版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
大数据系列文章目录
官方网址:https://flink.apache.org/
学习资料:https://flink-learning.org.cn/

目录
- addSource方法
- 接口: SourceFunction
- Flink自带的创建Source的方法
- 自定义实现Source的注意事项
- 继承关系
- Source定义演示
- 基于本地集合的非并行Source
- 基于本地集合的并行Source
- 基于文件的source
- 基于网络套接字的source
- 自定义的source(Custom-source)
- 自定义实现SourceFunction接口
- 实现ParallelSourceFunction创建可并行Source
- 实现RichParallelSourceFunction:创建并行并带有Rich功能的Source
- 基于kafka的source操作
- 基于mysql的source操作
addSource方法
Flink提供了一个方法 通过env对象调用addSource方法,需要传入一个SourceFunction接口的实例化对象
这个方法是最根本的定义Source的方法。
我们如果想要定义Source,可以调用这个方法来得到DataStream对象
接口: SourceFunction
调用addSource方法需要传入接口SourceFunction的实例化对象(接口实现的子类)
在Flink中,所有创建Source的方式,在继承关系上,顶级父类均是这个SourceFunction接口


我们如果调用addSource方法来获取Source对象可以自定义SourceFunction的实现来完成方法调用。
Flink自带了SourceFunction的许多已实现的子类,最常用的有3个:
- RichSourceFunction(抽象类) 带有Rich功能的SourceFunction接口实现类(不可并行)
- ParallelSourceFunction(接口) 可并行的SourceFunction接口实现类
- RichParallelSourceFunction(抽象类) 可并行的带有Rich功能SourceFunction接口实现类
那么,我们在调用addSource方法的时候,除了可以实现SourceFunction接口外,这3个常见的实现我们也可以继承使用。
Flink自带的创建Source的方法
除了使用addSource方法创建Source外,Flink也自带了许多方法供我们快捷创建对应的Source
- fromElements 从元素中获取数据, 不可并行, 底层调用的fromCollection
- fromCollection 从集合中获取数据,不可并行,底层调用的addSource方法,传入的是FromElementsFunction类(SourceFunction接口的实现子类)
- socketTextStream 从socket中获取数据,不可并行,底层调用的addSource方法,传入的SocketTextStreamFunction类(SourceFunction的实现子类)
- generateSequence 生成一个序列,可以并行,底层调用的StatefulSequenceSource(RichParallelSourceFunction的实现子类)
- fromParallelCollection 从集合中获取数据,可以并行,底层addSource方法,传入的FromSplittableIteratorFunction(RichParallelSourceFunction的实现)
- readTextFile 从文件中获取数据,可以并行,底层addSource方法,传入的ContinuousFileMonitoringFunction(RichSourceFunction的实现)
我们可以根据需求,调用上面的方法来获取数据
也可以调用addSource方法,自行提供自定义的实现
自定义实现Source的注意事项
如果想要使用addSource方法自定义实现Source,关于并行度需要注意:
- 直接提供SourceFunction的实现,不可并行
- 直接提供RichSourceFunction的实现,不可并行
- 直接提供ParallelSourceFunction的实现,可以并行
- 直接提供RichParallelSourceFunction,可以并行
我们自行根据是否需要并行来选择对应的接口或抽象类来实现。
继承关系

Source定义演示
基于本地集合的非并行Source
package batch.source;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.Arrays;
/**
* @author lwh
* @date 2023/4/20
* @description 基于本地集合的非并行source
**/
public class BasicSourceDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> source1 = env.fromElements("hadoop", "spark", "flink");
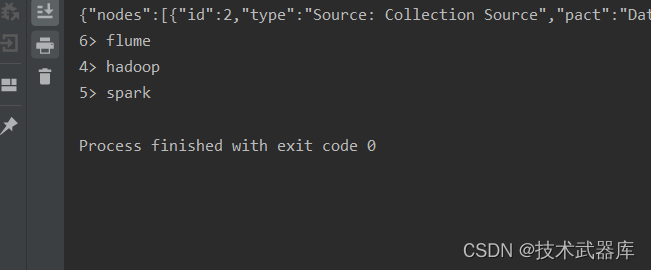
DataStreamSource<String> source2 = env.fromCollection(Arrays.asList("hadoop", "spark", "flume"));
// source1.print().setParallelism(1);
source2.print();
System.out.println(env.getExecutionPlan());
env.execute();
}
}
