文章目录
- 一、一趟扫描算法
- 1.1 算法概述
- 1.2 算法逻辑&物理实现
- 1.2.1 逻辑层面
- 1.2.2 物理层面
- 1.2.2.1 P1
- 1.2.2.2 P2
- 1.2.2.3 P3
- 1.2.2.4 P4
- 1.3 迭代器构造查询实现算法
- 1.4 关系操作的一趟扫描算法
- 1.4 基于索引的查询实现算法
- 二、两趟扫描算法
- 2.1 两趟算法基本思想
- 2.2 多路归并排序算法
- 2.3 排序的两趟扫描算法
- 2.4 散列的两趟扫描算法
一、一趟扫描算法
1.1 算法概述
优化一些操作:把过滤操作推导关联前执行
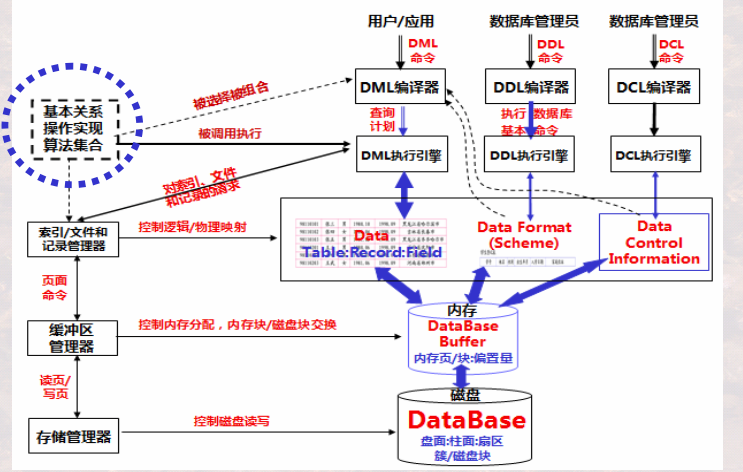
