一、创建一个Scrapy项目fanyi,并进入该项目创建,fanyipc爬虫文件
scrapy startproject fanyi
cd fanyi
scrapy genspider example example.com二、修改配置文件settings,关闭君子协议,只看报错信息,自定义UA头
ROBOTSTXT_OBEY = False
LOG_LEVEL = 'ERROR'
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"三、分析目标网址,用的POST请求
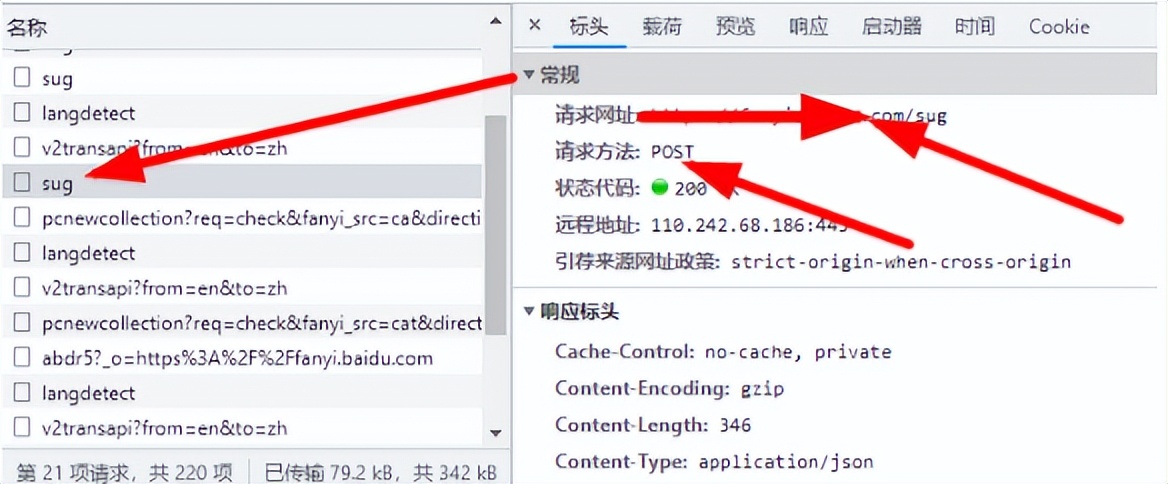
四、重写父类方法实现POST请求
start_urls = ["https://fanyi.baidu.com/sug"]
def start_requests(self):
POST数据={'kw':'cat'}
for url in self.start_urls:
yield scrapy.FormRequest(url=url,callback=self.parse,formdata=POST数据)
def parse(self, response):
结果=response.json()
#print(结果)五、运行结果
{'errno': 0, 'data': [{'k': 'cat', 'v': 'n. 猫; 猫科动物; 狠毒的女人; 爵士乐爱好者 vt. 把(锚)吊放在锚架上; 〈俚〉寻欢,宿娼'}, {'k': 'CAT', 'v': 'abbr. Carburetor Air
Temperature 汽化器空气温度'}, {'k': 'Cat', 'v': '[人名] 卡特'}, {'k': 'CaT', 'v': 'abbr. calcium tartrate tetrahydrate 酒石酸钙四水合物'}, {'k': 'cata', 'v': '[机] 渺位;
依照'}]}六、如果首页地址是get请求,解析内容用到了POST请求,可以在psrse里面再进行post操作

![[LeetCode周赛复盘] 第 342 场周赛20230423](https://img-blog.csdnimg.cn/002404b0dfca4a4e855cbfd4c3d9f6dc.png)






![[HBZ分享] 小米手机如何解BL锁](https://img-blog.csdnimg.cn/7974185433104db192cc9f4f871078fb.png)