基于本地集合的并行Source
package batch.source;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.NumberSequenceIterator;
/**
* @author lwh
* @date 2023/4/20
* @description 基于本地集合的并行source
**/
public class BasicParallelSourceDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Long> source1 = env.generateSequence(1, 10).setParallelism(6);
// fromParallelCollection 只接受SplittableIterator的子类
// 也就是只能是:NumberSequenceIterator或者LongValueSequenceIterator
DataStreamSource<Long> source2 = env.fromParallelCollection(
new NumberSequenceIterator(1, 10), TypeInformation.of(Long.TYPE));
source1.print();
source2.setParallelism(3).print();
System.out.println(env.getExecutionPlan());
env.execute();
}
}
基于文件的source
Flink的流处理可以直接通过readTextFile()方法读取文件来创建数据源,方法如下:
package batch.source;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @author lwh
* @date 2023/4/20
* @description 基于文件的source
**/
public class FileSourceDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> localFileSource = env.readTextFile("data/input/score.csv", "UTF-8");
// DataStreamSource<String> hdfsFileSource = env.readTextFile("hdfs://node1:8020/input/license.txt");
localFileSource.print();
// hdfsFileSource.print();
env.execute();
}
}
基于网络套接字的source
上面两种方式创建的数据源一般都是固定的.如果需要源源不断的产生数据,可以使用socket的方式来获取数据,通过调用socketTextStream()方法
示例
编写Flink程序,接收socket的单词数据,并以空格进行单词拆分打印。
步骤
- 获取流处理运行环境
- 构建socket流数据源,并指定IP地址和端口号
- 对接收到的数据进行空格拆分
- 打印输出
- 启动执行
- 在Linux中,使用nc -lk 端口号监听端口,并发送单词
package batch.source;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @author lwh
* @date 2023/4/20
* @description 基于网络套接字的source
**/
public class SocketSourceDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 参数1 要连接的主机名 参数2 要连接的主机端口
DataStreamSource<String> socketSource = env.socketTextStream("node1", 9999);
socketSource.print();
env.execute();
}
}
自定义的source(Custom-source)
自定义实现SourceFunction接口
除了预定义的Source外,我们还可以通过实现SourceFunction来自定义Source,然后通过StreamExecutionEnvironment.addSource(sourceFunction)添加进来。
示例
自定义数据源, 每1秒钟随机生成一条订单信息(订单ID、用户ID、订单金额、时间戳)
要求
- 随机生成订单ID(UUID)
- 随机生成用户ID(0-2)
- 随机生成订单金额(0-100)
- 时间戳为当前系统时间
开发步骤
- 创建订单实体类
- 创建自定义数据源
- 死循环生成订单
- 随机构建订单信息
- 上下文收集数据
- 每隔一秒执行一次循环
- 获取流处理环境
- 使用自定义Source
- 打印数据
- 执行任务
订单实体类
package entity;
import lombok.AllArgsConstructor;
import lombok.Data;
/**
* @author lwh
* @date 2023/4/20
* @description
**/
@Data
@AllArgsConstructor
public class Order {
private String id;
private String userId;
private int money;
private Long time;
}
流处理代码
package batch.source;
import entity.Order;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import java.util.Random;
import java.util.UUID;