1.2 算法逻辑&物理实现
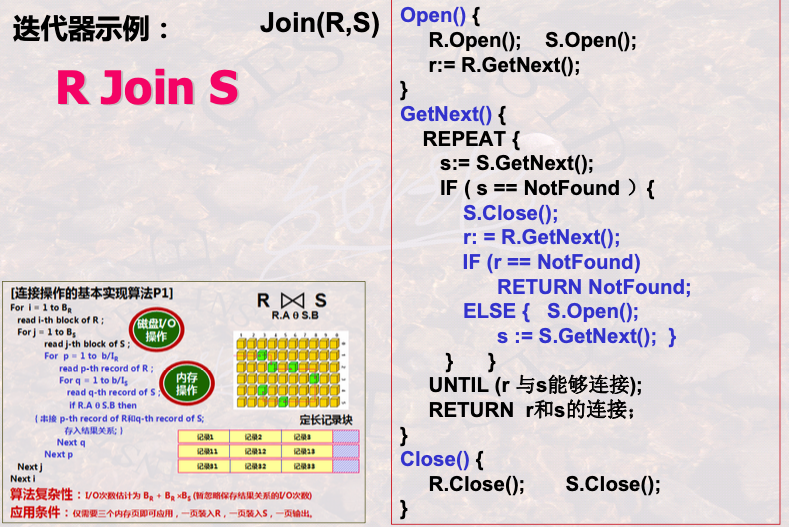
连接操作的实现算法
1.2.1 逻辑层面
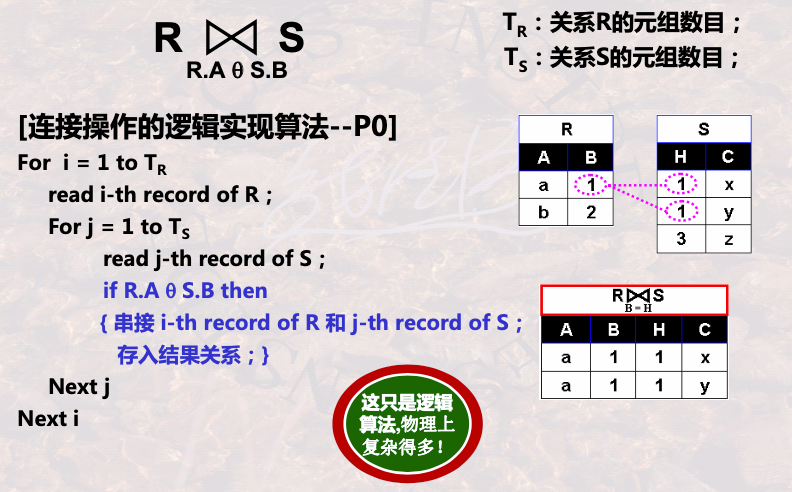
物理层面要比逻辑层面复杂的多
1.2.2 物理层面
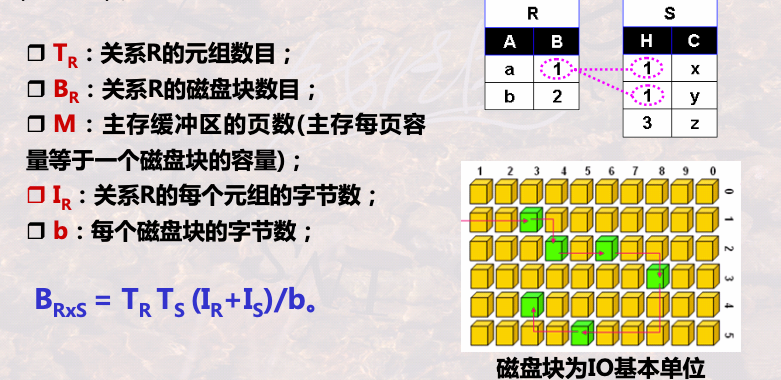
关系是存储在磁盘上的,首先要进行磁盘IO装载进内存
1.2.2.1 P1
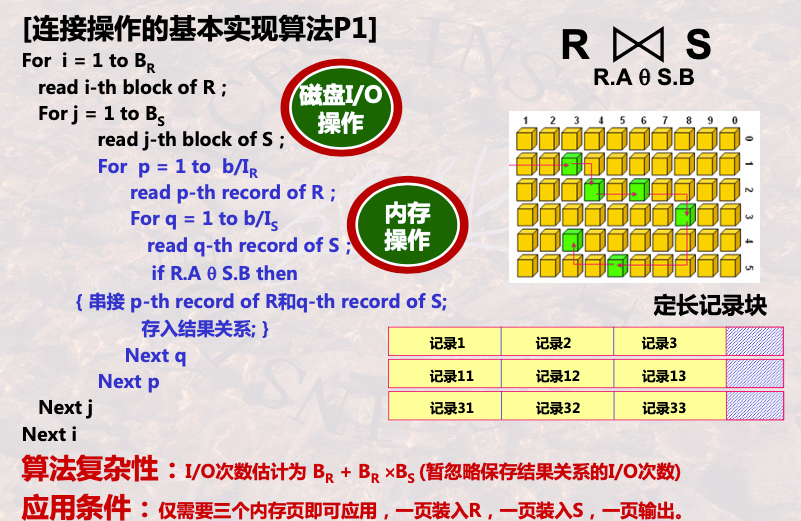
- 先读R表的磁盘块循环i
- 循环j 读取S的磁盘块
- R的第一块,和j的每一块对比
