线程创建和接收
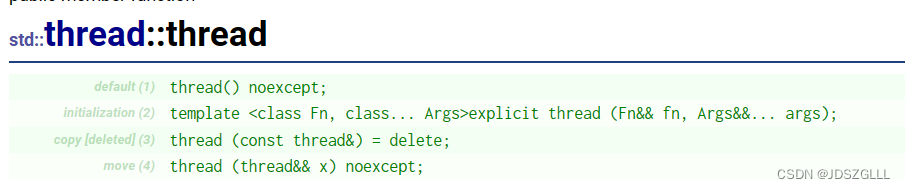

std::this_thread::get_id()获取当前线程的线程ID
std::this_thread::yield()让步结束当前线程的时间片
int main()
{
vector<thread> threads(2);
threads[0] = thread([]() {cout << this_thread::get_id() << endl;});
threads[1] = thread([]() {cout << this_thread::get_id() << endl;});
thread thread3([]() {cout << this_thread::get_id() << endl;});
for (auto& e : threads)
{
e.join();
}
thread3.join();
return 0;
}
//14136
//15844
//16272原子操作
多线程最主要的问题是共享数据带来的问题(即线程安全)。如果共享数据都是只读的,那么没问 题,因为只读操作不会影响到数据,更不会涉及对数据的修改,所以所有线程都会获得同样的数 据。但是,当一个或多个线程要修改共享数据时,就会产生很多潜在的麻烦。比如:
int main()
{
int val = 0;
vector<thread> threads(2);
threads[0] = thread([&](int n) {
for (int i = 0; i < n; ++i)
{
++val;
}}, 100000);
threads[1] = thread([&](int n) {
for (int i = 0; i < n; ++i)
{
++val;
}}, 200000);
for (auto& e : threads)
{
e.join();
}
cout << val << endl;
return 0;
}这个程序跑出来的结果不确定,有时候会比较小,这都是由于多线程导致的数据不一致。
虽然加锁可以解决,但是加锁有一个缺陷就是:只要一个线程在对sum++时,其他线程就会被阻 塞,会影响程序运行的效率,而且锁如果控制不好,还容易造成死锁。
因此C++11中引入了原子操作。所谓原子操作:即不可被中断的一个或一系列操作,C++11引入 的原子操作类型,使得线程间数据的同步变得非常高效。
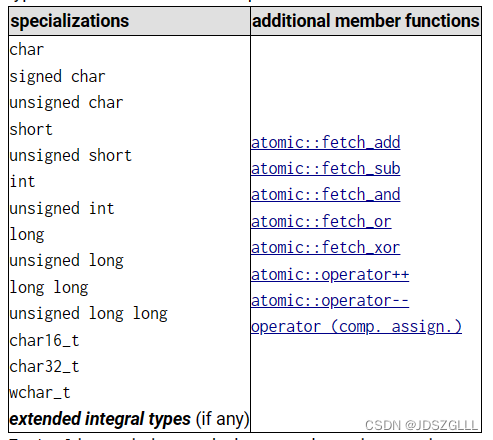
原子类模板完全专门用于所有基本整数类型(bool 除外),以及 <cstdint> 中的 typedef 所需的任何扩展整数类型。 这些特化具有以下附加成员函数:
在C++11中,程序员不需要对原子类型变量进行加锁解锁操作,线程能够对原子类型变量互斥的 访问。 更为普遍的,程序员可以使用atomic类模板,定义出需要的任意原子类型。
同时atomic_int与aotmic<int>完全一样。
int main()
{
atomic_int val = 0;
vector<thread> threads(2);
threads[0] = thread([&](int n) {
for (int i = 0; i < n; ++i)
{
++val;
}}, 100000);
threads[1] = thread([&](int n) {
for (int i = 0; i < n; ++i)
{
++val;
}}, 200000);
for (auto& e : threads)
{
e.join();
}
cout << val << endl;
return 0;
}这个程序就完全保证了++的原子性。
在C++11 中,原子类型只能从其模板参数中进行构造,不允许原子类型进行拷贝构造、移动构造以及 operator=等,为了防止意外,标准库已经将atmoic模板类中的拷贝构造、移动构造、赋值运算 符重载默认删除掉了。
原子操作的本质是CAS(compare and swap): 寄存器中的值写回内存时,将当初提取的旧值与现在内存中的值比较,如果一样就写回去,如果不一样再次从内存中提取,重复操作。
mutex的种类
在C++11中,Mutex总共包了四个互斥量的种类:
std::mutex
C++11提供的最基本的互斥量,该类的对象之间不能拷贝,也不能进行移动。
| 函数名 | 函数功能 |
| lock() | 上锁:锁住互斥量 |
| unlock() | 解锁:释放对互斥量的所有权 |
| try_lock() | 尝试锁住互斥量,如果互斥量被其他线程占有,则当前线程也不会被阻 塞 |
std::recursive_mutex