/**
* @author lwh
* @date 2023/4/20
* @description 自定义实现SourceFunction接口
**/
public class CustomerSourceWithoutParallelDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Order> mySource = env.addSource(new MySource());
mySource.print();
env.execute();
}
public static class MySource implements SourceFunction<Order> {
private boolean isRun = true; // 关闭循环标记
@Override
public void run(SourceContext<Order> ctx) throws Exception {
Random random = new Random();
while (isRun) {
String id = UUID.randomUUID().toString();
String userId = random.nextInt(99) + "";
int money = random.nextInt(999);
long time = System.currentTimeMillis();
ctx.collect(new Order(id, userId, money, time));
Thread.sleep(1000L);
}
}
@Override
public void cancel() {
this.isRun = false;
}
}
}
实现ParallelSourceFunction创建可并行Source
package batch.source;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.ParallelSourceFunction;
import java.util.UUID;
/**
* @author lwh
* @date 2023/4/20
* @description 自定义多并行度Source
**/
public class CustomerSourceWithParallelDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> mySource = env.addSource(new MySource()).setParallelism(6);
mySource.print();
env.execute();
}
public static class MySource implements ParallelSourceFunction<String> {
@Override
public void run(SourceContext<String> ctx) throws Exception {
ctx.collect(UUID.randomUUID().toString());
/*
如果不设置无限循环可以看出,设置了多少并行度就打印出多少条数据
*/
}
@Override
public void cancel() {}
}
}
实现RichParallelSourceFunction:创建并行并带有Rich功能的Source
package batch.source;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import java.util.UUID;
/**
* @author lwh
* @date 2023/4/20
* @description 自定义一个RichParallelSourceFunction的实现
**/
public class CustomerRichSourceWithParallelDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> mySource = env.addSource(new MySource()).setParallelism(6);
mySource.print();
env.execute();
}
/*
Rich 类型的Source可以比非Rich的多出有:
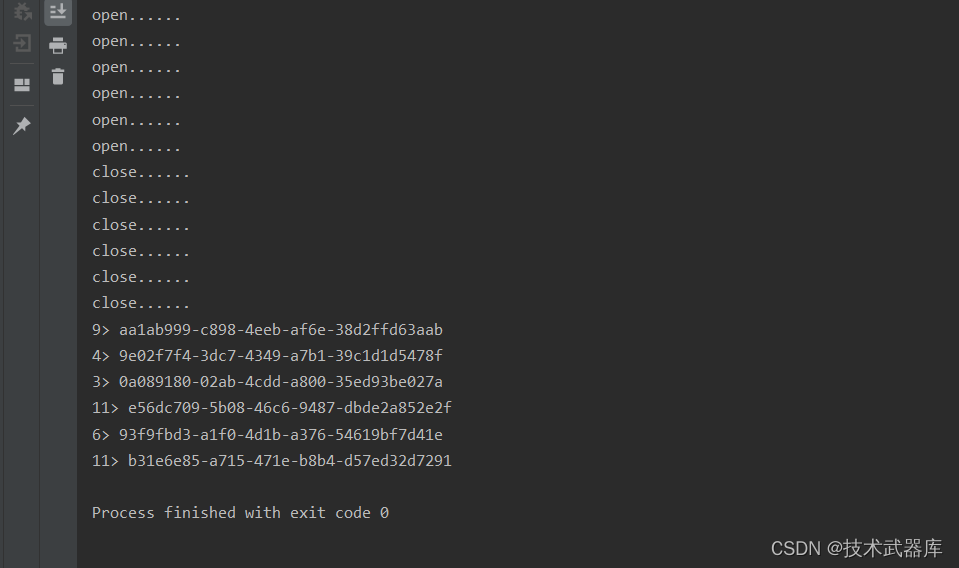
- open方法,实例化的时候会执行一次,多个并行度会执行多次的哦(因为是多个实例了)
- close方法,销毁实例的时候会执行一次,多个并行度会执行多次的哦
- getRuntime方法可以获得当前的Runtime对象(底层API)
*/
public static class MySource extends RichParallelSourceFunction<String> {
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
System.out.println("open......");
}
@Override
public void close() throws Exception {
super.close();
System.out.println("close......");
}
@Override
public void run(SourceContext<String> ctx) throws Exception {
ctx.collect(UUID.randomUUID().toString());
}
@Override
public void cancel() {
}
}
}
基于kafka的source操作
Flink 是新一代流批统一的计算引擎,它需要从不同的第三方存储引擎中把数据读过来,进行处理,然后再写出到另外的存储引擎中。Connector 的作用就相当于一个连接器,连接 Flink 计算引擎跟外界存储系统。Flink 里有以下几种方式,当然也不限于这几种方式可以跟外界进行数据交换
