文章目录
- 前言
- 文献阅读
- 摘要
- 简介
- 方法
- 结果
- 结论
- 时间序列预测学习
- 总结
前言
本周阅读文献《A novel hybrid model for water quality prediction based on synchrosqueezed wavelet transform technique and improved long short-term memory》,文献主要提出一种新型混合模型SWT-ISSA-LSTM,用于水质预测。由于水质参数原始时序数据受其他因素的影响,有一定的噪声干扰,将SWT方法应用于原始数据,进行挤压输出和带通滤波,可以实现数据降噪;将ISSA引入LSTM模型,计算LSTM模型的最优参数值,提高预测模型的准确性。另外,主要学习了在水质预测中常见的一些机理模型和数据驱动模型。
This week,I read an article which proposes a novel hybrid model, SWT-ISSA-LSTM, for water quality parameter prediction.Due to the influence of monitoring equipment, monitoring methods, water quality parameters time series bear certain complex noise interference. In order to improve the accuracy of water quality prediction, the SWT approach is applied to the raw data with simultaneous squeeze output and bandpass filtering to achieve data noise reduction. It introduces the ISSA into LSTM, and computes the optimal parameter values for the LSTM model to construct the ISSA-LSTM model.In addition,I mainly study some common mechanism models and data-driven models in water quality prediction.
文献阅读
题目:A novel hybrid model for water quality prediction based on synchrosqueezed wavelet transform technique and improved long short-term memory
作者:Chenguang Song, , , Leihua YaoChengya HuaQihang Ni
摘要
准确预测水质在水资源管理中至关重要。本研究侧重于流域系统中溶解氧(DO)等水质参数的预测。传统的循环神经网络(RNN)存在梯度消失或爆炸,无法解决长期依赖的问题,其实际应用有限。为了克服这一缺点,提出了一种改进的长短期记忆(LSTM)模型来提高模型的性能。此外,为了克服水质参数数据的非平稳性、随机性和非线性,采用混合模型以及同步挤压小波变换(SWT)对原始数据进行去噪。还实现了一种新的元启发式优化算法,即结合柯西突变和基于对立的学习(OBL)的改进麻雀搜索算法(ISSA),以计算LSTM模型的最优参数值。所提出的混合模型使用1年2010月至12年2016月在中国海河流域永定河和港南测量站测量的原始每周水质参数系列进行评估。采用独立的LSTM、ISSA-LSTM、SWT-LSTM、支持向量回归(SVR)和反向传播神经网络(BPNN)作为使用相同的数据集的比较预测模型。结果表明,该模型结合了SWT的强抗噪声鲁棒性和LSTM的非线性映射,在两个测量站的对等模型中具有最佳的预测性能。所提出的混合模型可作为水质预测的替代框架,为流域水质综合管理和污染物控制提供决策依据。