1.2.2.2 P2

内存中存的下R + S的全部磁盘块
1.都加载到内存中R S
2.R S循环对比
1.2.2.3 P3
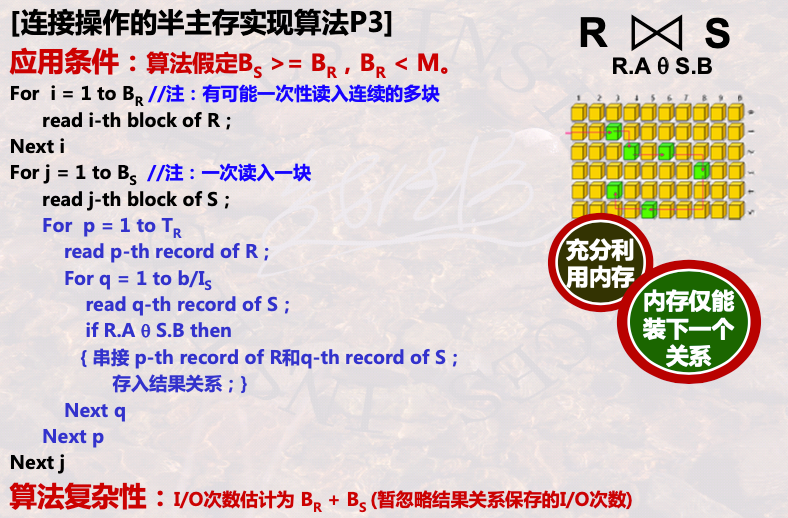
内存中存的下R 的全部磁盘块
S一次一块
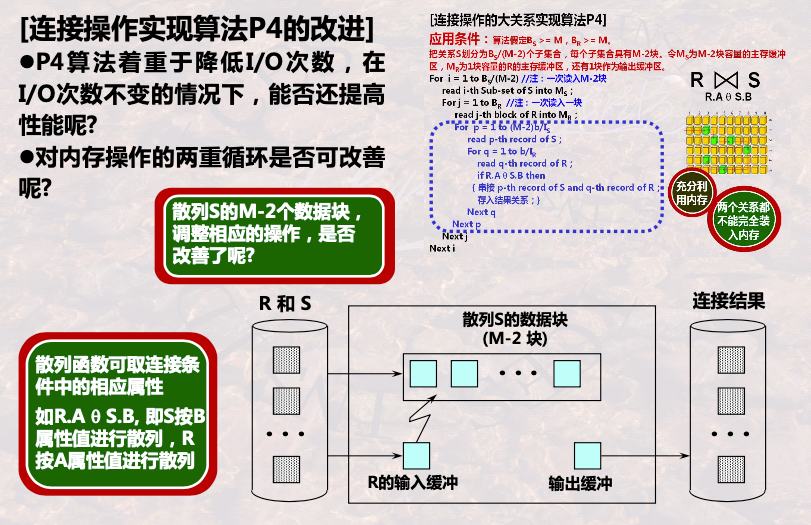
1.2.2.4 P4
S >= M,R >= M
如何充分利用内存?
- 每次读取子集合有S的M-2块数据
- 读取1块R
- 生成1块临时RxS的数据


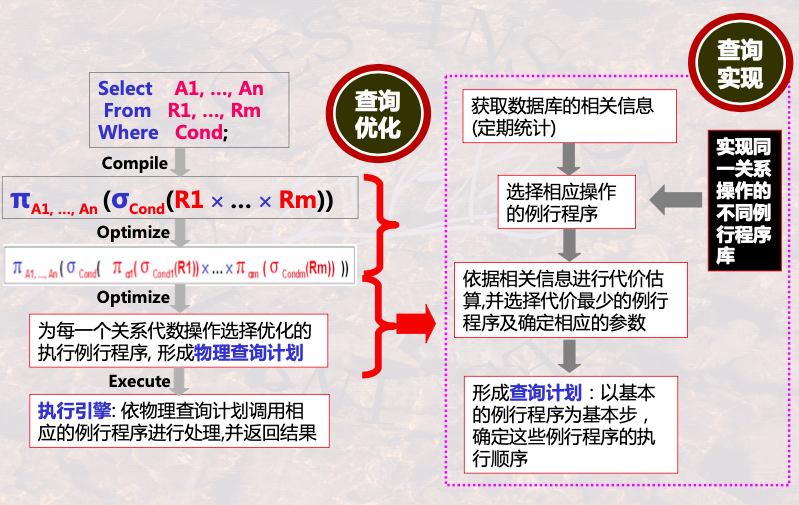
1.3 迭代器构造查询实现算法
