一、论文简述
1. 第一作者:Jinli Liao、Yikang Ding
2. 发表年份:2023
3. 发表期刊:arxiv
4. 关键词:MVS、3D重建、Transformer、极线、几何约束
5. 探索动机:然而,在没有极几何约束的情况下匹配参考图像和源图像中的每个像素会导致匹配冗余。最近一项沿着源图像的极线(MVS2D)进行基于注意力的匹配的努力,受到相机姿势和校准不准确的敏感性的影响,从而导致错误的匹配。虽然学习的MVS方法旨在从多视图特征一致性中估计深度假设的似然,但它们在没有几何一致性监督的情况下计算地面真值与预测深度期望之间的绝对误差。
1. However, matching each pixel in reference and source images without epipolar geometry constraints incurs matching redundancy. A recent effort to perform attention-based matching along the epipolar lines of source images(MVS2D), suffers instead from sensitivity to inaccurate camera pose and calibration, which can in turn results to erroneous matching.
2. While learned MVS methods aim to estimate the likelihood of depth hypotheses from multi-view feature consistency, they calculate the absolute error between ground truth and predicted depth expectation without geometrical consistency supervision.
6. 工作目标:解决上述问题。
7. 核心思想:The proposed MVSTR takes full advantages of Transformer to enable features to be extracted under the guidance of global context and 3D geometry, which brings significant improvement on reconstruction results.