简介
由于时间、气候、产业发展和人流等不确定因素的影响,监测数据具有非线性特征。传统的预测方法基于实验判断、经验公式和数值模拟,很难从多个具有相关性的指标中剥离出相对独立的影响因素,因此无法建立普遍适用的数学模型(Rajaee et al., 2020)。自21世纪以来,机器学习方法随着人工智能的发展而迅速发展(Xu and Liu,2013)。学者们试图用数据驱动的方法规避传统水力学模型的多方面建模要求和复杂的参数校正过程,而是直接探索数据中的潜在规律。由于人工神经网络(ANN)具有很强的非线性能力,可以无限逼近任何函数,因此在水质预测中得到了广泛的应用。然而,ANN的结构很简单,不能通过保留先前的时间信息来学习时间序列数据(Khan和Chai,2017)。递归神经网络 (RNN) 也用于水质预测,因为它们具有嵌入式反馈、循环结构(Zhang 等人,2020 年),这使他们能够保留先前时刻的信息并使用先前的信息来预测当前信息。然而,RNN在梯度转移方面存在缺点,无法解决长期依赖问题(Liu等人,2019a,Liu等人,2019b)。作为RNN的一种变体,长短期记忆(LSTM)通过在网络结构中引入存储单元,可以有效地描绘时间数据之间的长期依赖性(Li等人,2018),并具有强大的时间序列处理能力,已被广泛开发,旨在解决各种环境工程和水质问题。
在 LSTM 的情况下,必须确定最佳超参数的近似值(Barzegar 等人,2020 年)。事实上,没有正式或数学方法来确定 LSTM 关键参数的适当“最优集”,正是关键参数选择不当导致许多当前预测模型的准确性较低(Baek 等人,2020 年)。如今,为了克服这一缺点,一种更有效可行的方法是通过元启发式优化算法优化目标参数,包括麻雀搜索算法(SSA)、粒子群优化算法(Afshar等人,2013)、蝙蝠算法(Ehteram等人,2018)、灰狼优化算法(Tikhamarine等人,2020)、鲸鱼优化算法(Yan等人,2018)等。Li等人(2020)表明,2020年提出的SSA在各方面的表现都远远优于其他基于生物的群优化算法,具有巨大的应用潜力。尽管SSA算法性能优越,但随着后期迭代中种群多样性的降低,基本SSA容易陷入局部极端。改进SSA算法的研究很少,其中值得一提的是,Mao和Zhang(2020)提出了一种结合柯西突变和基于对立的学习(OBL)的改进麻雀搜索算法(ISSA),成功解决了SSA局部最优抵抗力弱的问题。到目前为止,还没有关于将ISSA应用于LSTM参数优化的研究。
由于温度、水文气象和人类活动等因素的影响,水质参数时间序列数据呈现出非线性、非平稳和随机性特征并且由于监测设备、监测方法、水质参数时间序列的影响,具有一定的复杂噪声干扰。为了提高水质预测的准确性,广泛研究了基于信号分解技术的非平稳原始水质时间序列降噪预处理,可以深入挖掘水质序列的所有特征,减少噪声对水质序列的干扰。目前,小波变换(WT)、经验模态分解(EMD)和希尔伯特-黄变换(HHT)是常用的信号分解技术(He和Chen,2010),但这些传统方法存在一些缺陷,例如WT需要选择合适的小波基来达到更好的降噪效果,因为不同的小波基有不同的降噪效果。近年来,基于时频分析的小波阈值去噪方法因其计算简单、去噪效果好而得到广泛应用。同步挤压小波变换(SWT)通过在频率方向上挤压连续小波变换时频图,可以获得更高精度的时频曲线,有效改善了非线性复信号时频分析中的频谱重叠现象。SWT对噪声也有更好的鲁棒性,当信号被强噪声污染时,SWT仍然可以获得清晰的时频曲线和基本不变的分解结果。
文献的主要贡献:
1)将SWT方法应用于原始数据,同时进行挤压输出和带通滤波,以实现数据降噪。
2)将ISSA引入LSTM,计算LSTM模型的最优参数值,构建ISSA-LSTM模型。
