找到数据流中第 k 大元素的类(class)。注意是排序后的第 k 大元素,不是第 k 个不同的元素。 请实现KthLargest 类:
KthLargest(int k, int[] nums) 使用整数 k 和整数流 nums 初始化对象。
int add(int val) 将 val 插入数据流 nums 后,返回当前数据流中第 k 大的元素。
示例:
输入:[“KthLargest”, “add”, “add”, “add”, “add”, “add”]
[[3, [4, 5, 8, 2]], [3], [5], [10], [9], [4]]
输出:
[null, 4, 5, 5, 8, 8]
解释:
KthLargest kthLargest = new KthLargest(3, [4, 5, 8, 2]);
kthLargest.add(3); // return 4
kthLargest.add(5); // return 5
kthLargest.add(10); // return 5
kthLargest.add(9); // return 8
kthLargest.add(4); // return 8
提示:1 <= k <= 10^4
0 <= nums.length <= 10^4
-104 <= nums[i] <= 10^4
-104 <= val <= 10^4
最多调用 add 方法 10^4 次 题目数据保证,在查找第 k 大元素时,数组中至少有 k 个元素
-
解法(优先级队列):
算法思路: 我相信,大家看到 TopK 问题的时候,兄弟们应该能立马想到「堆」当然本题也是一样通过堆来解决的 -
代码示例:
class KthLargest {
// 创建⼀个⼤⼩为 k 的⼩根堆
PriorityQueue<Integer> heap;
int _k;
public KthLargest(int k, int[] nums) {
_k = k;
heap = new PriorityQueue<>();
for (int x : nums) {
heap.offer(x);
if (heap.size() > _k) {
heap.poll();
}
}
}
public int add(int val) {
heap.offer(val);
if (heap.size() > _k) {
heap.poll();
}
return heap.peek();
}
}
三、前K个高频单词
- 题目链接:前K个高频单词
- 题目描述:
给定⼀个单词列表 words 和⼀个整数 k ,返回前 k 个出现次数最多的单词。 返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率, 按字典顺序排序。
示例 1:
输入:words = [“i”, “love”, “leetcode”, “i”, “love”, “coding”], k = 2
输出:[“i”, “love”]
解析:
“i” 和 “love” 为出现次数最多的两个单词,均为 2 次。 注意,按字母顺序 “i” 在 “love” 之前。
示例 2:
输入:[“the”, “day”, “is”, “sunny”, “the”, “the”, “the”, “sunny”, “is”, “is”], k = 4
输出:[“the”, “is”, “sunny”, “day”]
解析:
“the”, “is”, “sunny” 和 “day” 是出现次数最多的四个单词, 出现次数依次为 4, 3, 2 和 1 次。
注意:1 <= words.length <= 500
1 <= words[i] <= 10
words[i] 由小写英文字母组成。 k 的取值范围是 [1, 不同 words[i] 的数量]
进阶:尝试以 O(n log k) 时间复杂度和 O(n) 空间复杂度解决
-
解法(堆):
算法思路: • 稍微处理⼀下原数组:
a. 我们需要知道每⼀个单词出现的频次,因此可以先使用哈希表,统计出每⼀个单词出现的频次;
b. 然后在哈希表中,选出前 k大的单词(为什么不在原数组中选呢?因为原数组中存在重复的单词,哈希表里面没有重复单词,并且还有每⼀个单词出现的频次)
• 如何使用堆,拿出前 k 大元素:
a. 先定义⼀个自定义排序,我们需要的是前 k 大,因此需要⼀个小根堆。但是当两个字符串的频次相同的时候,我们需要的是字典序较小的,此时是⼀个大根堆的属性,在定义比较器的时候需要注意!
