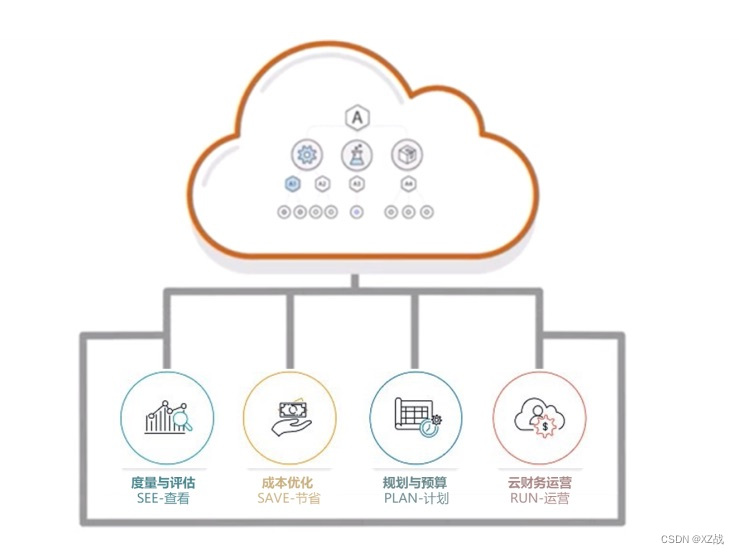
有时候写爬虫难免会遇上只提供一张图表却没有背后结构化数据的情况,尤其是金融市场数据,例如股票K线,基金净值等。笔者看了市面上主流的行情网站,基本都是图一这样的交互式图表,但这样的图表是没有办法直接拿到原始数据的:
图一:网页上的交互式图表(数据来源:天天基金网)
电脑内存虚位以待,推导好的模型嗷嗷待哺,距离成功就差一个精致的爬虫!
本文主要内容如下:
目录
1. 网站内嵌的图表类型
2. 爬取方案
3. 普通js加载的交互式图表爬取
3.1 Cookie验证
3.2 结果展示
4. 防盗链验证爬取
5. 总结
1. 网站内嵌的图表类型
笔者大致总结了几种类型:
1):截图,这数据完全没办法爬取,嗯,就是这样。

2):可见的结构化数据表格
网站上现成的数据表格,属于可见即可爬,是最常遇见的类型之一。像这种表格是非常好爬的,比较简单就不进行讲解了。
图二:结构化图表数据(数据来源:新浪财经)
3):普通js加载的交互式图表
例如百度股市通采用的就是这种方式, 当鼠标移动到图表上时,图表相应的会显示出时间,开盘价,收盘价等数据。如图三:
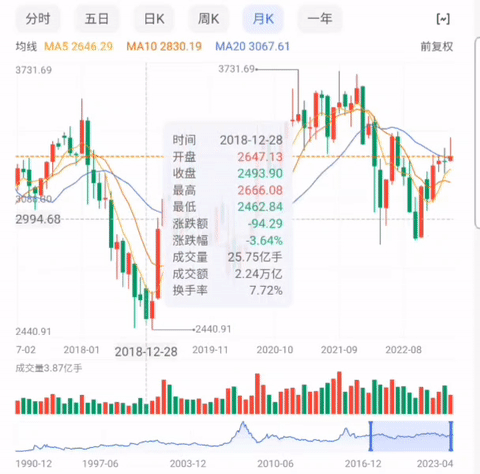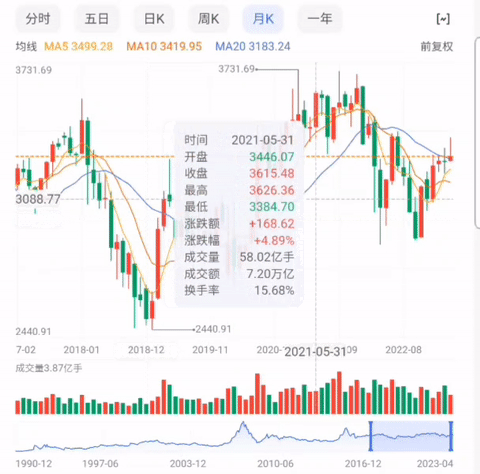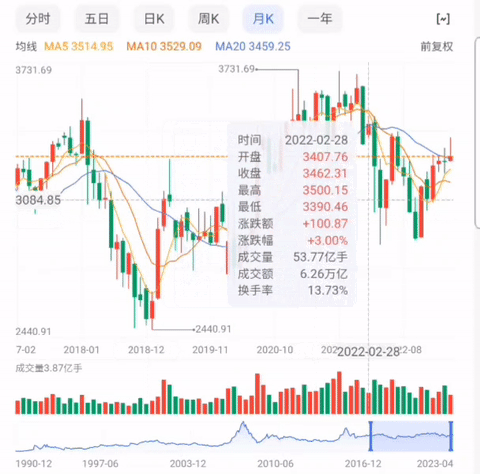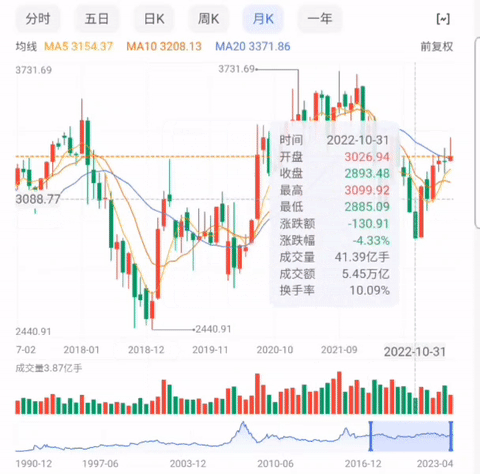
图三:上证K线图(数据来源:百度股市通)
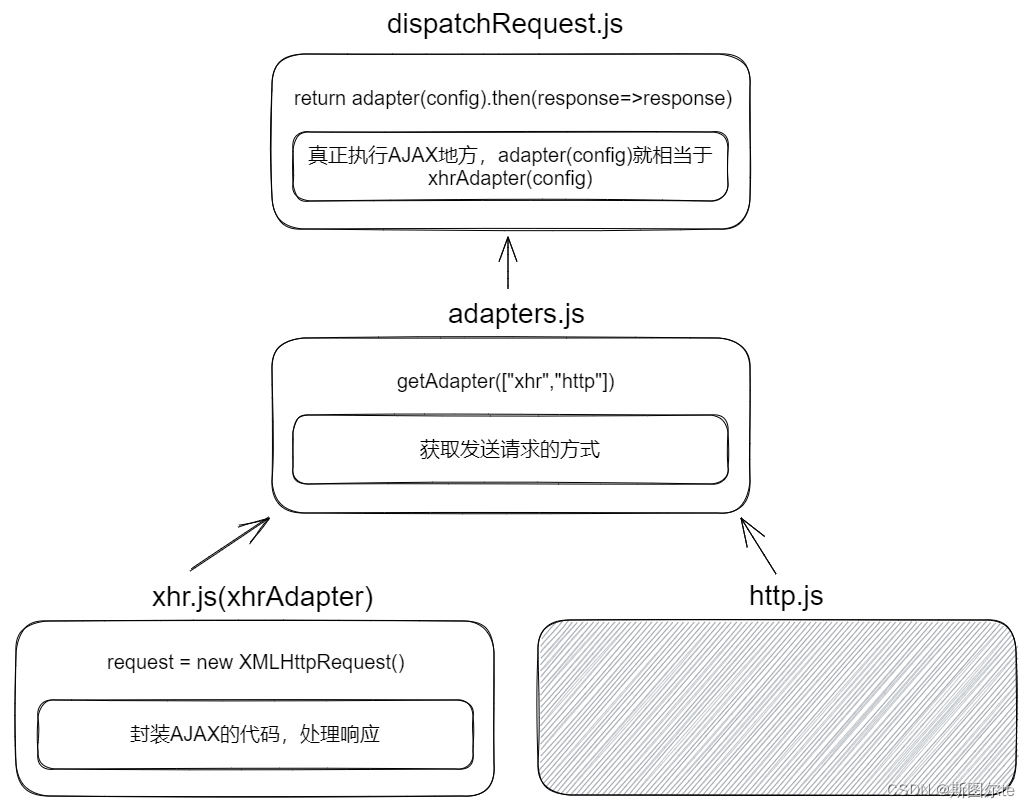
那么这种效果是如何达到的?一种做法是鼠标放在图表上时向服务器现请求数据,不过这显然是很笨的做法,还会给服务器造成很大压力。
还有一种做法是浏览器向服务器请求时,服务器所返回的内容中其实就已经包含了所有原始数据,然后将已经下载好的数据通过JavaScript插件等方式在网页上显示成图表。简单来说就是提前将数据提前全部下载好,当鼠标移动到相应的位置时,通过直接访问已经下载好数据并直接展示到网页图表上即可。
4):带有防盗链机制的图表
原理其实和3)一样,只是多引入了一个反爬机制。当直接引入外部文件(图片、js等)出现403 forbidden,这其实就是浏览器的防盗链机制。例如新浪财经就是这样的,下面是新浪财经的一个数据接口网址,如果直接访问就会报错:
https://hq.sinajs.cn/rn=1682082071654&list=s_sh000001,s_sz399001,nf_IF0,rt_hkHSI,gb_$dji,gb_ixic,b_SX5E,b_UKX,b_NKY,hf_CL,hf_GC,hf_SI,hf_CAD