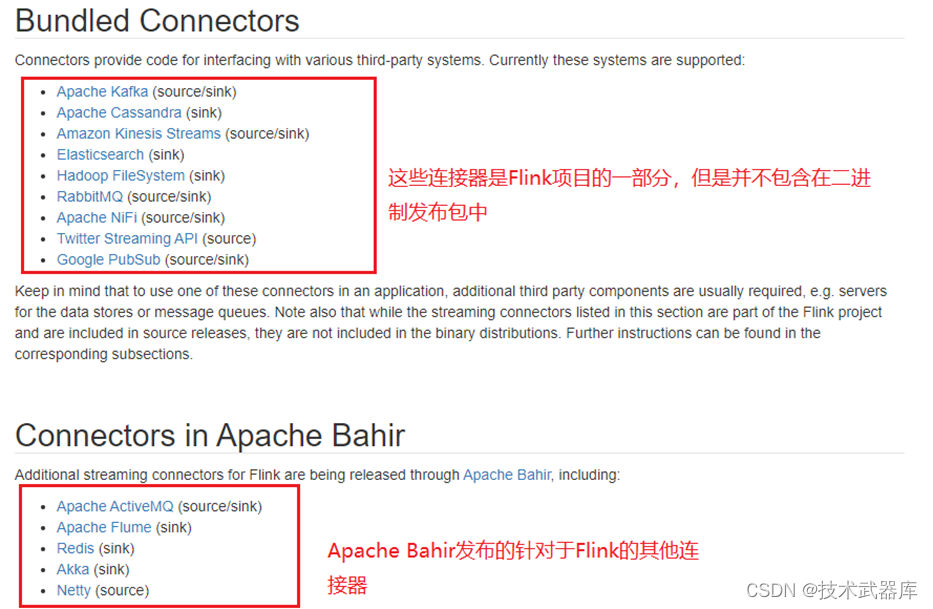
在这里重点介绍生产环境中最常用到的 Flink kafka connector。同学们对kafka非常熟悉,它是一个分布式的、分区的、多副本的、 支持高吞吐的、发布订阅消息系统。生产环境环境中也经常会跟 kafka 进行一些数据的交换,比如利用 kafka consumer 读取数据,然后进行一系列的处理之后,再将结果写出到 kafka 中。

构造函数参数说明
- 主题名称/主题名称列表
- 反序列化器
- Kafka消费者的属性。需要以下属性:
bootstrap.servers(以逗号分隔的Kafka连接地址)
zookeeper.connect(逗号分隔的Zookeeper服务器列表)(仅Kafka 0.8需要)
group.id(消费者群组的ID)
反序列化Schema类型
作用:对kafka里获取的二进制数据进行反序列化
FlinkKafkaConsumer需要知道如何将kafka中的二进制数据转换成Java/Scala对象
常用的反序列化Schema
| Schema | 说明 |
|---|---|
| SimpleStringSchema | 按字符串方式进行序列化,反序列化 |
| TypeInformationSerializationSchema | (适合读写均是flink的场景)他们会基于Flink的TypeInformation来创建schema。这对于那些从Flink写入,又从Flink读出的数据是很有用的。这种Flink-specific的反序列化会比其他通用的序列化方式带来更高的性能。 |
| JSONDeserializationSchema | 可以把序列化后的Json反序列化成ObjectNode,ObjectNode可以通过objectNode.get(“field”).as(Int/String/…)() 来访问指定的字段 |
Kafka Consumers消费模式配置
在取得KafkaConsumer对象后,可以设置如下方法,来配置消费模式:
| 消费模式 | 描述 |
|---|---|
| setStartFromGroupOffsets(默认) | 从kafka记录的group.id的位置开始读取,如果没有根据auto.offset.reset设置的策略 |
| setStartFromEarliest | 从kafka最早的位置读取 |
| setStartFromLatest | 从kafka最新数据开始读取 |
| setStartFromTimestamp | 从时间戳大于或者等于指定时间戳的位置开始读取 |
| setStartFromSpecificOffsets | 从指定的分区的offset位置开始读取,如指定的offsets中不存在某个分区,该分区从group offset位置开始读取 |
topic 和 partition 动态发现
实际的生产环境中可能有这样一些需求,比如:
- 场景一:有一个 Flink 作业需要将五份数据聚合到一起,五份数据对应五个 kafka topic,随着业务增长,新增一类数据,同时新增了一个 kafka topic,如何在不重启作业的情况下作业自动感知新的 topic。
- 场景二:作业从一个固定的 kafka topic 读数据,开始该 topic 有 10 个 partition,但随着业务的增长数据量变大,需要对 kafka partition 个数进行扩容,由 10 个扩容到 20。该情况下如何在不重启作业情况下动态感知新扩容的 partition?
针对上面的两种场景,首先需要在构建 FlinkKafkaConsumer 时的 properties 中设置 flink.partition-discovery.interval-millis 参数为非负值,表示开启动态发现的开关,以及设置的时间间隔 。此时 FlinkKafkaConsumer 内部会启动一个单独的线程定期去 kafka 获取最新的 meta 信息。
- 针对场景一,还需在构建 FlinkKafkaConsumer 时,topic 的描述可以传一个正则表达式描述的 pattern。每次获取最新 kafka meta 时获取正则匹配的最新 topic 列表。
- 针对场景二,设置前面的动态发现参数,在定期获取 kafka 最新 meta 信息时会匹配新的 partition。为了保证数据的正确性,新发现的 partition 从最早的位置开始读取。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties props = new Properties();
//指定Kafka的Broker地址
props.setProperty("bootstrap.servers","node01:9092");
//指定组ID
props.setProperty("group.id","test0311301");
//如果没有记录偏移量,第一次从最开始消费
props.setProperty("auto.offset.reset", "earliest");
//设置动态分区检测
props.setProperty("flink.partition-discovery.interval-millis", "30000");
FlinkKafkaConsumer<String> myConsumer = new FlinkKafkaConsumer<>(
java.util.regex.Pattern.compile("test-topic-[0-9]"),
new SimpleStringSchema(),
props);
DataStream<String> stream = env.addSource(myConsumer);
....
