目录
1.名词解释
2. 数据集加载器Dataloader
3.完整代码
推荐课程:08.加载数据集_哔哩哔哩_bilibili
1.名词解释
名词解释:Epoch,Batch,Batch-Size,Iterations
Epoch(周期):指所有的训练样本都进行一次前向和反向传播
Batch-Size(批量大小):batch进行一次前向和反向传播的样本数量
Iterations(迭代):完成一次epoch中batch的次数

2. 数据集加载器Dataloader
DataLoader是pytorch定义的数据集加载器
通过DataLoader设置mini_batch,设置DataLoader相关参数即可
DataLoader参数:
dataset:数据集
num_workers:需要几个并行的进程读取数据
batch_size:一次batch所需的样本数量
shuffle:是否打乱数据集顺序,打乱数据集有利于模型克服“鞍点问题”
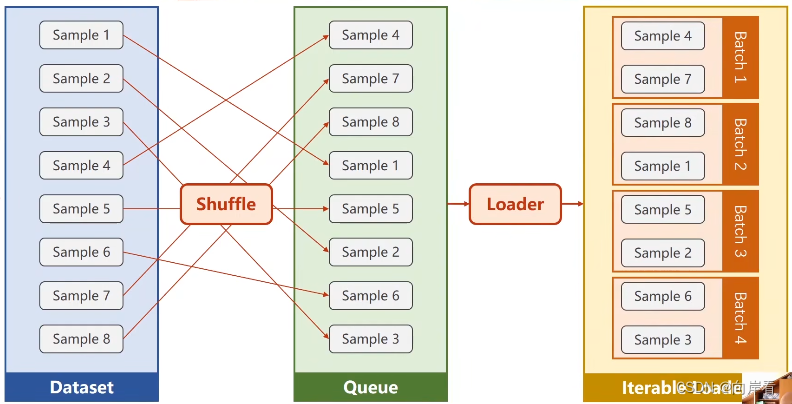
只要数据集能支持索引和提供数据集长度,DataLoader就能对数据集生产batch。
处理数据集两种方法:1.数据集不够大,直接读进内存。2.数据集所占空间比较大,像图片、语音的数据集,将文件名读进内存,根据文件名加载问价。
代码实现(使用数据集加载器Dataloader加载diabetes数据集):
# 自定义数据集类
class DiabetesDataset(Dataset):
def __init__(self, filepath):
# 返回nbarray多维数组
xy = np.loadtxt(filepath, delimiter=',',dtype=np.float32)
# shape函数读取矩阵的长度,比如shape[0]就是读取矩阵第一维度的长度。
self.len = xy.shape[0]
# 数组切片,x[start:stop:step],step为负值表示为逆序。from_numpy函数,numpy转torch
self.x_data = torch.from_numpy(xy[:,:-1])
# [-1] 最后得到的是个矩阵
self.y_data = torch.from_numpy(xy[:, [-1]])
# 通过索引拿数据
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
# 返回数据集长度
def __len__(self):
return self.len
dataset = DiabetesDataset('dataset/diabetes.csv')
# DataLoader是pytorch定义的数据集加载器
# dataset数据集,batch_size小批量所需的数据量,shuffle是否要打乱数据集,num_workers需要几个并行的进程读取数据
# 通过DataLoader设置mini_batch
train_loader = DataLoader(dataset=dataset,
batch_size=32,
shuffle=True,
num_workers=2)3.完整代码
import numpy as np
import torch
# Dataset是一个抽象类,我们必须自定义数据集类并继承这个类
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
#……1.准备数据集……………………………………………………………………………………………………………………………#
# 自定义数据集类
class DiabetesDataset(Dataset):
def __init__(self, filepath):
# 返回nbarray多维数组
xy = np.loadtxt(filepath, delimiter=',',dtype=np.float32)
# shape函数读取矩阵的长度,比如shape[0]就是读取矩阵第一维度的长度。
self.len = xy.shape[0]
# 数组切片,x[start:stop:step],step为负值表示为逆序。from_numpy函数,numpy转torch
self.x_data = torch.from_numpy(xy[:,:-1])
# [-1] 最后得到的是个矩阵
self.y_data = torch.from_numpy(xy[:, [-1]])
# 通过索引拿数据
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
# 返回数据集长度
def __len__(self):
return self.len
dataset = DiabetesDataset('dataset/diabetes.csv')
# DataLoader是pytorch定义的数据集加载器
# dataset数据集,batch_size小批量所需的数据量,shuffle是否要打乱数据集,num_workers需要几个并行的进程读取数据
# 通过DataLoader设置mini_batch
train_loader = DataLoader(dataset=dataset,
batch_size=32,
shuffle=True,
num_workers=2)
#…2.设计模型………………………………………………………………………………………………………………………………………#
# 继承torch.nn.Module,定义自己的计算模块,neural network
class Model(torch.nn.Module):
# 构造函数
def __init__(self):
# 调用父类构造
super(Model, self).__init__()
# 从8维降到6维再降到4维再降到1维
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
# 前馈函数
def forward(self, x):
# 调用self.sigmoid,并linear
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
#……3.构造损失函数和优化器………………………………………………………………………………………………………#
# 实例化自定义模型,返回做logistic变化(也叫sigmoid)的预测值
model = Model()
# 实例化损失函数,返回损失值
criterion = torch.nn.BCELoss(size_average=True)
# 实例化优化器,优化权重w
# model.parameters(),取出模型中的参数,lr为学习率
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
#……训练周期……………………………………………………………………………………………………………………………………………#
if __name__ == '__main__':
for epoch in range(100):
# 迭代train_loader
# 根据自定义数据集类返回的data包含(x_data,y_data),enumerate能够获取是第几次迭代
for i, data in enumerate(train_loader, 0):
# 1.准备数据
inputs, labels = data
# 2.正向传播
y_pred = model(inputs)
loss = criterion(y_pred, labels)
print(epoch, i, loss.item())
# 3.反向传播
optimizer.zero_grad()
loss.backward()
# 4.更新权重w
optimizer.step()练习:构造一个分类模型使用titanic数据集
Titanic - Machine Learning from Disaster | Kaggle






![[译] 实战 React 18 中的 Suspense](https://img-blog.csdnimg.cn/img_convert/59479d008c64482f47556dd3f2924ee9.png)