独立表空间结构
- InnoDB有很多类型表空间,这边主要是介绍独立表空间结构,因为这种会用的比较多
- 讲之前我们先思考一个问题,如果我们以页为单位来分配存储空间的话,那两个页之间的物理距离可能很远,因为这是随机的,而这些数据存储到磁盘上的,从磁盘加载是很消耗性能,而这些加载分为顺序IO和随机IO,顺序IO肯定是更快的,所以我们需要保证数据页尽量在一起,怎么做才能尽量保证数据页尽量在一起呢?
- 这个时候就需要推出区 和 段的概念
- 我们先从宏观的角度初略的介绍 区 和 段
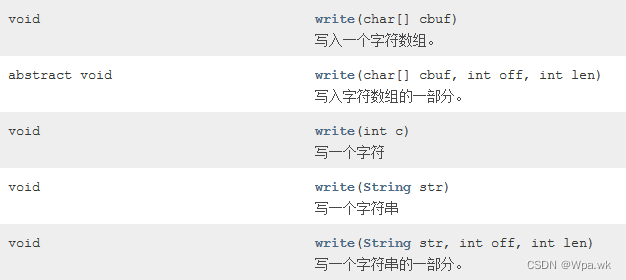
- 区是由64个页组成的,也就是说默认一个区占用1MB空间大小,也就是说在表的数据量比较大的时候,为某个索引分配空间的时候就按照 区 为单位去分配,这样就可以保证页的物理地址连续,加载的时候更有可能是顺序IO
- 段其实是一个逻辑上的概念,由若干个零散的页和完整的区组成的,段的诞生主要是因为,如果索引节点所有的页类型都放入区中的话,就有可能造成数据页虽然连续,但是叶子节点和非叶子结点都会在一起,遍历的话就不合适了,所以我们尽量把叶子节点和非叶子节点分开放,这个时候就需要段的概念了,存放叶子节点的区的集合就算是一个段,存放非叶子节点的区的集合也算是一个段。也就是说一个索引会生成2个段,一个叶子节点段,一个非叶子节点段。
区
- 区,上面说了区的诞生是为了更好的管理页,所以一个区存储了64个页,然后每256个区就划分成一组,具体结构如下图
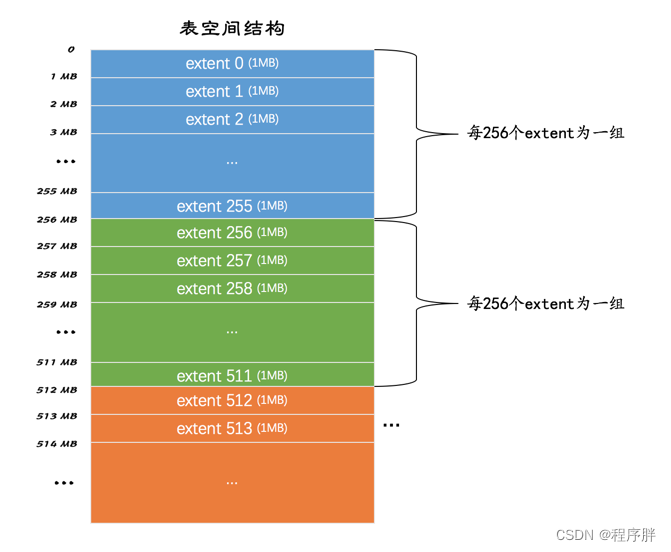
- 为什么分了区之后还要分组呢?