扫描一次数据,全部的关系操作都执行完
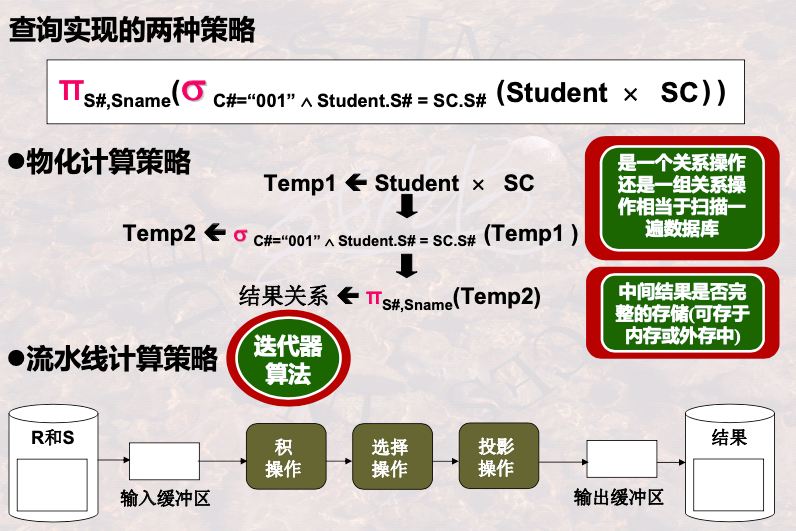

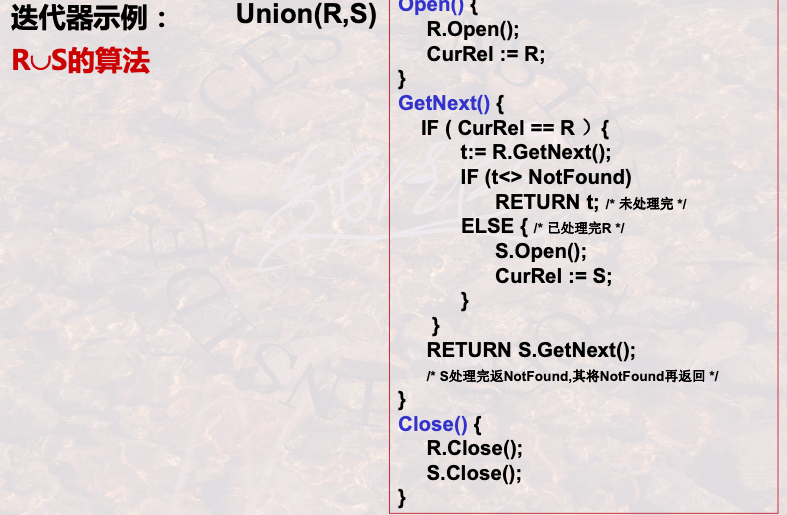
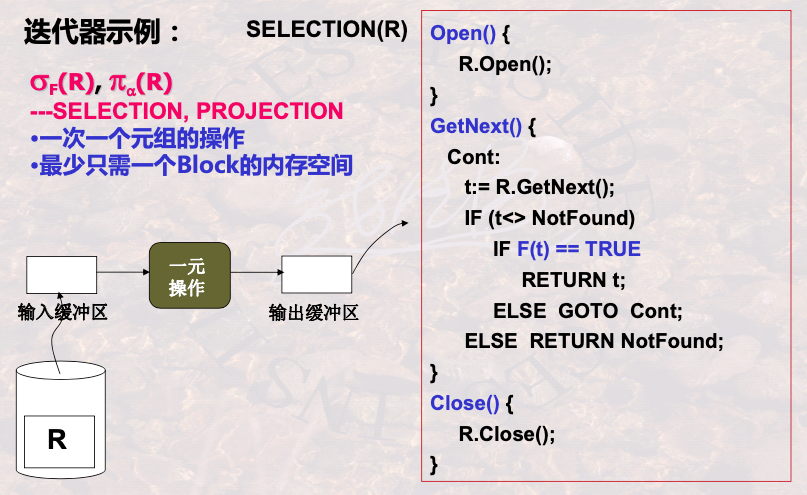
多个操作合并
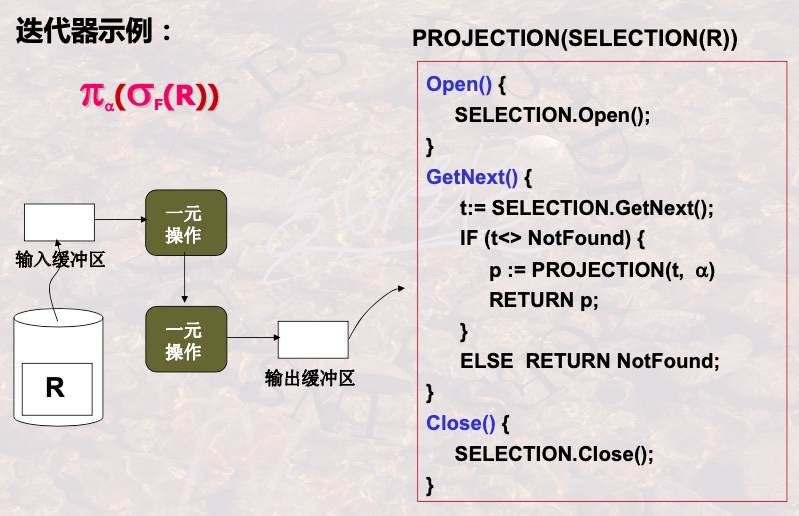
1.4 关系操作的一趟扫描算法
内存中把全部数据都能装进来
聚簇关系 : 关系中的元祖集中存放(一个块是一个关系中的元祖)
- TableScan® --表空间扫描算法,扫描结果未排序B®
- SortTableScan® --扫描结果排序
- IndexScan® --索引扫描算法
