集群拓扑
假设我们使用4单元的标准配置:主库,同步从库,延迟备库,远程备库,分别用字母M,S,O,R标识。
- M:Master, Main, Primary, Leader, 主库,权威数据源。
- S: Slave, Secondary, Standby, Sync Replica,同步副本,需要直接挂载至主库
- R: Remote Replica, Report instance,远程副本,可以挂载到主库或同步从库上
- O: Offline,离线延迟备库,可以挂载到主库,同步从库,或者远程备库上。
依照R和O的挂载目标不同,复制拓扑关系有以下几种选择:
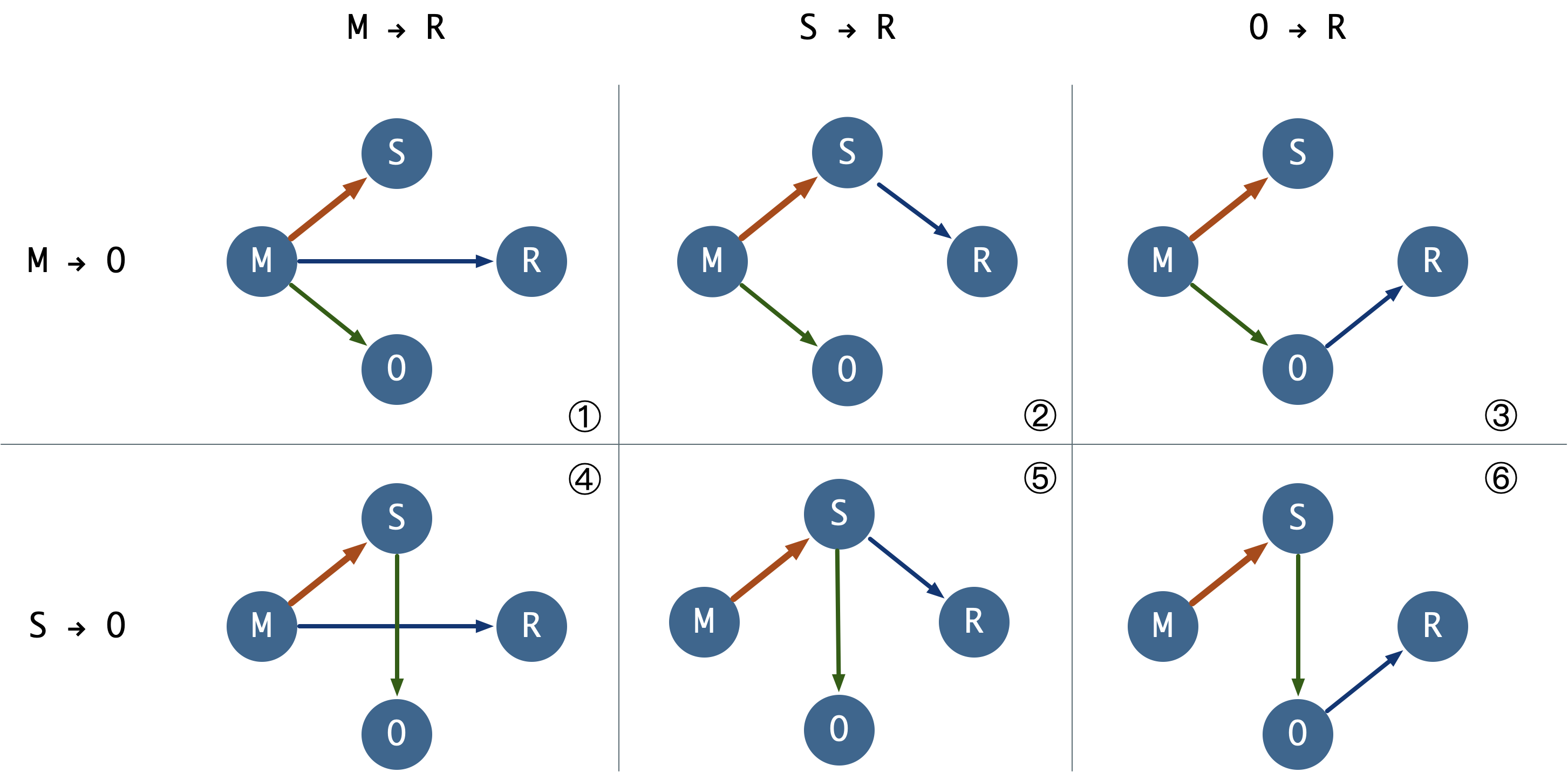
其中,拓扑2具有显著的优越性:
假设采用同步提交,那么为了安全起见,必须有超过一个的同步从库,这样当采用ANY 1或FIRST 1同步提交时,主库不至于因为从库故障而挂掉。因此,离线库O应当直接挂载到主库上:在具体实现细节上:延迟备库可以采用日志传输的方式实现,这样能够将线上库与延迟库解耦。日志归档使用自带的pg_receivewal采用同步的方式(即pg_receivewal作为一个“备库”,而不是离线数据库实例本身)。
另一方面,当使用同步提交时,假设M出现故障,Failover至S,那么S也需要一个同步从库,以免在切换后立刻因为同步提交而Hang住,因此远程备库适合挂载到S上。

故障恢复
当故障发生时,我们需要尽可能快地将生产系统救回来,例如通过Failover,并在事后有时间时恢复原有的拓扑结构。