3)提出SWT-ISSA-LSTM混合方法作为水质预测的替代框架,测试并验证其有效性。
方法
ISSA
对于本文选择的 LSTM 模型,有四个参数对算法的性能有重要影响,分别是 LSTM 隐含层 L 中的神经元数量L1, L2 (L1和 L2参考第一层的LSTM单元数和第二层的LSTM单元数),学习率Lr和训练迭代次数 K。这四个关键参数用作粒子搜索的特征,并使用ISSA算法调整和优化LSTM模型。
SSA
SA起源于麻雀的觅食行为和反捕食行为理论。SSA由薛和沈(2020)提出。该算法新颖,具有优化能力强、收敛速度快等优点。SSA主要模拟麻雀觅食的过程。麻雀觅食过程是生产者-捕食者模型,它叠加了检测和预警机制。容易找到食物的个体麻雀是生产者,其他个体是捕食者。同时,选择人群中一定比例的个体进行调查和预警。如果发现危险,就会放弃食物,因为安全是第一位的。针对SSA算法在处理收敛精度低、易陷入局部最优的复杂函数优化问题时遇到的缺点,Mao和Zhang(2020)提出了一种基于柯西突变和OBL的改进麻雀搜索算法。重点通过以下三种策略提高SSA算法的全局优化性能。(1)
Sin chaotic初始化(2)动态自适应权重(3)柯西突变与OBL的整合
基于SWT-ISSA-LSTM的水质预测模型设计
(1)SWT方法用于水质参数时间序列数据的降噪,主要包括连续小波变换、瞬时频率采集和压缩复合三个子步骤。
(2)基于ISSA优化的LSTM模型,构建了ISSA-LSTM混合预测模型。
(3)将SWT去噪后的数据输入ISSA-LSTM模型进行滚动预测,并将误差评估指标与其他方法进行比较,分析模型的预测性能。
数据源
使用的数据来自中国海河流域永定河和港南测量站获得的每周自动水质监测报告,1/2010–12/2016 (http://www.cnemc.cn/sssj/szzdjczb/index.shtml),总共365周的数据。长江流域位于北纬35°–43°和东经112°–120°之间,总面积为3.18×105公里2。永定河和港南测量站的每周溶解氧(DO)监测数据。
误差评估标准
本研究采用9种不同的统计性能评价标准将模型输出结果与实际值进行比较。它们包括最大绝对误差(AE.max)、平均绝对误差 (MAE)、平均相对误差 (MAPE)、均方根误差 (RMSE)、决定系数 (R2)、相关系数 (CC)、纳什-萨特克利夫效率系数 (NSC)、一致性指数 (IA) 和 95% 置信水平的不确定性带宽度 (±1.96Se)。这些指标的计算方法如下:
(29)

结果
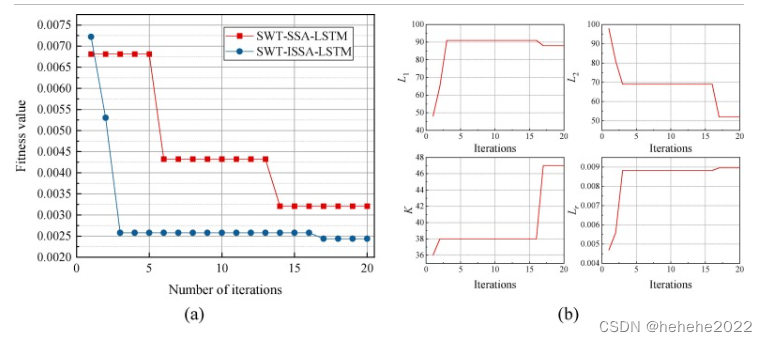
ISSA优化LSTM超参数的目标是最大限度地提高LSTM的精度,因此将LSTM在训练过程中得到的最佳均方误差(MSE)作为ISSA的适应度函数。训练过程中的误差收敛曲线如图9(a)所示,其中X轴是训练的迭代,Y轴是模型误差。随着迭代次数越来越大,SWT-ISSA-LSTM的误差迅速收敛。SWT-ISSA-LSTM的适应度演化曲线在5次迭代内达到要求的精度,然后保持最优适应度值,表现出较强的学习能力和良好的表现。图9(b)显示了ISSA优化的LSTM超参数的计算结果,即L1= 88, L2= 52,K = 47,并且Lr= 0.0090。
各种预测模型结果的比较
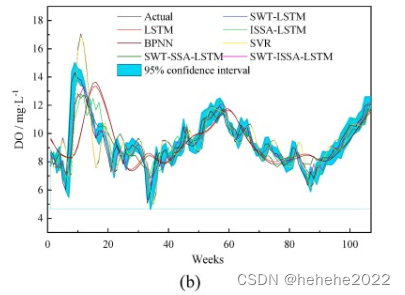
显示了不同模型的预测曲线。通过详细的局部观察可以发现,SWT-ISSA-LSTM预测曲线最接近实际值曲线,预测曲线基本落在实际值曲线的95%置信区间内,预测结果比其他模型更准确可靠。
结论