## Forbidden东方财富部分的数据接口地址也用了防盗链,防盗链其实是利用HTTP header中的referer来实现。可以将referer比作“密钥”,当浏览器向服务器发送请求时会带上“密钥”,服务器如果识别到“密钥”不正确就不会将请求发送出去并且报错。
本期重点讨论3和4这两种类型,还有更麻烦的账号登录和各种五花八门的验证码就不讨论了。
2. 爬取方案
由于普通数据加载型交互式图表是提前将所有原始数据下载好,这就为爬取原始数据提供了一个突破口——绕过js,找到原始数据的接口地址,就可以轻易把所有数据扒下来。下面笔者将以百度股市通的上证指数图和东方财富的基金走势图为例进行爬取。
先把需要的模块导入:
import pandas as pd
import requests 3. 普通js加载的交互式图表爬取
以百度股市通的上证指数图表为例,网址为:百度股市通-上证指数。网址打开后再按F12,在网络中监控浏览器所请求的网址。如图四,点击一下日频走势图,接着会发现浏览器网络里多出来几个请求。点开后就可以直接看到所请求的详细信息。找到那个使用get方法的请求,而这个请求的URL即是原始数据的接口地址了。这连抓包工具都不需要,一个个找都可以,非常简单。
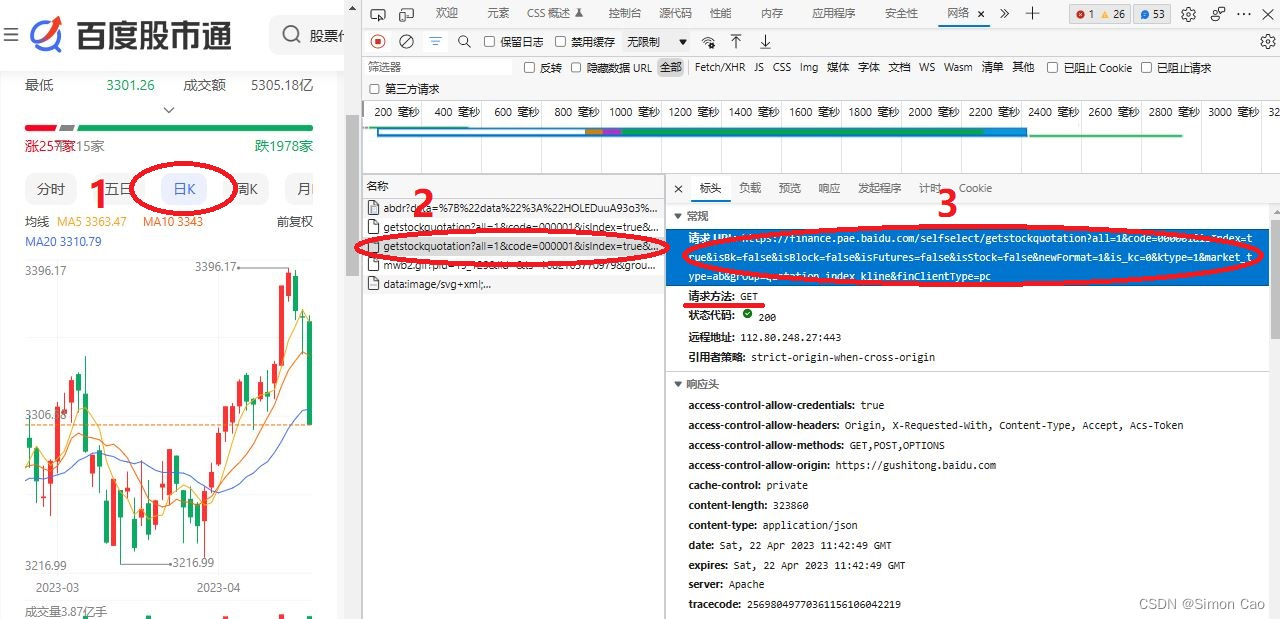
图四:获取原始数据接口(上证指数)
笔者获取到原始数据接口地址如下,get方法向服务器发送请求:
url = "https://finance.pae.baidu.com/selfselect/getstockquotation\
all=1&code=000001&isIndex=true&isBk=false&isBlock=false&isFutures=\
false&isStock=false&newFormat=1&is_kc=0&ktype=1&market_type=ab&group\
=quotation_index_kline&finClientType=pc"
re = requests.get(url)
print(re)
# <Response [200]>下面就是爬虫的基本操作,但运行后直接傻掉:
df = re.text
print(df)
# '{"QueryID":"0","ResultCode":"403","Result":[]}'request返回代码200,说明成功请求到网站数据,然后返回的内容(df)是我没有成功请求到数据(报错403)??? 这就好像是我明明吃了早餐,但肚子却告诉我我没有吃早餐,摸不着头脑。笔者又用浏览器直接访问该接口地址,的确是可以正常返回数据的,如图五:
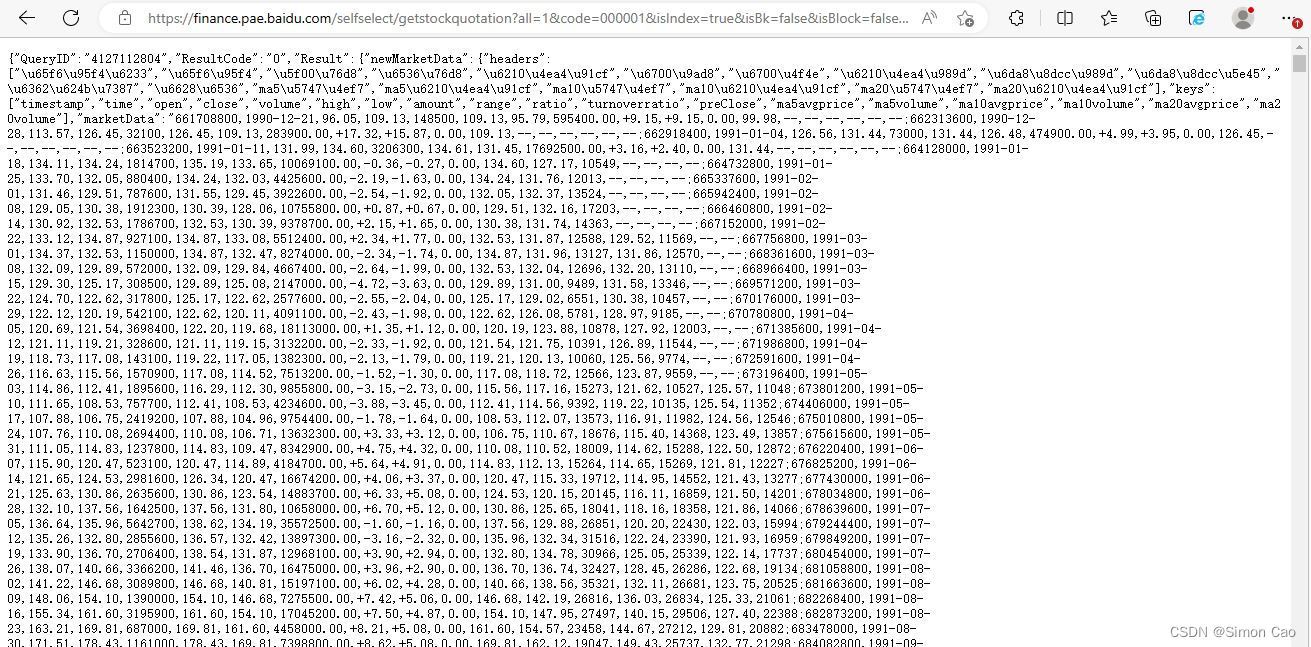
图五:使用浏览器正常访问
