文章目录
- 背景
- 问题发现
- 排查CSI provision
- 排查kube-controller-manager
- 查看controller log
- 紧急恢复
- 求助chatgpt
背景
2023年4月21日10:38:07,在集群中测试RBAC的时候,在kuboard的界面神出鬼没的删除了几个clusterRole。练习一个CKA的练习题目.
Create a new ServiceAccount processor in Namespace project-hamster Create a Role and RoleBinding, both named processor as well. These should allow the new SAto only create Secrets and ConfigMapsin that Namespace
因为我发现每个ns下都有default sa 。 用auth can-i 测试一直没测通
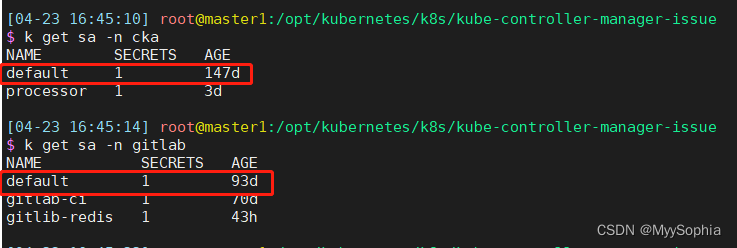
想着要怎么把这个default sa给删除了神不知鬼不觉的就操作了这个界面,删除了几个clusterRolebinding 和clusterrole。

据我记忆就是这个界面.
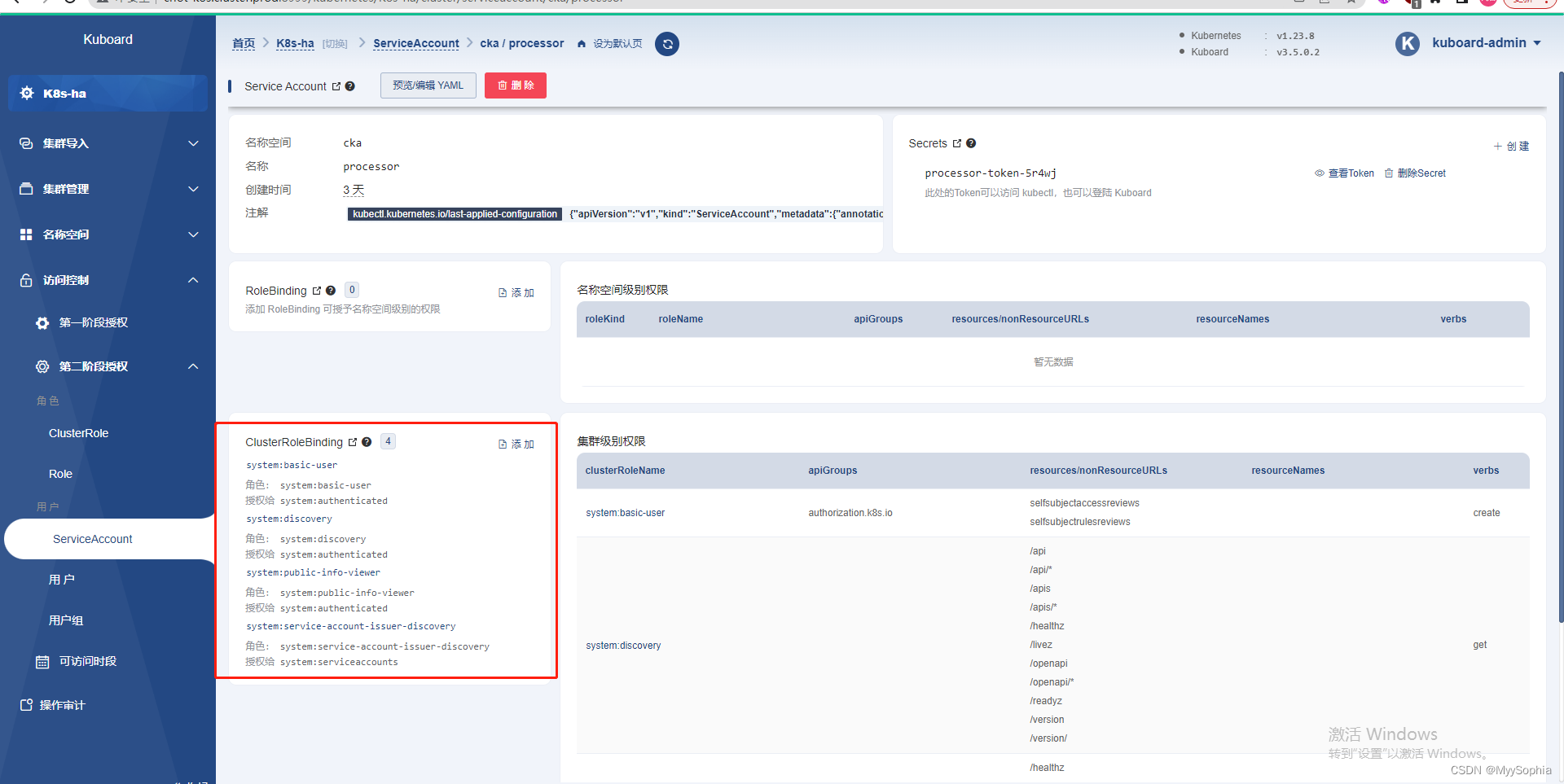
问题发现
当时这么操作之后并没有及时发现问题 (这里是不是应该有告警?pod 大面积不ready,当时看到的情况是grafana、minio、prometheus、gitlab … 均不能访问,都报503错误码)。
2023年4月21日17:38:07 :创建一个有CSI的pod时,pod一直不ready,一路排查下来发现是pvc一直绑不上pv。

注 : 当时测试不涉及CSI 的pod是可以创建成功的。
排查CSI provision
2023年4月21日22:03:21
使用的是nfs作为持久化存储,nfs-provisioner动态供应。
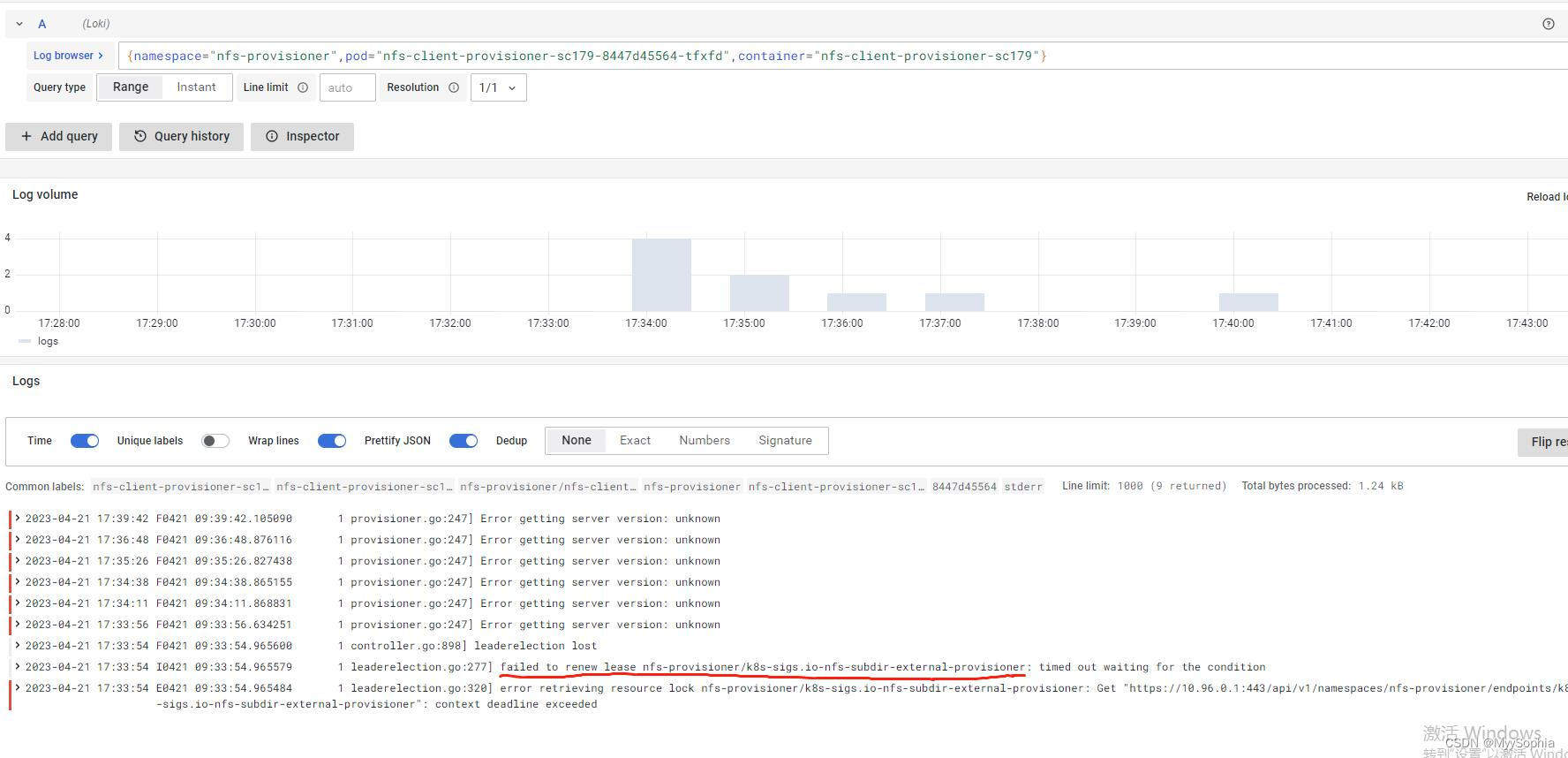
查看 nfs-client-provisioner的日志发现有报错。
lease renew failed, 首先就想到kube-controller-manager和kube-scheduler有问题。
kube-scheduler是负责调度的应该不是问题所在,应该是kube-controller-manager的问题,因为nfs-provisioner本质也是一个controller。controller manager是所有controller的管理者是k8的大脑。