递归互斥锁:其允许同一个线程对互斥量多次上锁(即递归上锁),来获得对互斥量对象的多层所有权, 释放互斥量时需要调用与该锁层次深度相同次数的 unlock(),除此之外, std::recursive_mutex 的特性和 std::mutex 大致相同。
判断获取锁的线程与当前要加锁的线程是不是同一个,如果是就不阻塞。
std::timed_mutex
比 std::mutex 多了两个成员函数,try_lock_for(),try_lock_until() 。
try_lock_for()
接受一个时间范围,表示在这一段时间范围之内线程如果没有获得锁则被阻塞住(与 std::mutex 的 try_lock() 不同,try_lock 如果被调用时没有获得锁则直接返回 false),如果在此期间其他线程释放了锁,则该线程可以获得对互斥量的锁,如果超 时(即在指定时间内还是没有获得锁),则返回 false。
try_lock_until()
接受一个时间点作为参数,在指定时间点未到来之前线程如果没有获得锁则被阻塞住, 如果在此期间其他线程释放了锁,则该线程可以获得对互斥量的锁,如果超时(即在指 定时间内还是没有获得锁),则返回 false。
std::recursive_timed_mutex不作讲解
guard_lock的改进版本unique_lock
与lock_gard类似,unique_lock类模板也是采用RAII的方式对锁进行了封装,并且也是以独占所 有权的方式管理mutex对象的上锁和解锁操作,即其对象之间不能发生拷贝。在构造(或移动 (move)赋值)时,unique_lock 对象需要传递一个 Mutex 对象作为它的参数,新创建的 unique_lock 对象负责传入的 Mutex 对象的上锁和解锁操作。使用以上类型互斥量实例化 unique_lock的对象时,自动调用构造函数上锁,unique_lock对象销毁时自动调用析构函数解 锁,可以很方便的防止死锁问题。
条件变量condition_variable
条件变量本身不是线程安全的,需要和锁(只能是unique_lock,可以在条件等待时解锁)配合。
支持两个线程交替打印,一个打印奇数,一个打印偶
反复询问,消耗CPU资源
int main()
{
int val = 0;
int n = 100;
vector<thread> threads(2);
threads[0] = thread([&]() {
while (val <= 100)
{
if (0 == val % 2)
{
cout << this_thread::get_id() << "->" << val << endl;
++val;
}
}
});
threads[1] = thread([&]() {
while (val < 100)
{
if (val % 2)
{
cout << this_thread::get_id() << "->" << val << endl;
++val;
}
}});
for (auto& e : threads)
{
e.join();
}
//cout << val << endl;
return 0;
}条件变量等待唤醒
int main()
{
int val = 0;
int n = 10000;
condition_variable cond;
mutex mt;
vector<thread> threads(2);
threads[0] = thread([&]() {
while (val <= n)
{
{
unique_lock<mutex> ulk(mt);
cond.wait(ulk, [&]() {return 0 == val % 2;});
cout << this_thread::get_id() << "->" << val << endl;
++val;
cond.notify_one();
}
}
});
threads[1] = thread([&]() {
while (val < n)
{
{
unique_lock<mutex> ulk(mt);
cond.wait(ulk, [&]() {return val % 2;});
cout << this_thread::get_id() << "->" << val << endl;
++val;
cond.notify_one();
}
}});
for (auto& e : threads)
{
e.join();
}
//cout << val << endl;
return 0;
}注意,下面两种使用完全一样:
while (i % 2)
cv.wait(lock);
cv.wait(lock, [&i] {return i % 2 == 0; });