使用浏览器就可以成功访问,使用requests请求却返回的是错误代码,也就是说浏览器一定是有requests没有的东西,于是笔者在.get方法中加入headers模拟浏览器请求:
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/557.36 (KHTML, like Gecko) Chrome/122.1.1.1 Safari/489.37 Edg/122.0.1125.58"}
re = requests.get(url, headers=headers)
print(re.text)
# '{"QueryID":"0","ResultCode":"403","Result":[]}' 结果返回的状态码还是403。
3.1 Cookie验证
笔者又研究了一下,借鉴哔哩哔哩的爬虫程序,在headers中加入cookie信息后成功获取数据。也就是说百度股市通是需要headers模拟浏览器访问才会返回数据,如果不加任何信息只通过.get(url)则会被直接判断为爬虫程序因而禁止访问。但使用同一个headers非常频繁的请求数据还是很容易被判断为爬虫,如果有开多线程的读者最好还是多创建几个headers轮着用。
url = "https://finance.pae.baidu.com/selfselect/getstockquotation?all=1&code=000001&isIndex=true&isBk=false&isBlock=false&isFutures=false&isStock=false&newFormat=1&is_kc=0&ktype=1&market_type=ab&group=quotation_index_kline&finClientType=pc"
cookie = “cookie” # 笔者的cookie非常长,这里就不放了,可以自行添加自己浏览器的cookie
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.34",
"cookie":cookie}
re = requests.get(url, headers=headers)部分结果展示如下:
df = re.text
print(df)
{"QueryID":"4023775438","ResultCode":"0","Result":{"newMarketData":{"headers":
["\u65f6\u95f4\u6233","\u65f6\u95f4","\u5f00\u76d8","\u6536\u76d8","\u6210\u4ea4\u91cf","\u
6700\u9ad8","\u6700\u4f4e","\u6210\u4ea4\u989d","\u6da8\u8dcc\u989d","\u6da8\u8dcc\u5e45","