- SortIndexScan® --扫描结果排序
非聚簇关系:关系中的元祖不一定集中存放(一个块中不一定是一个元祖的)
- 扫描结果不排序
- 排序
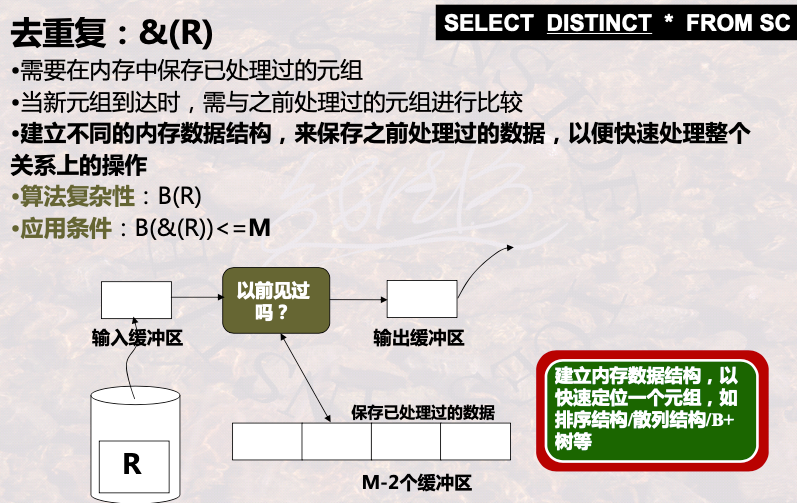
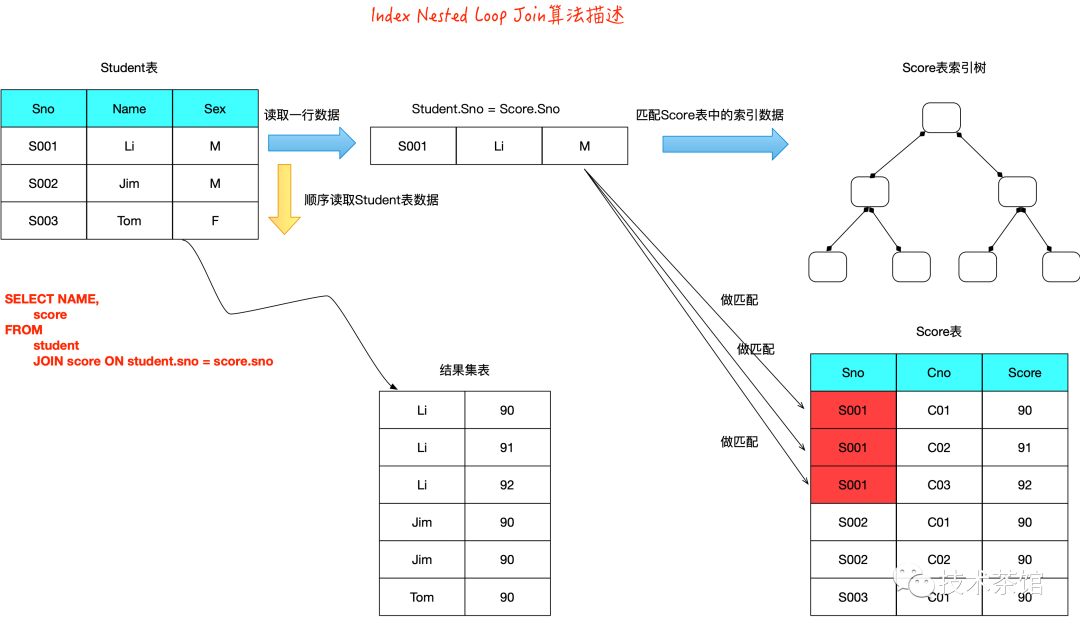
1.4 基于索引的查询实现算法
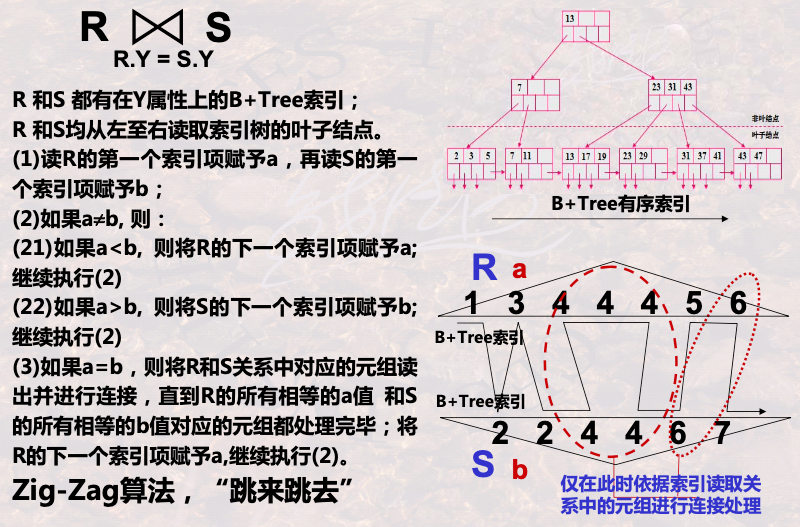
DBMS会根据以下因素来选择使用哪种join物理实现方式:
1. 表大小:如果一个表很小,那么使用嵌套循环(nested loop)join可能比使用其他join方式更快。如果一个表很大,那么使用hash join或sort-merge join等方式更有效率。