- 原因是更好管理,因为这些组的前两页都会存放对应组相关信息,至于存储了那些信息我们下面会讲
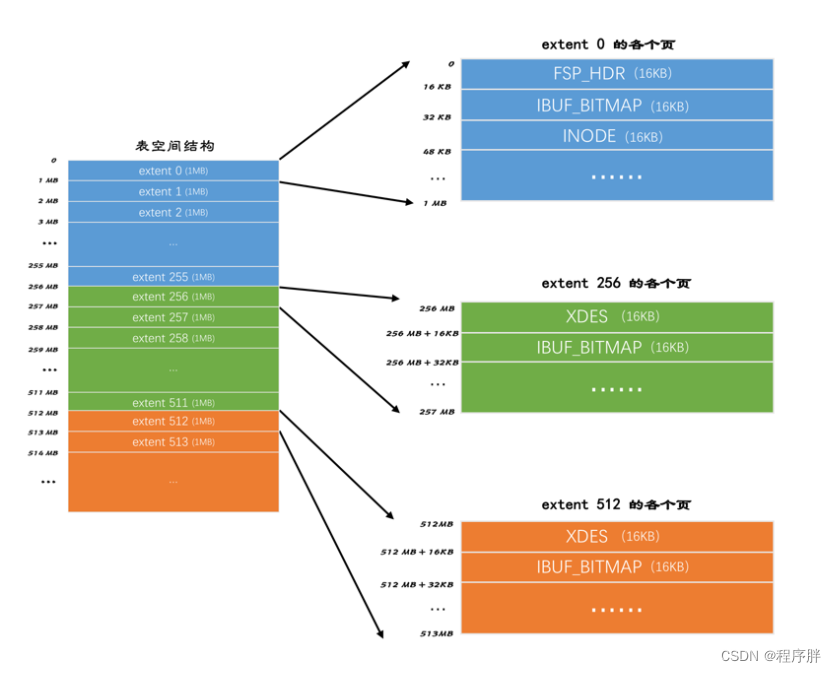
- 从上面我们可以知道每个分组的第一个区的前两页的信息是有差别的,主要的差别是第一组跟其他组的存放信息不一样,我们一一来看不同页的类型
- FSP_HDR 类型:用来登记整个表空间的一些整体属性以及本组所有的区,也就是extent 0 ~ extent 255这256个区的属性,并且整个表空间只有一个FSP_HDR 类型的页
- IBUF_BITMAP类型:
- INODE类型:
- XDES类型:全称是extent descriptor,用来登记本组256个区的属性,也就是说对于在extent 256区中的该类型页存储的就是extent 256 ~ extent 511这些区的属性,对于在extent 512区中的该类型页存储的就是extent 512 ~ extent 767这些区的属性。
- 现在我们回到区的概念,最上面我们讲过当数据量比较大的时候,我们就会通过区为单位存放数据,但是这样的话会产生很多碎片页,也就是说可能一个区只存了一半的数据页,剩下一半空闲着,这对存储来说利用率就太低了,所以我们会把这些剩余的区域叫做碎片区,也就是在一个碎片区中,并不是所有的页都是为了存储同一个段的数据而存在的,而是碎片区中的页可以用于不同的目的。
- 所以此后为某个段分配存储空间的策略是这样的:
- 在刚开始向表中插入数据的时候,段是从某个碎片区以单个页为单位来分配存储空间的。
- 当某个段已经占用了32个碎片区页之后,就会以完整的区为单位来分配存储空间。
区的分类
- 上面一大串来说,独立表空间其实是由若干个区组成的,所以各个区之间肯定也会有类型分类,下面我们就来讨论一下
- 区的类型主要分为4类:
- 空闲的区(FREE):现在还没有用到这个区中的任何页。
- 有剩余空间的碎片区(FREE_FRAG):表示碎片区中还有可用的页。
- 没有剩余空间的碎片区(FULL_FRAG):表示碎片区中的所有页都被使用,没有空闲页。
- 附属于某个段的区(FSEG):每一个索引都可以分为叶子节点段和非叶子节点段,除此之外InnoDB还会另外定义一些特殊作用的段,在这些段中的数据量很大时将使用区来作为基本的分配单位。
- 也就是区的类型处于FREE、FREE_FRAG以及FULL_FRAG这三种状态的区都是独立的,算是直属于表空间;而处于FSEG状态的区是附属于某个段的。
区类型的结构
- 为了方便管理这些区,每个区都对应着一个 称为XDES Entry的结构,如下图:
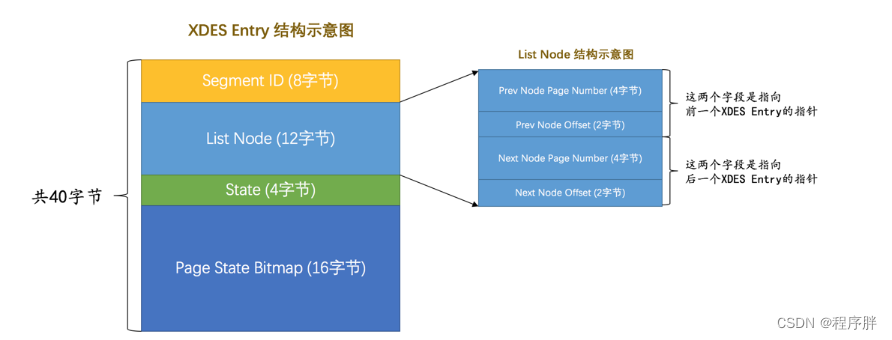
- Segment ID(8字节):段编号,属于是该区分配给哪个段了
- List Node(12字节):链表信息的字段,主要是为了指向前一个区和后一个区,将区与区之间变成一个双向链表,也就是说 XDES Entry 也是一个链表
- Pre Node Page Number和Pre Node Offset的组合就是指向前一个XDES Entry的指针
- Next Node Page Number和Next Node Offset的组合就是指向后一个XDES Entry的指针。
- State(4字节):这个区的类别,也就是上面说的FREE、FREE_FRAG、FULL_FRAG和FSEG
- Page State Bitmap(16字节):这个部分共占用16个字节,也就是128个比特位。我们说一个区默认有64个页,这128个比特位被划分为64个部分,每个部分2个比特位,对应区中的一个页。这两个比特位的第一个位表示对应的页是否是空闲的,第二个比特位还没有用。
- 下面我们就来看看,为什么提出这个XDES Entry的结构?