\u6362\u624b\u7387","\u6628\u6536","ma5\u5747\u4ef7","ma5\u6210\u4ea4\u91cf","ma10\u5747\u4
ef7","ma10\u6210\u4ea4\u91cf","ma20\u5747\u4ef7","ma20\u6210\u4ea4\u91cf"],"keys":
["timestamp","time","open","close","volume","high","low","amount","range","ratio","turnover
ratio","preClose","ma5avgprice","ma5volume","ma10avgprice","ma10volume","ma20avgprice","ma2
0volume"],"marketData":"1422547200,2015-01-30,3273.75,3210.36,25831254800,3288.50,3210.31,284265652114.00,-51.95,-1.59,0.00,3262.31,-
-,--,--,--,--,--;1422806400,2015-02-02,3148.14,3128.30,25086162900,3175.13,3122.57,266849961763.00,-82.06,-2.56,0.00,3210.36,-
-,--,--,--,--,--;1422892800,2015-02-03,3156.09,3204.91,24819216400,3207.94,3129.73,283355954757.00,+76.61,+2.45,0.00,3128.30,-
-,--,--,--,--,--;1422979200,2015-02-04,3212.82,3174.13,24909808600,3238.98,3171.14,290155154574.00,-30.78,-0.96,0.00,3204.91,-
-,--,--,--,--,--;1423065600,2015-02-
...df是个很大的字符串,包含所有上证指数从2015年以来的所有数据。下面对df进行字符串删改,然后生成结构化数据, 都是基础操作就不进行详细讲解了:
table_head = df.split('"],"marketData":"')[0]
table_head = table_head.split('"keys":["')[1].split('","')
trade_data = df.split('"],"marketData":"')[1]