排查kube-controller-manager
这块的排查耗时最久,究其原因是对k8s组件的认证鉴权机制不够了解。
2023年4月23日08:40:29
kube-controller-manager 是高可用部署,共三个节点。
当时发现kube-controller-manager 不停的进行election,不停的重启。
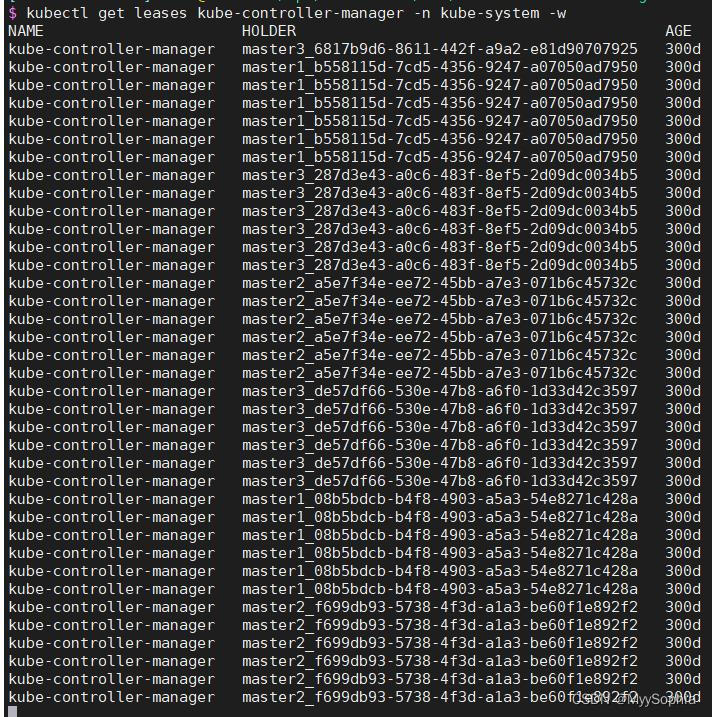
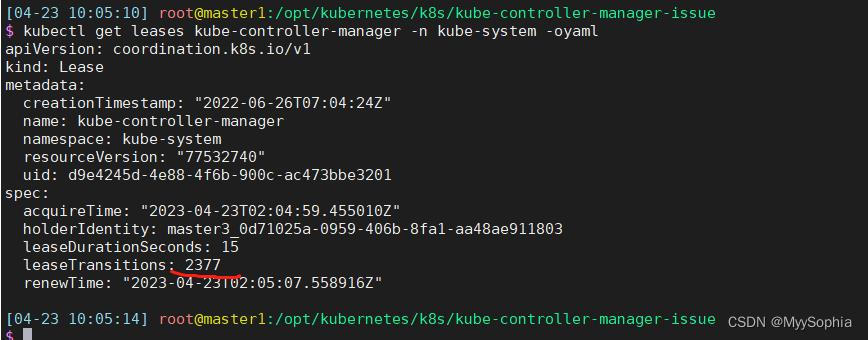
controller election状态
schedule election状态
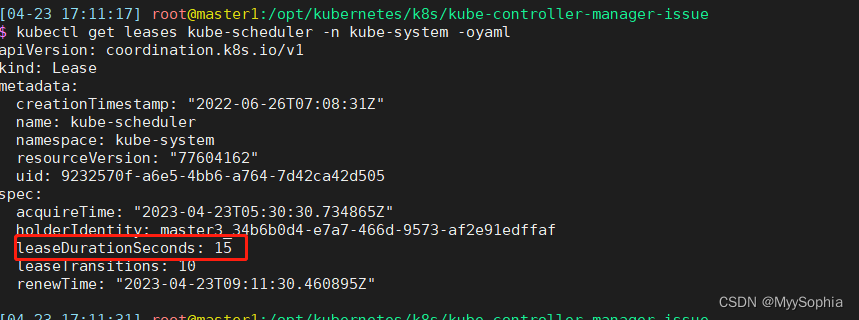
很明显controller的election一直在election 疯狂更新renewtime,这里也能解释nfs-provisioner为何会timeout。因为master一直变来变去。而且每次竞选成功都会有不同的uid。
查看controller log
E0423 11:37:21.236103 11401 configmap_cafile_content.go:242] key failed with : missing content for CA bundle "client-ca::kube-system::extension-apiserver-authentication::requestheader-client-ca-file"
F0423 11:37:27.860197 11401 controllermanager.go:233] error building controller context: failed to wait for apiserver being healthy: timed out waiting for the condition: failed to get apiserver /healthz status: forbidden: User "system:kube-controller-manager" cannot get path "/healthz"
goroutine 295 [running]:
k8s.io/kubernetes/vendor/k8s.io/klog/v2.stacks(0x1)
/workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/k8s.io/klog/v2/klog.go:1038 +0x8a