- P0:(M)主库失效,应当在秒级到分钟级内恢复
- P1:(S)从库失效,影响只读查询,但主库可以先抗,可以容忍分钟级别到小时级别的问题。
- P2:(O,R)离线库与远程备库故障,可能没有直接影响,故障容忍范围可以放宽至小时到天级别。
将S提升为新的M以便尽快使系统恢复。手工Failover包括两个步骤:Fencing M(由重到轻:关机,关数据库,改HBA,关连接池,暂停连接池)与Promote S,这两个操作都可以通过脚本在很短的时间内完成。Failover之后,系统基本恢复。还需要在事后重新恢复原来的拓扑结构。例如将原有的M通过pg_rewind变为新的从库,将O挂载到新的M上,将R挂载到新的S上;或者在修复M后,通过计划内的Failover再次回归原有拓扑。
当S失效时,会对R产生直接影响。作为一种HotFix,我们可以将R的复制源由S改到M,即可将R的影响修复。同时,通过连接池倒流将S的原有流量分发至其他从库或M,接下来就可以慢慢研究并修复S上的问题了。
当O和R失效时,因为它们既没有很大的直接影响,也没有直属后代,因此只要重做一个即可。
实施方式
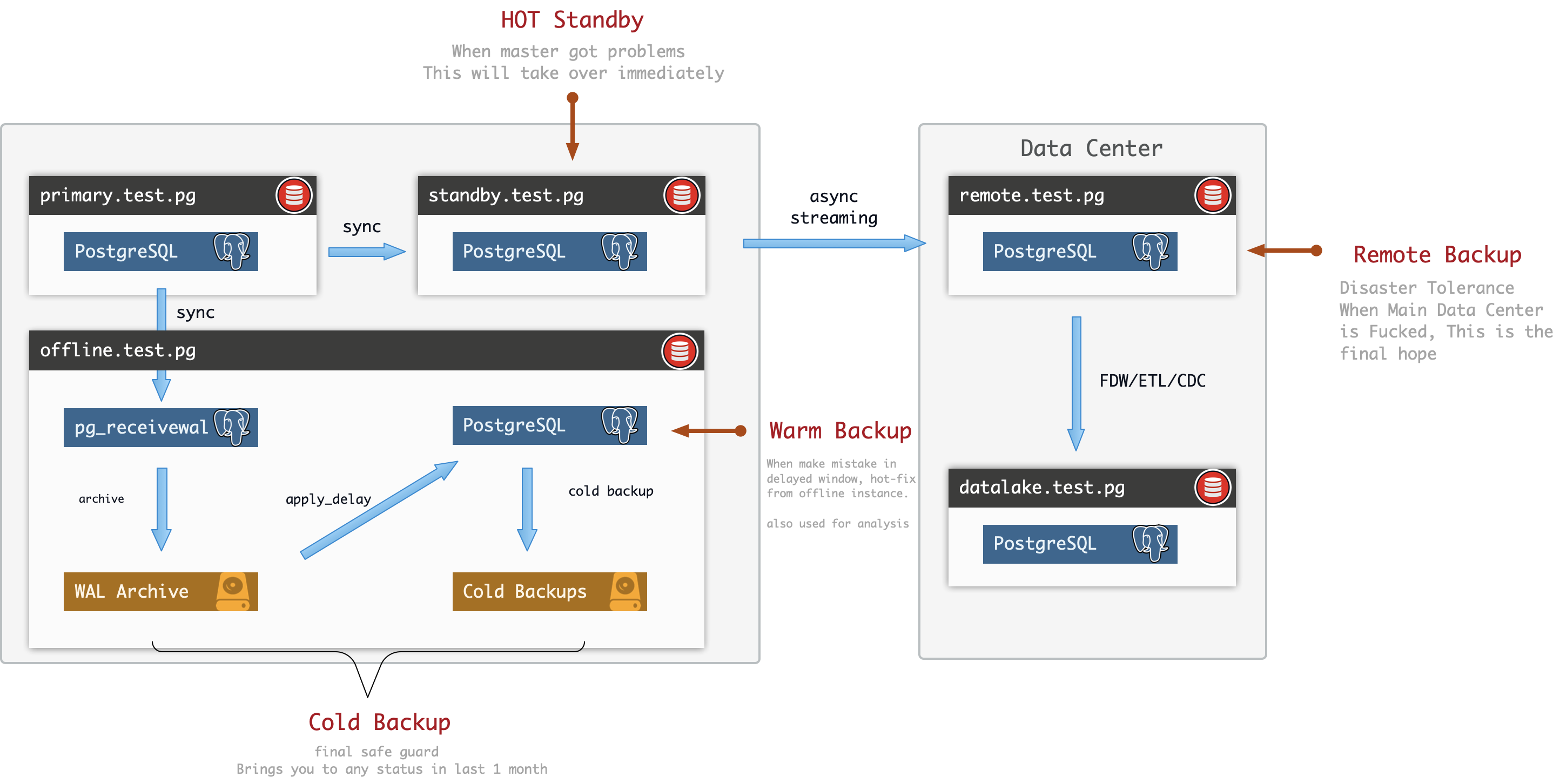
PostgreSQL Testing Environment 这里给出了一个3节点的样例集群,包含了M,S,O三个节点。R节点是S的一种,因此在此略过。
这里,主库直接挂载了两个“从库”,一个是S节点,一个是O节点上的WAL日志归档器。在丢数据容忍度很低的情况下,可以将两者配置为同步从库。