trade_data = trade_data.replace('"}}}', '').replace('-', '').split(';')
data_set = []
for i in trade_data:
i = i.split(',')
data = {}
for num in range(len(i)):
data[table_head[num]] = i[num]
data_set.append(data)
data_set = pd.DataFrame(data_set)3.2 结果展示
可以看到,已经成功获取2015年至今的所有数据,包括均线数据也在里面了。
timestamp time open close volume high low amount range ratio turnoverratio preClose ma5avgprice ma5volume ma10avgprice ma10volume ma20avgprice ma20volume
0 1422547200 20150130 3273.75 3210.36 25831254800 3288.50 3210.31 284265652114.00 51.95 1.59 0.00 3262.31
1 1422806400 20150202 3148.14 3128.30 25086162900 3175.13 3122.57 266849961763.00 82.06 2.56 0.00 3210.36
2 1422892800 20150203 3156.09 3204.91 24819216400 3207.94 3129.73 283355954757.00 +76.61 +2.45 0.00 3128.30
3 1422979200 20150204 3212.82 3174.13 24909808600 3238.98 3171.14 290155154574.00 30.78 0.96 0.00 3204.91
4 1423065600 20150205 3251.21 3136.53 30613930500 3251.21 3135.82 348266954936.00 37.60 1.18 0.00 3174.13 3170.85 262520746
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
1996 1681660800 20230417 3337.06 3385.61 40280992600 3385.61 3336.39 523790271022.00 +47.46 +1.42 0.95 3338.15 3336.57 350512535 3324.75 344711859 3291.35 328843768
