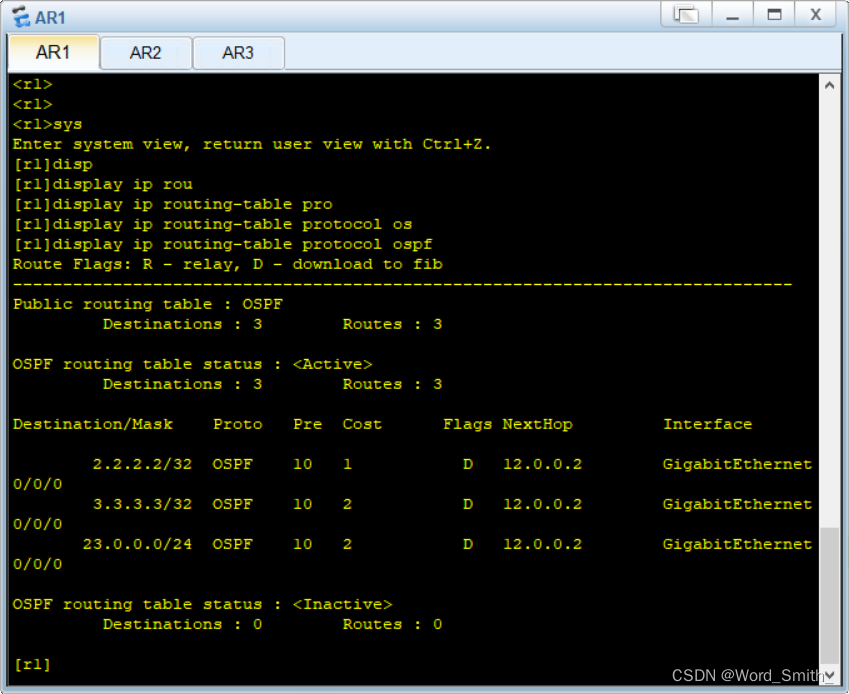
堆排序是最基本的排序算法,简单来说就是把一堆数据(数组)分成两个相等的部分,其中一个部分作为数组的开头,另一个部分作为数组的结尾。之后在对这两个相等的部分进行比较,如果在比较之后发现这个数组中有一项小于等于另外一项,则将这两个相等的部分合并起来,并将它重新放回数组中间。如此进行,直到最后完成排序为止。 堆排序算法有如下优点: 1、递归调用 2、速度快 3、对所有元素都进行一次比较 4、易于理解,容易实现 5、可以进行并行计算 6、内存消耗低 7、支持并发执行 8、程序优化难度低
-
1.算法思想
在堆中进行排序时,我们可以将一个数组分成两部分,分别称为堆头和堆尾,堆头可以是数组的某个元素,也可以是数组的任意位置。当对这个数组进行排序时,我们需要将堆头的元素取出,并将它放到数组的最后一位。 例如对于一个数组:[0,1],其中0是该数组的最小元素。当我们对这个数组进行排序时,首先需要对[0]这个元素进行比较,如果这个元素小于[0]时则将它取出并放到堆头;然后将[1]元素也取出并放到堆头;最后将[1]元素和[0]元素比较,如果其中一个大于另一个则将它们合并起来重新放到数组的末尾。 需要注意的是,如果我们没有在堆中找到任何元素(假设我们已经找到了),那么堆中的所有元素都是相同的。当我们发现数组中有一个元素比其他所有元素大时,则说明这个元素是比其他所有元素小的。此时可以把这个数组重新放回堆头中。
-
2.参数设置
堆排序的参数是 arr (numbers_list),用来存储堆中最大的元素。这个参数会在数组大小固定时自动调整,而且堆中最大的元素和数组长度一定,所以每次操作时都会动态调整。 具体来讲就是: 在第一次排序时,堆中最大的元素就是当前堆的第一个元素,那么当数组长度为O (1)时,就要将当前堆中最大的元素移动到第二个位置。 当堆中元素较多时,可以使用循环对其进行合并,循环结束后会将当前堆中所有元素重新排序。对于多个元素来说,可能会有更好的处理方式。 例如在第一次排序时,发现数组长度为2的元素已经小于等于数组长度为3的元素,但是这个数组长度却比3长很多,那么这时就需要将数组中小于3的元素移动到2到3之间。如果不移动,则会导致两个不相等的数据放在一块,因此需要移动数组长度为2的元素才能使两个相等。 如果将数组长度为3的元素移动到2到3之间后发现仍然小于3,则需要将数组中小于3的元素移动到2到3之间。 也可以使用“/”将堆中最大的元素移动到其他位置。具体用法可以参考 python中“。 replace”函数
-
3.堆的创建
堆的创建有两种方式,第一种是使用链表来存储堆,第二种是使用栈来存储堆。使用链表的方式需要一个链表,而使用栈的方式则需要一个栈。 如果你想创建一个有序的堆,那么就需要先将数组分割成两个部分,即两个元素相等的部分,然后将它们放入到一个栈中。此时该栈的地址为0x00010,即“第一个元素”对应的位置。之后再对这两个元素进行比较,如果它们相等的话,则将它们放在同一个栈顶;如果有一项小于另一项,则将它们移到栈底;如此进行下去即可完成排序。 但是如果你想在一个有序的堆中存储堆元素,那么你就需要创建一个链表来存储堆。链表的结构如下: 我们可以看到,在堆中创建了两个部分,这两个部分分别是第一个元素和第二个元素。但是这两个元素都是不相等的。也就是说我们在创建堆时,必须先将第一个元素和第二个元素都放入到一个链表中去。 如果我们只有两个元素需要进行比较的话,那么就可以直接将它们放到同一个链表中去,但是如果我们要将两个元素都放入到同一个链表中去的话,那么就必须先对这两个元素进行比较。如果比较之后发现第一个元素小于第二个元素的话,则将它们移到链表的顶层;如果比较之后发现第二个元素大于第一个元素的话,则将它们移到栈底。
-
4.堆的大小
堆是一个临时数组,其大小在堆的生命周期内保持不变,其大小由两部分组成: 堆的大小可以用下标(或堆中元素的数量)表示: 为了不产生重复元素,最小的堆包含一个元素总数,其下标是一个常数(例如8)。 如果当前堆已经大于最小的堆,则新生成一个新的堆,并将老的堆放到新生成的堆中。如此类推。 在每次迭代时,最小堆中包含之前数组中最大元素。在每个迭代后,新生成的堆将元素总数减1。如果当前数组中的所有元素都小于最小堆中最大元素,则将这些元素重新放回原来的位置。在每个迭代后,都会有一个新的堆(与前一个相比)。
-
5.比较
堆排序的时间复杂度为O (1),因此它也是时间复杂度为O (n)的算法。但是堆排序对于元素较多的情况,执行速度会比较慢,可以通过二分法来减少堆排序的时间复杂度。 如果堆排序在执行过程中,发现有数组长度小于数组最大值时,可以直接把数组最大值部分移动到数组长度最小的位置上,然后再重新进行堆排序。因为在堆排序过程中,每次都要移动元素到数组中间位置,所以时间复杂度为O (n)。