- We introduce a Window-based Epipolar Transformer (WET) for enhancing patch-to-patch matching between the reference feature and corresponding windows near epipolar lines in source features.
- We propose a window-based Cost Transformer (CT) to better aggregate global information within the cost volume and improve smoothness.
- We design a novel geometric consistency loss (Geo Loss) to supervise the estimated depth map with geometric multi-view consistency.
8. 实验结果:
Extensive experiments show that our method achieves state-of-the-art performance on
multiple datasets. It ranks 1st on the online Tanks and Temples benchmark
9.论文下载:
https://arxiv.org/pdf/2112.00336.pdf
二、实现过程
1. WT-MVSNet概述
总体架构如下图。给定参考图像I0,源图像Ii,对应的相机外部矩阵Ti,相机内部矩阵Ki,深度范围[dmin, dmax]。基于CasMVSNet,第一步即通过特征金字塔网络(Feature Pyramid Network, FPN)提取1/4、1/2和全图像分辨率下的多尺度特征Fi。为了加强多视图图像内部和跨视图的全局特征交互,提出了一种基于窗口的的极线转换器(WET),对提取的特征进行内部注意力和跨注意力交替进行。然后将转换后的源特征warp到参考视图,用于构建H×W×C×D的3D代价体V,其中D为候选深度。然后,用提出的代价转换器(CT)对V进行正则化,生成H×W×D的概率体P,该概率体P聚合了全局代价信息,用于生成估计深度。最后,利用交叉熵损失(CE loss)来监督概率体,并提出了几何一致性损失(Geo loss)来对几何一致性不满足的区域进行惩罚。