水质系列分析和预测是管理区域水资源的先决条件。针对传统RNN梯度消失或爆炸以及无法解决长期依赖性问题的问题,该文提出一种新型混合模型SWT-ISSA-LSTM,用于水质参数预测。采用SWT-LSTM、ISSA-LSTM、SWT-SSA-LSTM、SVR、BPNN和单个LSTM作为比较预测模型。采用6种不同的统计性能评价标准将模型输出结果与实际值进行比较。结果表明,结合柯西突变和OBL的元优化算法ISSA有效解决了SSA局部最优抵抗力弱的问题。本研究结果表明,SWT-ISSA-LSTM模型在所有同等模型中表现出最佳的预测性能。SWT-ISSA-LSTM模型收敛速度快,全局收敛速度快,可以获得更可靠合理的水质预测结果。因此,所提出的混合模型可以作为有效和简单的水污染预警和管理工具。
时间序列预测学习
水质预测
水质监测和预测是一个关键问题,因为每年都有大量污染物排放到海洋环境中。点源(例如市政和工业污水排放等)和非点源(例如农田和牲畜,水产养殖作业等)是两类常见的水污染源。必须提前做出准确可靠的水质预测,以减轻健康风险并治理水污染源。许多研究致力于建立各种模型来预测水质。水质预测引入了两大类预测模型,即基于物理和数据驱动的预测模型。基于物理的模型的优点是它们能够充分模拟水污染过程的化学机制,而它们的缺点是,如果数据丢失和环境发生变化,它们将无法模仿水污染过程。数据驱动的模型可以通过动态和自适应校正模型元素(例如结构、算法和参数)来处理非线性和高度随机的预测。
水质预测模型方法(机理模型)
机理模型可以很好的预测突发性污染事故后污染物指标迁移转化规律,水质断面的时间序列预测稳定性和准确性相对较差,数据要求较多。数据驱动模型能够深度挖掘水质的时间序列的季节性、趋势性、多元相关性特征,根据这些特征进行水质的预测,但对突发性污染事故后的水质预测较难。
在水质预测初期,主要是通过定性的研究污染物的扩散规模来模拟水质在河流中的迁移转换过程进行水质预测。最早的水质预测模型的一维稳态氧平衡模型(S-P 模型) , S-P模型的建立为河流水质机理模型的发展奠定了基础。在20世纪80年代前后,水质模型进入迅速发展阶段。在S-P水质模型的研究基础上,水质模型研究者们对不同污染物在水体中的反应开展进一步的研究,描述不同形态的污染物在水体中的特征。水质预测在此时期,涌现了许多研究成果,例如美国环境保护局(EPA)环境保护实验室开发的WASP模型,美国弗吉尼亚州海洋研究所开发的EFDC模型,由英国贝德福乌斯河水质模型发展而来的QUASAR模型,Liew将利用SWAT模型研究了流域的水文变化预测,取得很好的预测效果。丹麦水利研究所开发的MIKE系列模型。MIKE模型是一款致力于水环境和水资源方面研究的水质数学模型,是由丹麦水资源及水环境研究所(DHI)研究人员共同合作开发出来的。各国的研究者为避免水质机理模型建模的复杂,开始将数据驱动模型引入到水质预测中来,水质的预测不再限于河流污染物扩散机理的研究。数据驱动水质预测模型只需要将水质监测数据作为样本,根据数据的趋势变化及相关关系进行预测研究。主要的方法包括:时间序列法、灰色理论预测法、人工神经网络预测法、支持向量机预测法等等。
随着互联网及机器学习的高速发展,数据驱动模型进行水质预测应用越来越广泛,开始出现了多种模型的组合来提升模型准确率。所谓组合预测就是将不同预测方法进行适当的组合综合利用各种方法所提供的信息从而尽可能的提高预测精度。组合预测是把两个或两个以上的预测模型采用加权融合的方式组合成为一个模型。组合模型的关键是确定各个组合系数或加权系数基本思想堤充分利用每一种预测方法所包含的独立信息。
水质预测模型方法(数据驱动模型)
滑动平均模型、回归分析预测模型、灰色系统预测模型、支持向量机模型、SARIMA模型、LSTM神经网络模型
(1)滑动平均模型
基于简单滑动平均模型原理,通过增加新数据减少老数据,动态的计算时间序列的平均值,从而消除突变值对预测的影响,找出水质时间序列的变化趋势。移动平均模型适合具有长期趋势、明显的季节性和大流量的水质数据,移动平均模型水质预测精度较低,一般和其他趋势分析方法一起使用。
(2)回归分析预测模型
