要说明的一点是:此处理方式会进行数据的删除,并且多实例情况下最好都做下操作。多实例都操作一遍的意思就是比如我普罗米修斯有如下四个:
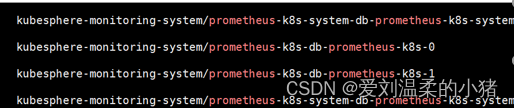
如果Prometheus-k8s-0一直重启,则不光需要操作Prometheus-k8s-0,也需要对它的另一个实例Prometheus-k8s-1进行处理。如果是Prometheus-k8s-system0出问题也是同理,需要把system1也一并处理下,因为他们有同步机制。
正文开始!!!
1、找到Prometheus 的数据卷,清空里面的内容(Prometheus不断重启,往往是储存的数据过多引起的,程序被拖死或者无法同步)
执行命令: kubectl get pv | grep “prometheus”

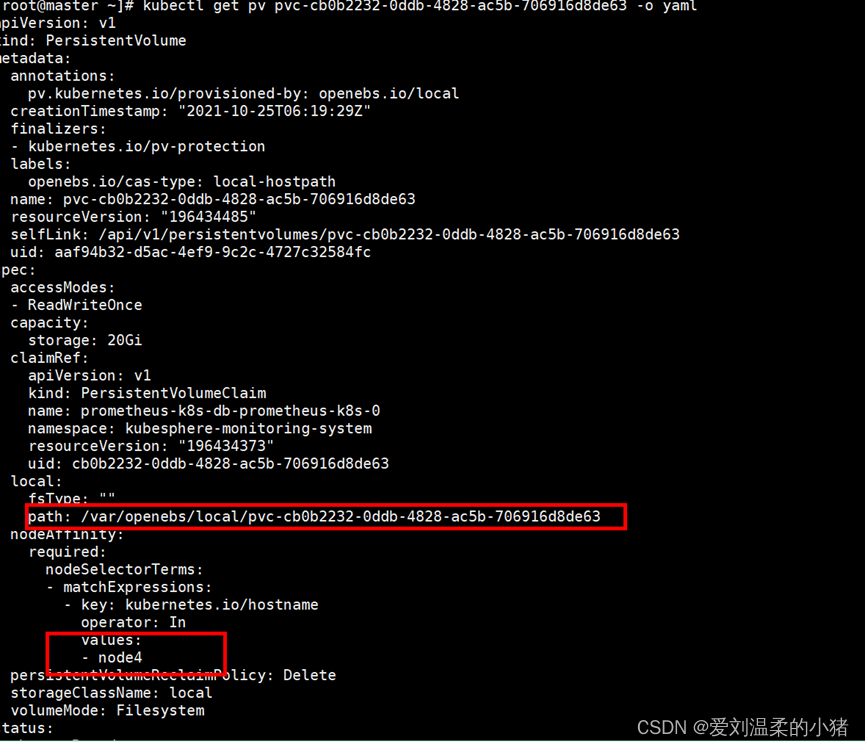
2、根据名字,找到不断重启的Prometheus项目,打开配置文件,找到节点和路径。
执行命令: kubectl get pv pvc-cb0b2232-0ddb-4828-ac5b-706916d8de63 -o yaml
3、先关掉prometheus。
命令:kubectl edit prometheus -n kubesphere-monitoring-system k8s-system
注意命令最后的k8s-system ,是根据需要(不断重启的pod)选择k8s 或 k8s-system。
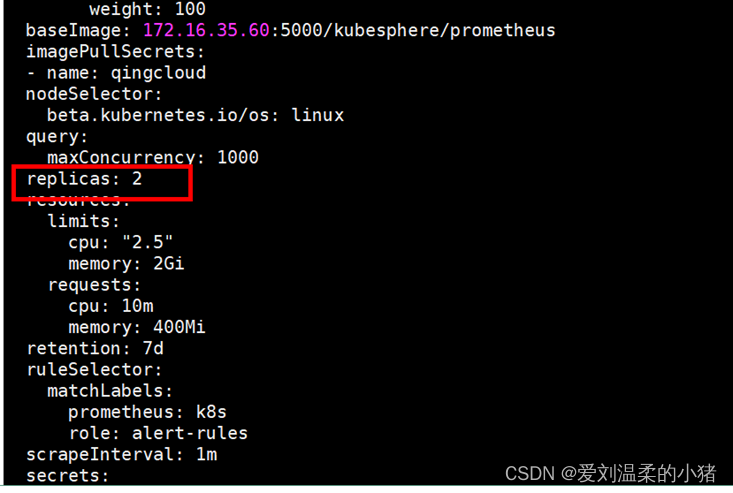
然后将其实例数从2设置为0(记得记录下原值)
4、到pv所在节点的机器(例子里是Node4节点机器)上,打开所在目录。
执行命令:cd /var/openebs/local/pvc-cb0b2232-0ddb-4828-ac5b-706916d8de63
再执行命令:ls

删除:promethes-db
命令:rm -rf promethes-db
5、回到主节点, 恢复promethes的实例数。
命令:kubectl edit prometheus -n kubesphere-monitoring-system k8s-system
注意命令最后的k8s-system ,是根据需要(不断重启的pod)选择k8s 或 k8s-system。
然后将其实例数从0设置为2(恢复原值)

至此,就已经解决了不断重启的问题。记得多实例一定要都操作一次,把多个实例的pvc中的db都删除了,在启动。