2. JOIN条件:如果JOIN条件中包含的参与连接的键是唯一的,那么使用物理实现方式可能是嵌套循环join。如果参与连接的键不是唯一的,那么使用sort-merge join或hash join等方式更合适。
3. 查询复杂度:如果查询复杂度高,那么执行cost-based的优化可能是更合理的方式。例如,优化器可以评估所有可能的join方式,然后选择成本最小的方式。
4. 可用资源:有时候DBMS在可用资源比较有限的情况下(例如内存),无法使用某些join方式。在这种情况下,DBMS必须根据可用资源的限制选择适当的join方式。
5. 磁盘I/O:某些join方式可能会涉及大量的磁盘读写,而其他方式则可能会更少。在考虑使用哪种join方式时,必须考虑磁盘I/O的使用情况。
综上所述,DBMS会根据表大小、JOIN条件、查询复杂度、可用资源和磁盘I/O等因素来选择使用哪种join物理实现方式,以达到最优的性能。
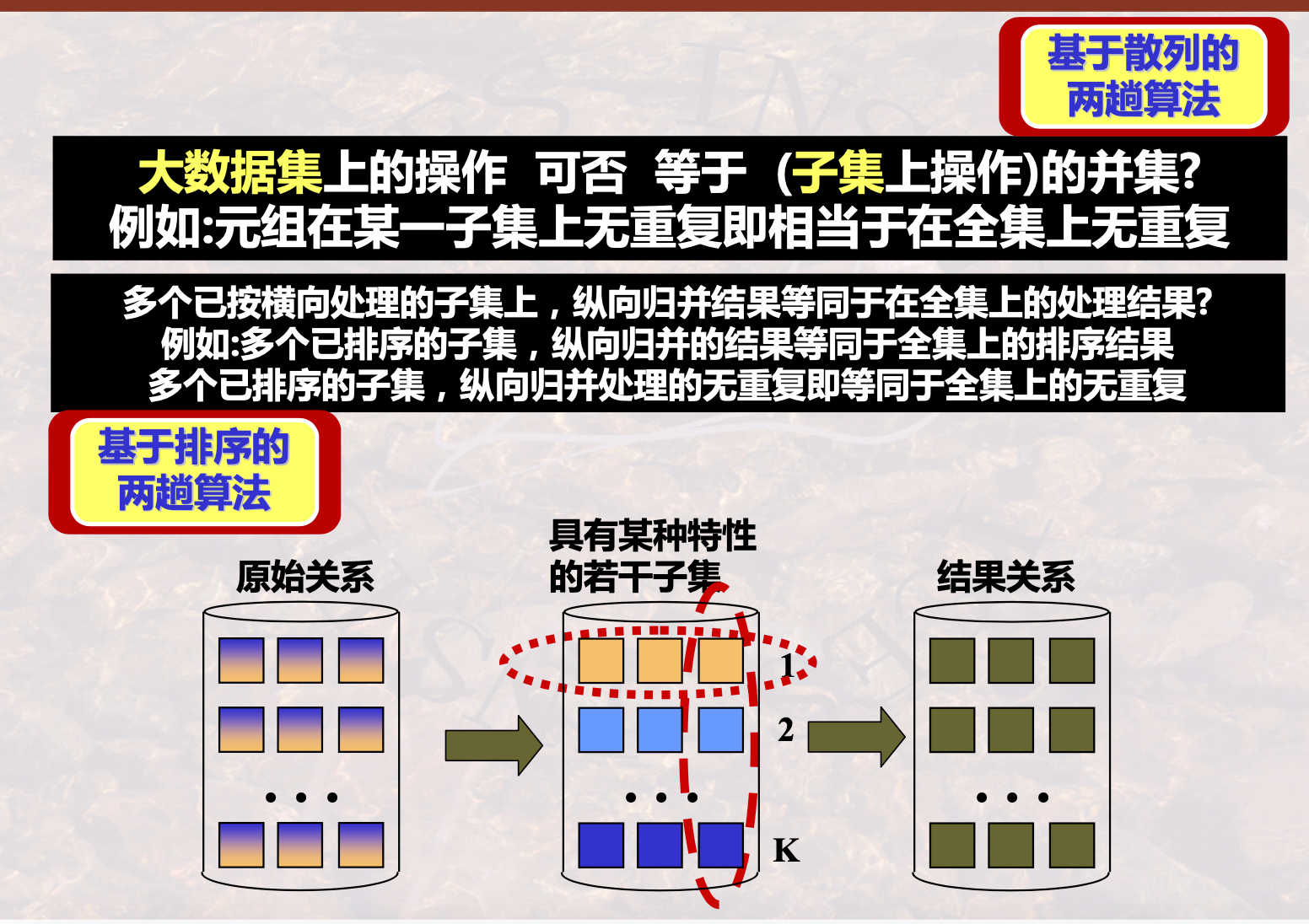
二、两趟扫描算法
一趟算法需要很多内存,为了减少磁盘I/O的次数,提高查询效率。具体原因如下
第一次扫描:在第一次扫描过程中,我们可以筛选出符合条件的部分数据,将它们尽可能地存储在内存中,避免了大量的磁盘I/O操作。这些数据通常被存储在一个中间结果表中。