回归分析预测模型根据大量水质时间序列的数据,分析水质时间序列之间相关关系,建立实测值和预测值之间的回归方程,并将回归方程作为预测模型,根据水质实测值的数量变化规律来预测未来水质变化趋势。回归分析预测方法可以显示实测值和预测值之间的相关性,也可以探索不同尺度的水质变量之间的相互影响,例如温度变化和溶解氧浓度之间的相关性。回归分析模型总体来看算法比较简单,容易操作,但算法相对低级,对于复杂的水质预测问题精度较低。
(3)灰色系统预测模型
灰色系统预测方法通过识别各水质指标之间的相关关系,并找到灰色系统的变化规律,生成具有规则性水质数列,基于建立的微分方程模型,预测水质的未来发展趋势。预测方法是放弃传统的统计模式和概率分布的方法,积累不规则的原始数据,得到一个规律的平稳时间序列。灰色系统预测模型适用于中长期的水质预测,且所需样本小、计算量小、水质数据不需要规律、应用范围广,但预测精度相对较低。
(4)支持向量机模型
支持向量机SVR (Support Vector Regression)是将统计发展成一种学习理论作为基础的新型机器学习方法,能够解决那些困扰过去很多学者的关于小样本、非线性、过学习等现实的预测困难。迫近庞大非线性系统且学习泛化本领很强,拥有鲁棒性和稀少性。最开始被用于模式识别的分类,之后扩展到回归估计和非线性预测,即支持向量回归,然而关于SVR的研究在完整性上还不能同支持向量分类相提并论,它还需要更深层次的发掘。
(5) SARIMA 模型
SARIMA (Seasonal Autoregressive Integrated Moving Average)模型通过建立数学模型来近似描述被认为是随时间变化的水质时间序列,利用水质时间序列的实测值来预测将来值。水质的变化经常受到自然灾害、气象气候等不确定因素影响,具有的随机性、不确定性,如果选择传统的物理模型进行水质变化推断,往往达不到相应的效果,而SARIMA模型可以去除序列中的季节性、趋势性等非平稳因素,将非平稳序列转化为平稳序列进行预测分析,SARIMA模型建模简单、适用范围广,可很好的反映水质序列的季节性、趋势性。
(6) LSTM神经网络模型
LSTM (Long-short Term Memory)神经网络模型是解决循环神经网络专门设计解决数据记忆较长问题的一种模型,LSTM神经网络模型增加了细胞状态,根据细胞状态可保留有用信息滤除无用信息。并为了最大限度地减少模型误差,应用倒传递算法,根据训练的误差反传递到隐藏层修改权重大小。LSTM神经网络模型实现了从水质历史数据到预测值的映射功能,基于机器学习强大的学习能力,自主的学习提取水质历史数据、预测值间的对应关系,并将学习的规则有选择性记忆,当进行预测时,利用学习的规则进行预测值的推算。对于水质的预测问题,LSTM神经网络模型适合于较复杂水质问题
复杂、水质数据较多,且模型具有较强的非线性映射能力、自学习和自适应能力、泛化能力和容错能力,对于短期预测精度好。
(7)机理模型
机理模型方法通常使用微分方程描述污染物迁移规律,能够深入到污染物散的内部。从水动力学方程建模到污染物扩散模型的建立,通过一系列数学推导计算最终得到污染物扩散的演化趋势。在数据充分,以及模型参数率定较好的情况下,机理模型的预测效果可满足一般的需要,且能够全面把握污染物迁移过程。机理模型适合于突发性污染事件后的水质预测,且模型能够描述污染物对下游断面水质指标的影响,但模型构建复杂、建模需要数据较多。
各模型的特点

总结
在每周阅读文献的时候都会看到“水质预测引入了两大类预测模型,即基于物理和数据驱动的预测模型”,就看了相关的文献,主要了解了物理模型和数据驱动模型主要有哪些。
https://kreader.cnki.net/Kreader/CatalogViewPage.aspx?dbCode=CMFD&filename=1021892931.nh&tablename=CMFD202301&compose=&first=1&uid=








![[计算机图形学]光线追踪的基本原理(前瞻预习/复习回顾)](https://img-blog.csdnimg.cn/f25d83dfa92a4cacb27ca25bd2654f68.png)