使用
使用Flink流处理方式,读取Kafka的数据,并打印
开发步骤
- 创建流处理环境
- 指定链接kafka相关信息
- 创建kafka数据流
- 添加Kafka数据源
- 打印数据
- 执行任务
Kafka相关操作
创建topic
./bin/kafka-topics.sh --create --partitions 1 --replication-factor 1 --topic kafkatopic --zookeeper node1:2181
模拟生产者
./bin/kafka-console-producer.sh --broker-list node1:9092 --topic kafkatopic
模拟消费者
./bin/kafka-console-consumer.sh --from-beginning --topic kafkatopic --zookeeper node1:2181
测试代码
package batch.source;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
/**
* @author lwh
* @date 2023/4/20
* @description 测试kafka source
**/
public class KafkaSourceDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
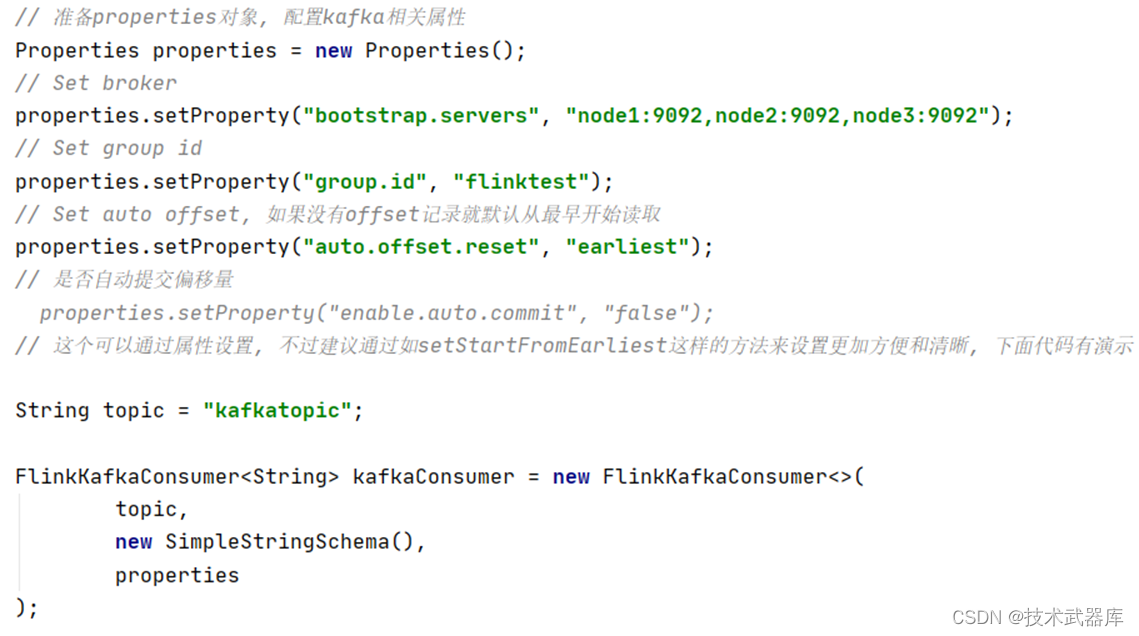
// 准备properties对象, 配置kafka相关属性
Properties properties = new Properties();
// Set broker
properties.setProperty("bootstrap.servers", "node1:9092,node2:9092,node3:9092");
// Set group id
properties.setProperty("group.id", "flinktest");
// Set auto offset, 如果没有offset记录就默认从最早开始读取
properties.setProperty("auto.offset.reset", "earliest");
// 是否自动提交偏移量
// properties.setProperty("enable.auto.commit", "false");
// 这个可以通过属性设置, 不过建议通过如setStartFromEarliest这样的方法来设置更加方便和清晰, 下面代码有演示
String topic = "kafkatopic";
FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<>(
topic,
new SimpleStringSchema(),
properties
);
/*
kafka的source对象可以指定从哪里开始消费
如:
kafkaConsumer.setStartFromEarliest(); // 从头开始消费
kafkaConsumer.setStartFromTimestamp(System.currentTimeMillis()); // 从指定的时间戳开始消费
kafkaConsumer.setStartFromGroupOffsets(); // 从group 中记录的offset开始消费
kafkaConsumer.setStartFromLatest(); // 从最新开始消费
以及指定每个从某个topic的某个分区的某个offset开始消费
Map<KafkaTopicPartition, Long> offsets = new HashMap<>();
offsets.put(new KafkaTopicPartition(topic, 0), 0L);
offsets.put(new KafkaTopicPartition(topic, 1), 0L);
offsets.put(new KafkaTopicPartition(topic, 2), 0L);
kafkaConsumer.setStartFromSpecificOffsets(offsets);
如上, 就指定了topic的分区0,1,2 都分别从offset 0 开始消费.