k8s.io/kubernetes/vendor/k8s.io/klog/v2.(*loggingT).output(0x779aa60, 0x3, 0x0, 0xc0007220e0, 0x0, {0x5f1425a, 0x1}, 0xc000e7c9a0, 0x0)
/workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/k8s.io/klog/v2/klog.go:987 +0x5fd
k8s.io/kubernetes/vendor/k8s.io/klog/v2.(*loggingT).printf(0x0, 0x0, 0x0, {0x0, 0x0}, {0x477c449, 0x25}, {0xc000e7c9a0, 0x1, 0x1})
/workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/k8s.io/klog/v2/klog.go:753 +0x1c5
k8s.io/kubernetes/vendor/k8s.io/klog/v2.Fatalf(...)
/workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/k8s.io/klog/v2/klog.go:1532
k8s.io/kubernetes/cmd/kube-controller-manager/app.Run.func1({0x4e4a690, 0xc00033f080}, 0xc000922b40, 0x48b9d38)
/workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/cmd/kube-controller-manager/app/controllermanager.go:233 +0x1bb
k8s.io/kubernetes/cmd/kube-controller-manager/app.Run.func3({0x4e4a690, 0xc00033f080})
/workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/cmd/kube-controller-manager/app/controllermanager.go:295 +0xe3
created by k8s.io/kubernetes/vendor/k8s.io/client-go/tools/leaderelection.(*LeaderElector).Run
/workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/k8s.io/client-go/tools/leaderelection/leaderelection.go:211 +0x154
goroutine 1 [select (no cases)]:
k8s.io/kubernetes/cmd/kube-controller-manager/app.Run(0xc000435408, 0xc0000a0360)
/workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/cmd/kube-controller-manager/app/controllermanager.go:326 +0x7d7
k8s.io/kubernetes/cmd/kube-controller-manager/app.NewControllerManagerCommand.func2(0xc0008d2500, {0xc000585e40, 0x0, 0x16})
/workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/cmd/kube-controller-manager/app/controllermanager.go:153 +0x2d1
k8s.io/kubernetes/vendor/github.com/spf13/cobra.(*Command).execute(0xc0008d2500, {0xc00004c190, 0x16, 0x17})
/workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/github.com/spf13/cobra/command.go:860 +0x5f8
k8s.io/kubernetes/vendor/github.com/spf13/cobra.(*Command).ExecuteC(0xc0008d2500)
/workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/github.com/spf13/cobra/command.go:974 +0x3bc
k8s.io/kubernetes/vendor/github.com/spf13/cobra.(*Command).Execute(...)
/workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/github.com/spf13/cobra/command.go:902
k8s.io/kubernetes/vendor/k8s.io/component-base/cli.run(0xc0008d2500)
/workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/k8s.io/component-base/cli/run.go:146 +0x325
k8s.io/kubernetes/vendor/k8s.io/component-base/cli.Run(0xc0000001a0)
/workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/k8s.io/component-base/cli/run.go:46 +0x1d
main.main()
_output/dockerized/go/src/k8s.io/kubernetes/cmd/kube-controller-manager/controller-manager.go:35 +0x1e
goroutine 6 [chan receive]:
.....
启动之后第一时间有一个Fatal的日志
error building controller context: failed to wait for apiserver being healthy: timed out waiting for the condition: failed to get apiserver /healthz status: forbidden: User "system:kube-controller-manager" cannot get path "/healthz"

报错说的也比较明显 : controller 无法获取apiserver的健康状况,原因是没权限访问/healthz
紧急恢复
在另外一个集群把clusterrole 和clusterrolebinding -oyaml找出来重建。
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
labels:
kubernetes.io/bootstrapping: rbac-defaults
name: system:kube-controller-manager
rules:
- apiGroups:
- ""
- events.k8s.io
resources:
- events
verbs:
- create
- patch
- update
- apiGroups:
- coordination.k8s.io
resources:
- leases
verbs:
- create
- apiGroups:
- coordination.k8s.io
resourceNames:
- kube-controller-manager
resources:
- leases
verbs:
- get
- update
- apiGroups:
- ""
resources:
- endpoints
verbs:
- create
- apiGroups:
- ""
resourceNames:
- kube-controller-manager
resources:
- endpoints
verbs:
- get
- update
- apiGroups:
- ""
resources:
- secrets
- serviceaccounts
verbs:
- create
- apiGroups:
- ""
resources:
- secrets
verbs:
- delete
- apiGroups:
- ""
resources:
- configmaps
- namespaces
- secrets
- serviceaccounts
verbs:
- get
- apiGroups:
- ""
resources:
- secrets
- serviceaccounts
verbs:
- update
- apiGroups:
- authentication.k8s.io
resources:
- tokenreviews
verbs:
- create
- apiGroups:
- authorization.k8s.io
resources:
- subjectaccessreviews
verbs:
- create
- apiGroups:
- '*'
resources:
- '*'
verbs:
- list
- watch
- apiGroups:
- ""
resources:
- serviceaccounts/token
verbs:
- create
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
labels:
kubernetes.io/bootstrapping: rbac-defaults
name: system:kube-controller-manager
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:kube-controller-manager
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: User
name: system:kube-controller-manager
重建之后,不再报错/healthz没权限访问的报错。
此时集群还没恢复,controller-manaer还有一个报错:
E0423 13:34:43.469843 10440 configmap_cafile_content.go:242] kube-system/extension-apiserver-authentication failed with : missing content for CA bundle "client-ca::kube-system::thentication::requestheader-client-ca-file"
E0423 13:34:43.470622 10440 configmap_cafile_content.go:242] key failed with : missing content for CA bundle "client-ca::kube-system::extension-apiserver-authentication::request
I0423 13:34:43.469918 10440 tlsconfig.go:178] "Loaded client CA" index=0 certName="client-ca::kube-system::extension-apiserver-authentication::client-ca-file,client-ca::kube-syser-authentication::requestheader-client-ca-file" certDetail="\"kubernetes\" [] groups=[k8s] issuer=\"<self>\" (2022-06-25 15:32:00 +0000 UTC to 2027-06-24 15:32:00 +0000 UTC (now=9890751 +0000 UTC))"
求助chatgpt
这种报错在goole上竟然只能搜到1页的内容。在github issue list也没翻出来。只能求助chatgpt了。
根据chatgpt的提示重建了 extension-apiserver-authentication 这个cm。
然并卵 …
然后又神不知鬼不觉的重启了一下kube-apiserver。竟然恢复了,原因不知道也可以问chatgpt.