1997 1681747200 20230418 3379.23 3393.33 34839948600 3396.17 3375.78 474287388944.00 +7.72 +0.23 0.82 3385.61 3352.53 356079222 3334.44 343784130 3299.27 326637873
1998 1681833600 20230419 3391.35 3370.13 34612344300 3394.96 3364.64 476496941017.00 23.20 0.68 0.82 3393.33 3361.12 356698847 3340.20 339809312 3305.00 328853506
1999 1681920000 20230420 3367.05 3367.03 35035496500 3371.37 3344.02 499672394215.00 3.10 0.09 0.83 3370.13 3370.85 357197419 3345.64 342129266 3310.06 331829231
2000 1682006400 20230421 3364.00 3301.26 38739509800 3367.61 3301.26 530517857771.00 65.77 1.95 0.92 3367.03 3363.47 367016584 3343.00 352565551 3310.79 335893066
2001 rows × 18 columns简单输出一下图表:
data_set["close"].astype("float").plot()
图六:上证历史走势
不知道为什么百度股市通的数据竟然只追溯到2015年,不过笔者之前写过一个可以获取上证从1990年以来所有历史数据的爬虫,笔者上传到资源里了:上证指数日线数据获取程序。
4. 防盗链验证爬取
目标网址如下:广发制造业精选混合A(270028)基金阶段涨幅。和刚才百度股市通的一样,网址打开后再按F12,在网络中监控浏览器所请求的网址。按图四的步骤,找到URL。有意思的是东方财富生成的请求只有一个,这连一个个找都不需要,简单到令人发指。
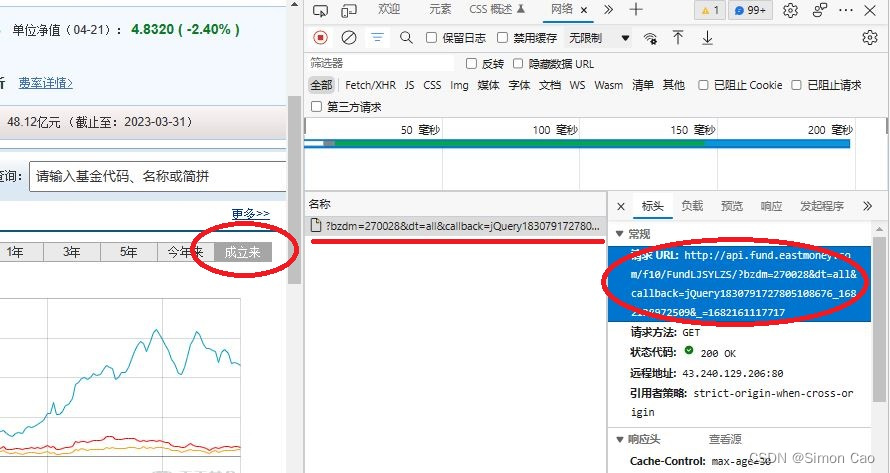
图七:获取原始数据接口
东方财富网上的基金数据是带有防盗链验证的,处理的方式也很简单。和刚刚的爬虫程序一样,只是需要找到referer信息(如图七,一般在host下面)。然后在headers里添加referer信息进行验证。
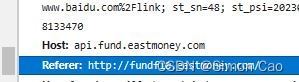
图八:东方财富referer信息
部分爬取结果如下:
url = "http://api.fund.eastmoney.com/f10/FundLJSYLZS/?bzdm=270028&dt=all&callback=jQuery183011566570559716083_1682162295762&_=1682162300938"
headers = {"Referer": "http://fundf10.eastmoney.com/"}
re = requests.get(url, headers = headers)
df = re.text
print(df)
'jQuery183011566570559716083_1682162295762({"Data":"2011/09/20_0.00_0.00_0.00|2011/11/24_-0
.10_-3.75_-2.05|2011/12/13_-2.30_-9.96_-8.14|2011/12/30_-3.00_-12.79_-10.15|2012/01/19_-4.6
0_-8.23_-6.20|2012/02/14_-3.10_-6.24_-4.21|2012/03/02_1.20_-0.37_0.53|2012/03/21_-1.20_-3.7
9_-2.84|2012/04/11_-2.80_-6.31_-5.67|2012/05/02_0.00_-0.24_-0.38|2012/05/21_-1.60_-3.81_-4.
06|2012/06/07_0.60_-5.49_-6.32|2012/06/27_2.40_-9.02_-9.43|2012/07/13_5.30_-8.89_-10.70
...接下来又是字符串操作,就不进行详细说明了。
trade_data = df.split('{"Data":"')[1].split('","ErrCode"')[0].split('|')
data_set = []
for i in trade_data:
i = i.split('_')
data = {"date": i[0], # 日期
"fund_performance": i[1], # 基金业绩
"hs_300": i[2], # 沪深300
"Shanghai_index": i[3] # 上证
}
data_set.append(data)
data_set = pd.DataFrame(data_set)运行结果如下:
print(data_set)
date fund_performance hs_300 Shanghai_index
0 20110920 0.00 0.00 0.00
1 20111124 -0.10 -3.75 -2.05
2 20111213 -2.30 -9.96 -8.14
3 20111230 -3.00 -12.79 -10.15
4 20120119 -4.60 -8.23 -6.20
... ... ... ... ...