*/
kafkaConsumer.setStartFromEarliest(); // 从最早开始消费
// 通过KafkaConsumer对象, 得到kafka的source对象
DataStreamSource<String> kafkaSource = env.addSource(kafkaConsumer);
kafkaSource.print();
env.execute("KafkaSourceDemo");
}
}
基于mysql的source操作
上面我们已经使用了自定义数据源和Flink自带的Kafka source,那么接下来就模仿着写一个从 MySQL 中读取数据的 Source。
示例
自定义数据源, 读取MySql数据库(test)表(user)数据
| id | username | password | name |
|---|---|---|---|
| 10 | dazhuang | 123456 | 大壮 |
| 11 | erya | 123456 | 二丫 |
| 12 | sanpang | 123456 | 三胖 |
建表语句
CREATE TABLE `user` (
`id` int(11) NOT NULL,
`username` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`password` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT;
INSERT INTO `flink`.`user`(`id`, `username`, `password`, `name`) VALUES (10, 'dazhuang', '123456', '大壮');
INSERT INTO `flink`.`user`(`id`, `username`, `password`, `name`) VALUES (11, 'erya', '123456', '二丫');
INSERT INTO `flink`.`user`(`id`, `username`, `password`, `name`) VALUES (12, 'sanpang', '123456', '三胖');
<!-- 指定mysql-connector的依赖 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.48</version>
</dependency>
开发步骤
- 自定义Source,继承自RichSourceFunction
- 实现open方法
- 实现run方法
- 加载驱动
- 创建连接
- 创建PreparedStatement
- 执行查询
- 遍历查询结果,收集数据
- 使用自定义Source
- 打印结果
- 执行任务
代码
package batch.source;
import entity.UserInfo;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
/**
* @author lwh
* @date 2023/4/20
* @description 基于mysql的source操作
**/
public class CustomerMysqlSourceDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 获得自定义Source对象
DataStreamSource<UserInfo> mysqlSource = env.addSource(new MyMysqlSource());
mysqlSource.print();
env.execute("CustomerMySQLSourceDemo");
}
/**
自定义Mysql Source实现类
*/
public static class MyMysqlSource extends RichSourceFunction<UserInfo> {
private Connection connection = null; // 定义数据库连接对象
private PreparedStatement ps = null; // 定义PreparedStatement对象
/*
使用open方法, 这个方法在实例化类的时候会执行一次, 比较适合用来做数据库连接
*/
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
// 加载数据库驱动
Class.forName("com.mysql.jdbc.Driver");
// 创建数据库连接
String url = "jdbc:mysql://localhost:3306/flink?useUnicode=true&characterEncoding=utf-8&useSSL=false";
this.connection = DriverManager.getConnection(url, "root", "123456");
// 准备PreparedStatement对象
this.ps = connection.prepareStatement("SELECT id, username, password, name FROM user");
}
// 使用close方法, 这个方法在销毁实例的时候会执行一次, 比较适合用来关闭连接
@Override
public void close() throws Exception {
super.close();
// 关闭资源
if (this.ps != null) this.ps.close();
if (this.connection != null) this.connection.close();
}
@Override
public void run(SourceContext<UserInfo> ctx) throws Exception {
ResultSet resultSet = ps.executeQuery();
while (resultSet.next()) {
int id = resultSet.getInt("id");
String username = resultSet.getString("username");
String password = resultSet.getString("password");
String name = resultSet.getString("name");
ctx.collect(new UserInfo(id, username, password, name));
}
}
@Override
public void cancel() {
System.out.println("任务被取消......");
}
}
}