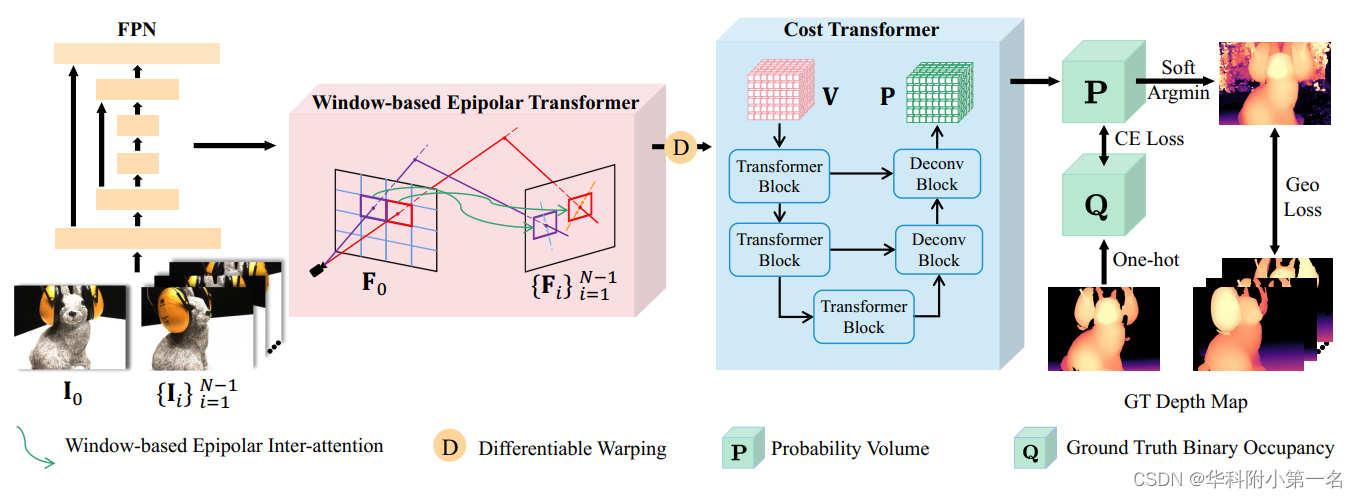
2. 基于窗口的极线Transformer
现有基于学习的MVS方法大多直接通过warp提取的特征来构建代价体,导致缺乏全局上下文信息,并且点对线匹配对于错误相机校准很敏感。为了解决这个问题,引入了一个基于窗口的极线Transformer(WET),它通过使用极线约束来减少匹配冗余,并在极线窗口附近匹配。
2.1. 初步准备
注意力机制。Swin Transformer提出了一种计算复杂度仅为线性的分层特征表示。Swin Transformer块包含基于窗口的多头自注意力(W-MSA)和可移动的基于窗口的多头自注意力(SW-MSA),可以表示为:
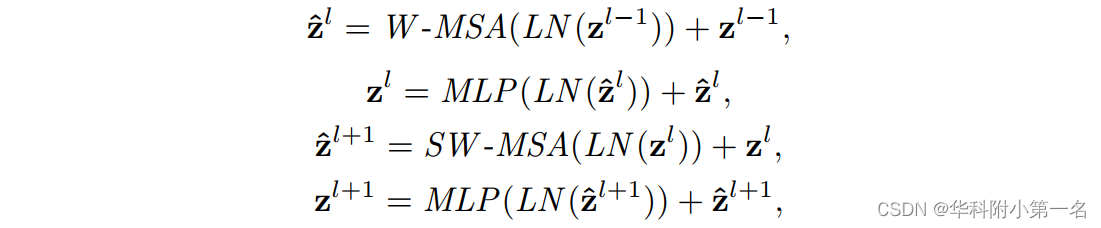
其中LN和MLP表示LayerNorm和Multilayer Perception。^zl和zl是第l块的(S)W -MSA和的MLP的输出。Swin Transformer将特征分为不重叠的窗口和组,作为查询Q、键K和值v,通过每个v对应的Q和K的点积计算提取的特征的相似度,定义为:
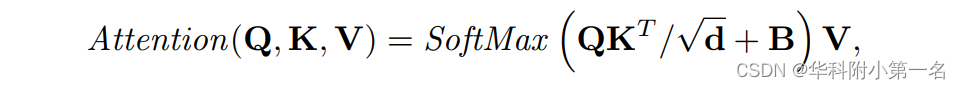
其中d表示查询和键的维度。B是相对位置偏差。
内部注意力和跨注意力。当Q和K从同一特征图中提取时,注意力层会获得给定特征图中的相关信息。相反,当Q和K取自不同的特征图时,注意力层会增强不同视图之间的上下文交互。
2.2. 基于窗口的极线跨注意力
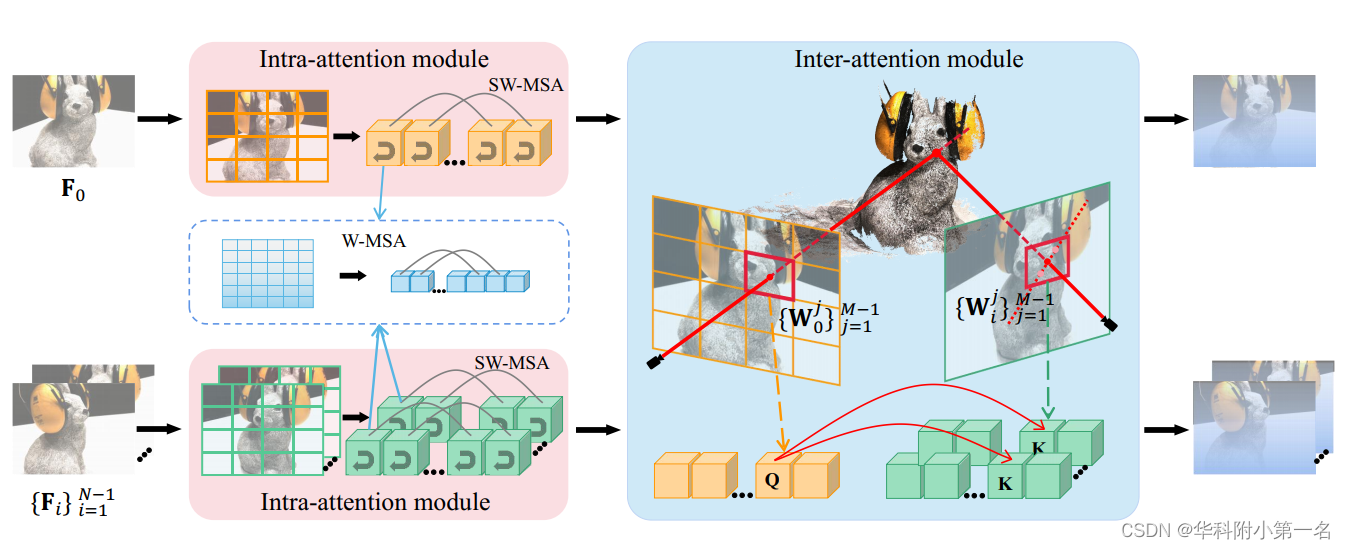
遵循TransMVS- Net,在F0和每个Fi之间进行相互注意力,只更新Fi。具体来说,计算F0和每个Fi相应沿极线的块像素之间的跨注意力。第一步,将F0划分为M个大小相同的不重叠窗口W0,具有同样大小的hwin×Wwin,通过可微单应性变化将W0j的中心点pj变化到Fi。第i个源视图变化后的中心点是pij。为了实现跨注意力,在每个pji周围用相同大小hwin×Wwin划分一个窗口Wij,源特征中pji的极线经过这个窗口。因此,跨注意力能够加强参考特征窗口与源特征极线附近窗口之间的长距离的全局上下文信息交互。