- 我们知道提出区和段是为了提高插入大量数据的效率,并且
又不至于数据量少的表浪费空间,现在我们知道向表中插入数据本质上就是向表中各个索引的叶子节点段、非叶子节点段插入数据,也知道了不同的区有不同的状态,再回到最初的起点,捋一捋向某个段中插入数据的过程:- 一般分为两种情况,看段内的数据多少,一般判断条件是段内数据页是否占满32个
- 如果没有占满,首先会看段中是否有FREE_FRAG 也就是碎片区
- 如果有则使用
- 如果没有,则申请状态为FREE ,空闲区来存储,并且将这个区域的状态改为FREE_FRAG 碎片区,如果刚好满了则将区的状态改为FULL_FRAG
- 如果有,我们就会申请完整的区来存放数据,也就是状态为FREE
- 如果没有占满,首先会看段中是否有FREE_FRAG 也就是碎片区
- 一般分为两种情况,看段内的数据多少,一般判断条件是段内数据页是否占满32个
- 以上流程有个问题,我们如何更快更方便的知道那些区是空闲,那些区是碎片区?
- 答案是XDES Entry 这个结构体,你想我们如果把所有空闲区变成这个链表,每次都获取头部,是不是简单多了,包括碎片区也同样,这样的话我们就可以根据 FREE,FREE_FRAG 和 FULL_FRAG 创建三个链表。
- 这样的解决方法虽然很不错,但还有一些问题,我们怎么知道哪些区属于哪个段的呢?再遍历各个XDES Entry结构?
- 最简单的方法就是我们把所有状态为为FSEG的区对应的XDES Entry结构都加入到一个链表
- 但这样还有问题,不同的段哪能共用一个区呢?你想把索引a的叶子节点段和索引b的叶子节点段都存储到一个区中么?
- 当然不能,所以我们需要根据段号 来建立链表,有多少段就建立多少链表
- 还有问题,因为一个段中可以有好多个区,有的区是完全空闲的,有的区还有一些页可以用,有的区已经没有空闲页可以用了,所以我们有必要继续细分,设计InnoDB的大佬们为每个段中的区对应的XDES Entry结构建立了三个链表:
- FREE链表:同一个段中,所有页都是空闲的区对应的XDES Entry结构会被加入到这个链表。注意和直属于表空间的FREE链表区别开了,此处的FREE链表是附属于某个段的。
- NOT_FULL链表:同一个段中,仍有空闲空间的区对应的XDES Entry结构会被加入到这个链表。
- FULL链表:同一个段中,已经没有空闲空间的区对应的XDES Entry结构会被加入到这个链表。
- 以上我们这样的解决方式可以差不多解决管理区域的大部分问题,现在还有个问题,我们怎么找到这些链表呢,或者说怎么找到某个链表的头节点或者尾节点在表空间中的位置呢?
- 这个时候我们就需要推出 一个 叫 List Base Node 的结构,也就是链表基节点,一般我们把某个链表对应的List Base Node结构放置在表空间中固定的位置,这样想找定位某个链表就变得简单
链表基节点
- 每个链表都会有一个 这样的结构:

- List Length表明该链表一共有多少节点,
- First Node Page Number和First Node Offset表明该链表的头节点在表空间中的位置。
- Last Node Page Number和Last Node Offset表明该链表的尾节点在表空间中的位置。
小结
- 表空间是由若干个区组成的
- 每个区对应一个XDES Entry的结构,而这个结构可以分成FREE、FREE_FRAG和FULL_FRAG 这三种类型的链表
- 每个段可以附属若干个区,每个段中的区对应的XDES Entry结构可以分成FREE、NOT_FULL和FULL这3个链表。
- 每个链表都对应一个List Base Node的结构,这个结构里记录了链表的头、尾节点的位置以及该链表中包含的节点数。