212 20230223 522.00 52.56 34.31
213 20230314 473.88 48.14 32.58
214 20230331 474.57 50.60 33.71
215 20230420 474.11 52.91 37.56
216 20230421 460.31 49.92 34.87
217 rows × 4 columns可视化输出:
import matplotlib.pyplot as plt
plt.figure(figsize=(8,4))
plt.plot(data_set["date"], data_set["fund_performance"], color="blue", label="fund_performance")
plt.plot(data_set["date"], data_set["hs_300"], color="red", label="HS_300")
plt.plot(data_set["date"], data_set["Shanghai_index"], color="orange", label="Shanghai_index")
plt.xticks(data_set["date"][::50])
plt.xlabel("date")
plt.ylabel("pct_chg(%)")
plt.legend()
plt.show()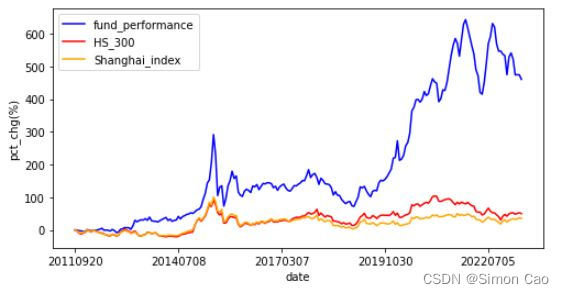
图九:基金(270028)业绩业绩
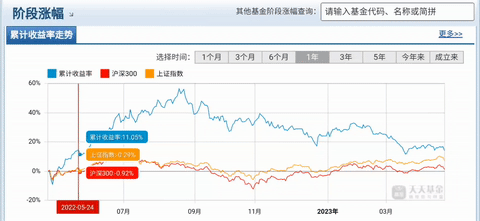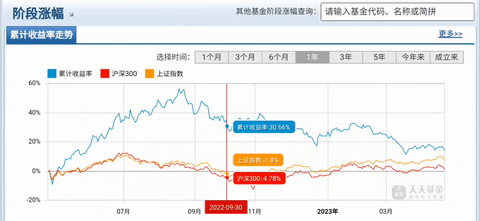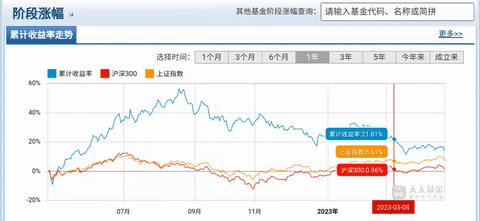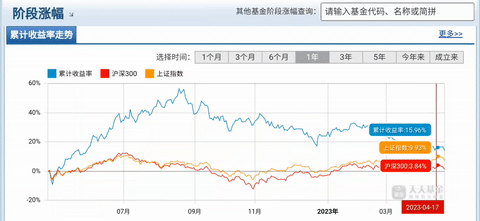
结果与网站的图表进行对比:
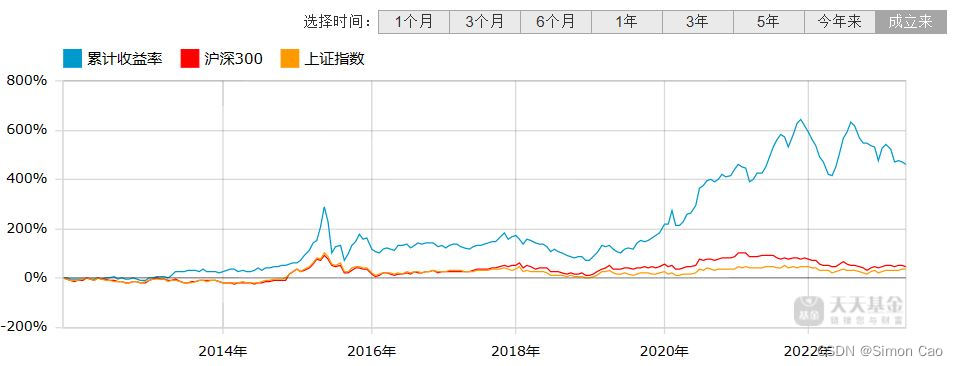
图十:东方财富网站的原始图表
5. 总结
本期对网站上交互式图表背后的结构化数据进行爬取,主要讨论了获取原理,爬取思路。最后以百度股市通及东方财富为例,对交互式图表数据进行了爬取。所谓工欲善其事必先利其器,掌握获取这些原始数据的方法和能力将极大的方便后续工作开展。