▪ 当两个字符串出现的频次不同的时候:需要的是基于频次比较的小根堆
▪ 当两个字符串出现的频次相同的时候:需要的是基于字典序比较的大根堆
b. 定义好比较器之后,依次将哈希表中的字符串插人到堆中,维持堆中的元素不超过 k 个;
c. 遍历完整个哈希表后,堆中的剩余元素就是前 k 大的元素 -
代码示例:
public List<String> topKFrequent(String[] words, int k) {
// 1. 统计⼀下每⼀个单词出现的频次
Map<String, Integer> hash = new HashMap<>();
for (String s : words) {
hash.put(s, hash.getOrDefault(s, 0) + 1);
}
// 2. 创建⼀个⼤⼩为 k 的堆
PriorityQueue<Pair<String, Integer>> heap = new PriorityQueue<>((a, b) ->{
// 频次相同的时候,字典序按照 ⼤根堆的⽅式排列
if (a.getValue().equals(b.getValue())) {
return b.getKey().compareTo(a.getKey());
}
return a.getValue() - b.getValue();
});
// 3. TopK 的主逻辑
for (Map.Entry<String, Integer> e : hash.entrySet()) {
heap.offer(new Pair<>(e.getKey(), e.getValue()));
if (heap.size() > k) {
heap.poll();
}
}
// 4. 提取结果
List<String> ret = new ArrayList<>();
while (!heap.isEmpty()) {
ret.add(heap.poll().getKey());
}
// 逆序数组
Collections.reverse(ret);
return ret;
}
四、数据流的中位数
- 题目链接:数据流的中位数
- 题目描述:
中位数是有序整数列表中的中间值。如果列表的大小是偶数,则没有中间值,中位数是两个中间值的平均值。
• 例如 arr = [2,3,4] 的中位数是 3 。
• 例如 arr = [2,3] 的中位数是 (2 + 3) / 2 = 2.5 。
实现 MedianFinder 类:
• MedianFinder() 初始化 MedianFinder 对象。
• void addNum(int num) 将数据流中的整数 num 添加到数据结构中。
• double findMedian() 返回到⽬前为⽌所有元素的中位数。与实际答案相差 10-5 以内的答案将被 接受。
示例 1:
输入:[“MedianFinder”, “addNum”, “addNum”, “findMedian”, “addNum”, “findMedian”][[], [1], [2], [], [3], []]
输出:[null, null, null, 1.5, null, 2.0]
解释
MedianFinder medianFinder = new MedianFinder();
medianFinder.addNum(1); // arr = [1]
medianFinder.addNum(2); // arr = [1, 2]
medianFinder.findMedian(); // 返回 1.5 ((1 + 2) / 2)
medianFinder.addNum(3); // arr[1, 2, 3]
medianFinder.findMedian(); // return 2.0
提⽰:
-10^5 <= num <= 10^5
在调用findMedian 之前,数据结构中⾄少有⼀个元素 最多 5 * 10^4 次调用addNum 和 findMedian
-
解法(利用两个堆):
算法思路: 这是⼀道关于「堆」这种数据结构的⼀个「经典应用」。
我们可以将整个数组「按照大小」平分成两部分(如果不能平分,那就让较小部分的元素多⼀个),较小的部分称为左侧部分,较大的部分称为右侧部分:
• 将左侧部分放入「大根堆」中,然后将右侧元素放入「小根堆」中;
• 这样就能在 O(1) 的时间内拿到中间的⼀个数或者两个数,进而求的平均数。
如下图所示:
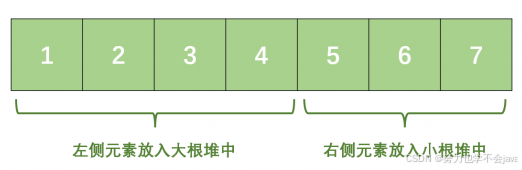
于是问题就变成了「如何将⼀个⼀个从数据流中过来的数据,动态调整到大根堆或者小根堆中,并且保证两个堆的元素⼀致,或者左侧堆的元素比右侧堆的元素多⼀个」为了方便叙述,将左侧的「大根堆」记为 left ,右侧的「小根堆」记为 right ,数据流中来的 「数据」记为 x 。 其实,就是⼀个「分类讨论」的过程:
如果左右堆的「数量相同」, left.size() == right.size() :
a. 如果两个堆都是空的,直接将数据 x 放⼊到 left 中;
b. 如果两个堆非空:
i. 如果元素要放入左侧,也就是 x <= left.top() :那就直接放,因为不会影响我们制定的规则;
ii. 如果要放入右侧
• 可以先将 x 放入 right 中,
• 然后把 right 的堆顶元素放入left 中 ;
如果左右堆的数量「不相同」,那就是 left.size() > right.size() :
a. 这个时候我们关心的是 x 是否会放⼊ left 中,导致 left 变得过多:
i. 如果 x 放⼊ right 中,也就是 x >= right.top() ,直接放;
ii. 反之,就是需要放入 left 中:
• 可以先将 x 放⼊ left 中,
• 然后把 left 的堆顶元素放入right 中 ; 只要每⼀个新来的元素按照「上述规则」执行,就能保证 left 中放着整个数组排序后的「左半部分」, right 中放着整个数组排序后的「右半部分」,就能在 O(1) 的时间内求出平均数。 -
代码示例:
class MedianFinder {
PriorityQueue<Integer> left;
PriorityQueue<Integer> right;
public MedianFinder() {
left = new PriorityQueue<Integer>((a, b) -> b - a); // ⼤根堆
right = new PriorityQueue<Integer>((a, b) -> a - b); // ⼩根堆
}
public void addNum(int num) {
// 分情况讨论
if (left.size() == right.size()) {
if (left.isEmpty() || num <= left.peek()) {
left.offer(num);
} else {
right.offer(num);
left.offer(right.poll());
}
} else {
if (num <= left.peek()) {
left.offer(num);
right.offer(left.poll());
} else {
right.offer(num);
}
}
}
public double findMedian() {
if (left.size() == right.size()) return (left.peek() + right.peek()) /
2.0;
else return left.peek();
}
}
结语
本文到这里就结束了,主要通过几道优先级队列相关例题介绍了数据结构堆(优先级队列)在算法中的应用,更深一步了解了优先级队列的用法。
以上就是本文全部内容,感谢各位能够看到最后,如有问题,欢迎各位大佬在评论区指正,希望大家可以有所收获!创作不易,希望大家多多支持!
最后,大家再见!祝好!我们下期见!