-
6.输出结果
堆排序是基于循环的,循环的次数也是从0开始,一直到堆顶。我们知道一个有序的数组只有一个元素,而堆排序正好能把所有元素都进行一次比较,所以我们在进行堆排序的时候只需要把需要比较的元素放入到堆中,再重复以上操作即可。 那么堆排序适合多少个数组呢?这个问题也不是很好回答,因为不同的算法适用于不同的情况。如果我们需要对一堆元素进行比较的话,我们可以采用归并排序或者直接找出第一个元素。而如果我们想要找到数组中的最大值或者最小值的话,我们则可以采用冒泡排序或选择排序来完成。 以上内容为个人理解,有错误的地方还望指正!
-
以下是Java实现的堆排序代码:
1. 递归实现
```java
public static void heapSort(int[] arr) {
if (arr == null || arr.length == 0) {
return;
}
int len = arr.length;
// 构建最大堆
buildMaxHeap(arr, len);
// 交换堆顶元素和末尾元素,然后重新调整堆
for (int i = len - 1; i > 0; i--) {
swap(arr, 0, i);
len--;
heapify(arr, 0, len);
}
}
private static void buildMaxHeap(int[] arr, int len) {
for (int i = len / 2; i >= 0; i--) {
heapify(arr, i, len);
}
}
private static void heapify(int[] arr, int i, int len) {
int left = 2 * i + 1;
int right = 2 * i + 2;
int largest = i;
if (left < len && arr[left] > arr[largest]) {
largest = left;
}
if (right < len && arr[right] > arr[largest]) {
largest = right;
}
if (largest != i) {
swap(arr, i, largest);
heapify(arr, largest, len);
}
}
private static void swap(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
```
2. 非递归实现
```java
public static void heapSort(int[] arr) {
if (arr == null || arr.length == 0) {
return;
}
int len = arr.length;
// 构建最大堆
for (int i = len / 2; i >= 0; i--) {
heapify(arr, i, len);
}
// 交换堆顶元素和末尾元素,然后重新调整堆
for (int i = len - 1; i > 0; i--) {
swap(arr, 0, i);
int j = 0;
int k = 2 * j + 1;
while (k < i) {
if (k + 1 < i && arr[k + 1] > arr[k]) {
k++;
}
if (arr[k] > arr[j]) {
swap(arr, k, j);
j = k;
k = 2 * j + 1;
} else {
break;
}
}
}
}
private static void heapify(int[] arr, int i, int len) {
int left = 2 * i + 1;
int right = 2 * i + 2;
int largest = i;
if (left < len && arr[left] > arr[largest]) {
largest = left;
}
if (right < len && arr[right] > arr[largest]) {
largest = right;
}
if (largest != i) {
swap(arr, i, largest);
heapify(arr, largest, len);
}
}
private static void swap(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
```