2.3. WET结构
WET的体系结构如下图。WET主要由内部注意力和跨注意力模块组成。在内部注意力模块中,提取的特征Fi被划分为不重叠的窗口。将每个窗口展平,并依次将其输入至W-MSA和SW-MSA。由于只在每个划分的窗口中执行内部注意力,W-MSA无法捕获整个输入特征的全局上下文。为了解决这一问题,利用SW-MSA和移位窗口划分策略来增强不同窗口之间的信息交互,获得全局上下文。为了减少匹配冗余,并避免错误的相机位姿和校准,在参考和源视图之间执行基于窗口的极线跨注意力。在跨注意力模块中,将F0划分成非重叠窗口,并将每个中心点warp,以在源特征中划分相应的窗口。将划分的窗口展平后,计算F0中每个窗口和每个Fi中对应的窗口之间的跨注意力, 来变换和更新Fi。
3. 代价Transformer
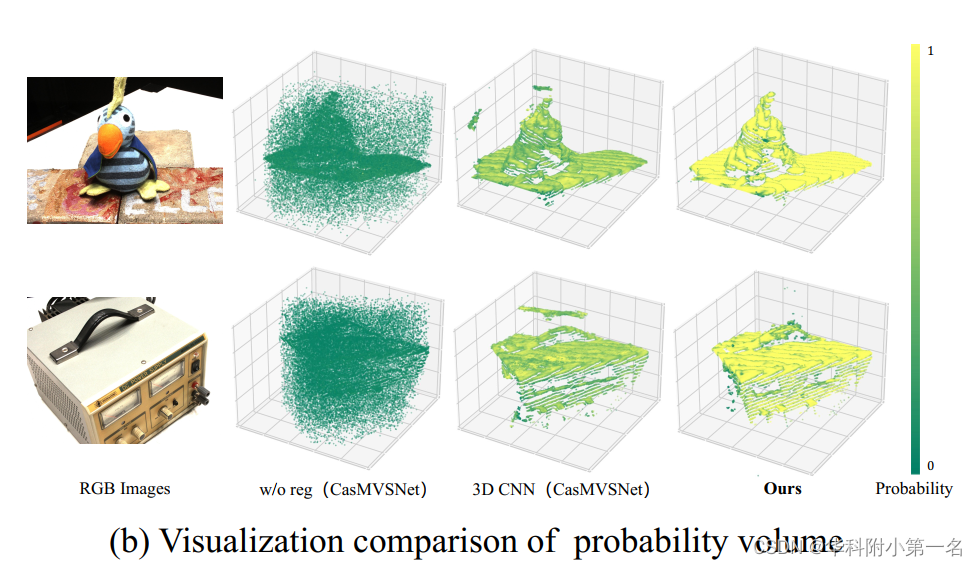
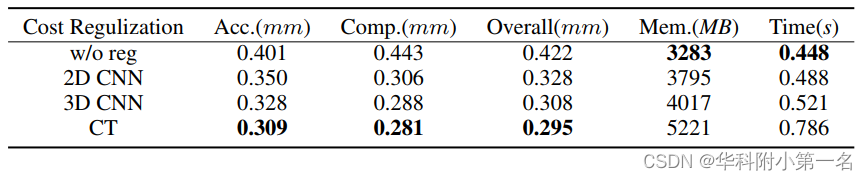
作者进一步探讨了不同正则化的影响,并发现全局感受野对最终性能有显著影响,提出了一种新的基于窗口的代价Transformer(CT)来聚合代价体内的全局信息。如下图所示,随着感受野的扩展,深度维上概率最高的概率体素变得更平滑、更完整,置信度也更高(黄色区域表示更高的概率,相当于更高的置信度)。与3D CNN和非正则化相比,CT生成的概率体具有更高的质量。
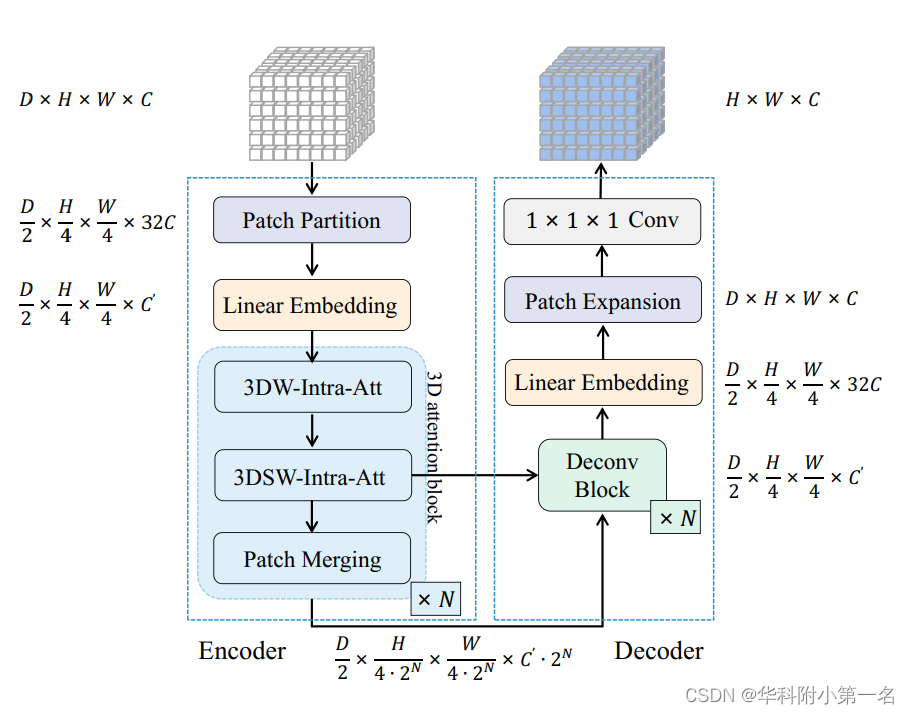
3D 注意力。为了在代价体正则化中利用全局感受野,将W-MSA和SW-MSA扩展到3D,为此在空间和深度维度上将3D体flatten。后续操作类似于2D注意力。
CT结构。如下图所示,包括编码器、解码器和跳跃连接。给定一个输入代价体V,编码器首先将V分为非重叠的3D块,每个3D块从2×4×4×C展平为32C。此外,采用线性嵌入层将通道维度32C投影到C`中,产生嵌入后的代价体V`。之后,进一步将V`划分为不重叠的3D窗口,并将每个3D窗口从dwin×hwin×wwin×C`平展到dwinwinwin×C`。然后将平展后的窗口输入至N个3D注意力块中,每个注意力块由3DW-Intra-Att、3DSW-Intra-Att和块合并层组成。和块合并层负责空间下采样和通道维数的增加。在解码器中,利用反卷积来恢复分辨率。为了减少和块合并层产生的空间信息的丢失,将浅层特征和深层特征连接在一起,即通过跳跃连接将编码器和解码器的多尺度特征融合在一起。再加上线性嵌入层和补丁扩展层,变换后的V`与V维度保持一致。最后,利用具有1×1×1核的三维卷积,得到最终的概率体P。