第二次扫描:在第二次扫描过程中,我们只需要针对中间结果表中的数据进行进一步的处理和筛选,而无需再次访问磁盘中的原始数据表。这就大大减少了磁盘I/O操作的次数,提高了查询效率。
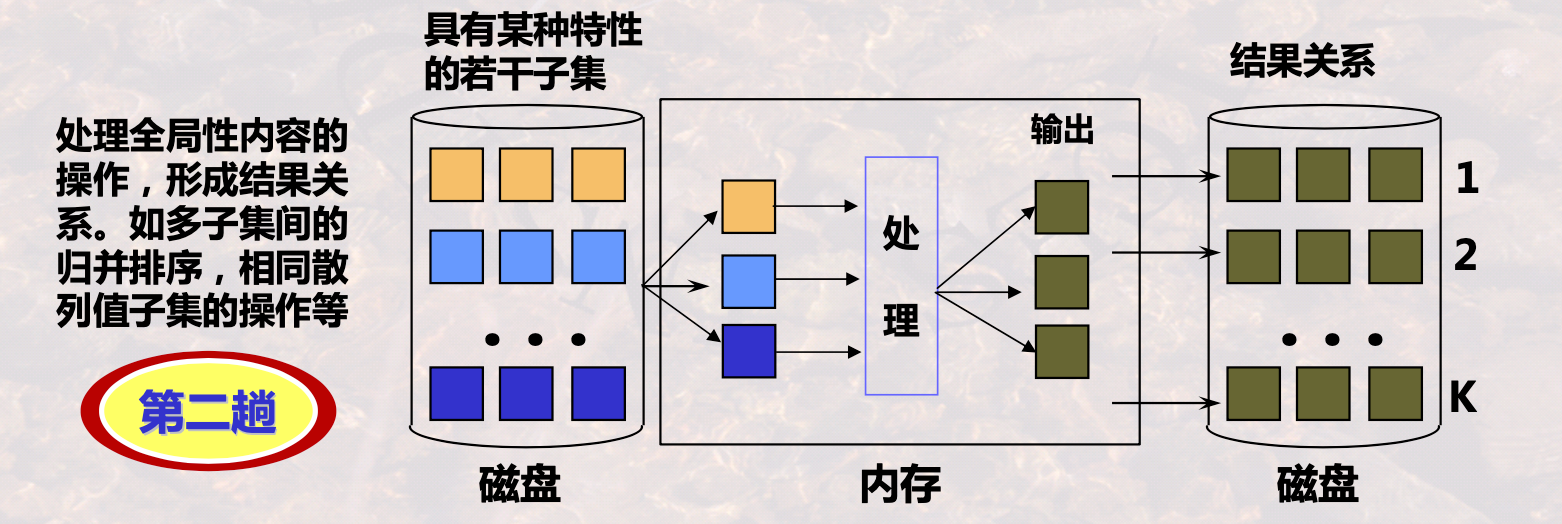
2.1 两趟算法基本思想
对磁盘中的数据划分子集
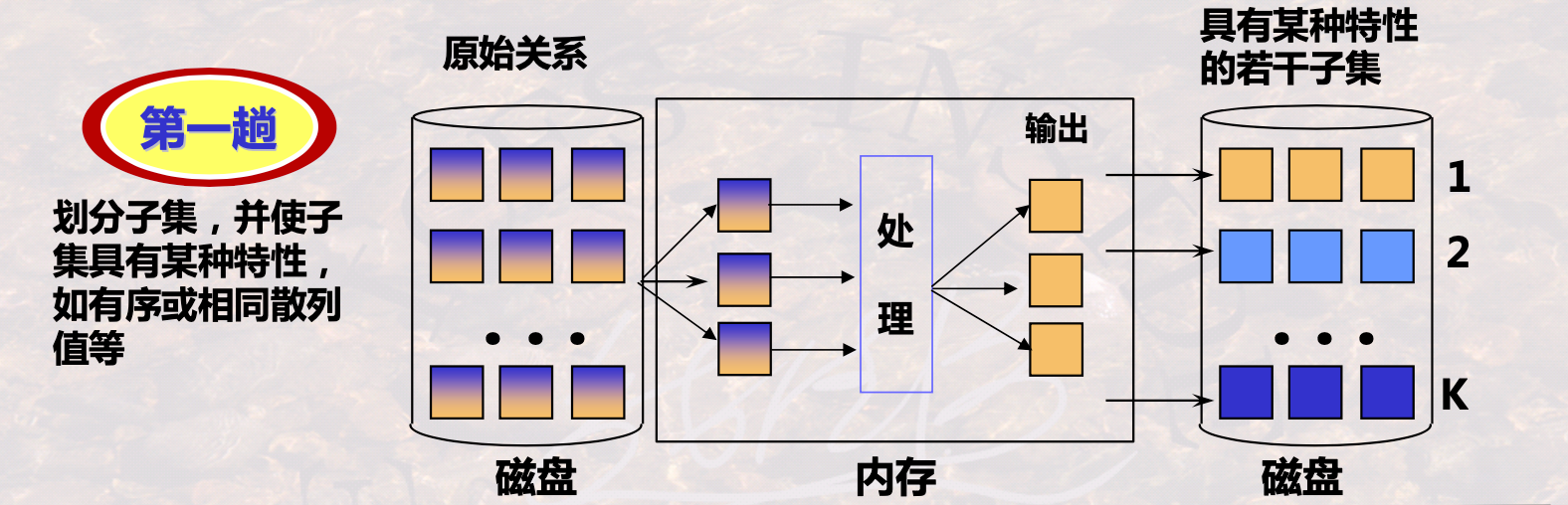
在磁盘划分的子集中,再次处理







![Oracle:ORA-00600[4137]问题分析](https://img-blog.csdnimg.cn/img_convert/9e319bc2566bca134eac67b32ed5bb5b.png)