4. 损失函数
几何一致性损失。一般情况下,深度估计只在参考视图中进行监督,而不使用多视图一致性,在推理阶段通常使用多视图一致性来过滤离群值。本文将多视角一致性运用到训练阶段,并提出了一种新的几何一致性损失(Geo loss)来对几何一致性不符合的区域进行惩罚。首先,对参考视图的估计深度图D0中的每个像素p进行warp,得到相邻源视图中对应的像素p`i。其中D0(p)表示像素p的深度值。反过来,我们对p`i进行反向投影进入三维空间,然后将其重投影到参考视图p``:
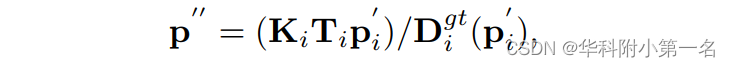
式中Dgt i(p`i)表示p`i的真实深度值。定义两个重投影误差为:
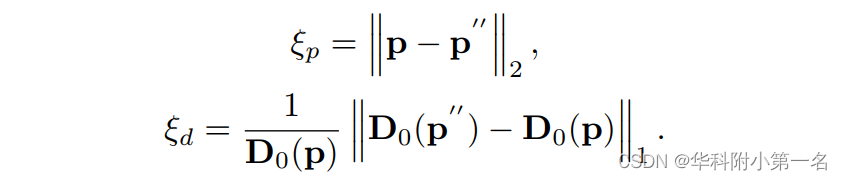
因此,最终的Geo Loss LGeo可以写成:
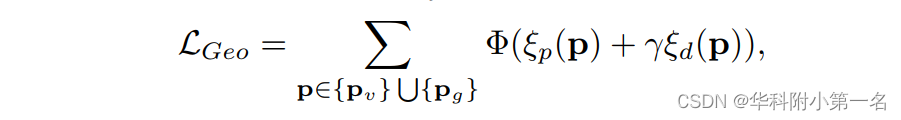
其中Φ为Sigmoid函数,用于对带有超参数γ的组合重投影误差进行归一化。pv表示由有效掩码图获得的一组有效空间坐标,pg是重投影误差在给定阈值内的所有像素的集合,例如:ξp < τ1和
ξd < τ2,其中τ1和τ2为超参数,随级数的增加而减小。
总损失。综上所述,损失函数由交叉熵损失(cross entropy loss, CE loss)和Geo loss组成:
 5. 实验
5. 实验
5.1. 实现细节
基于Pytorch实现,在DTU训练集上训练。与CasMVSNet的1/4、1/2和全图像分辨率3个阶段相似,对应的深度间隔从阶段1到阶段3分别衰减0.25和0.5,每个阶段的深度假设为48个、32个和8个。在DTU上进行训练时,设置图像个数为N = 5,图像分辨率为512×640。使用Adam进行了16个epoch的训练,学习率为0.001,分别在6、8、12个epoch后衰减0.5倍。设组合系数γ = 100.0,损失权重λ1 = 2.0和λ2 = 1.0,重投影误差在3个分辨率阈值τ1为3.0、2.0、1.0,τ2为0.1,0.05,0.01。在8个Tesla V100 GPU上将批大小设置为1来训练模型,通常需要15个小时,占用每个GPU的13GB内存。
5.2. 与先进技术的比较
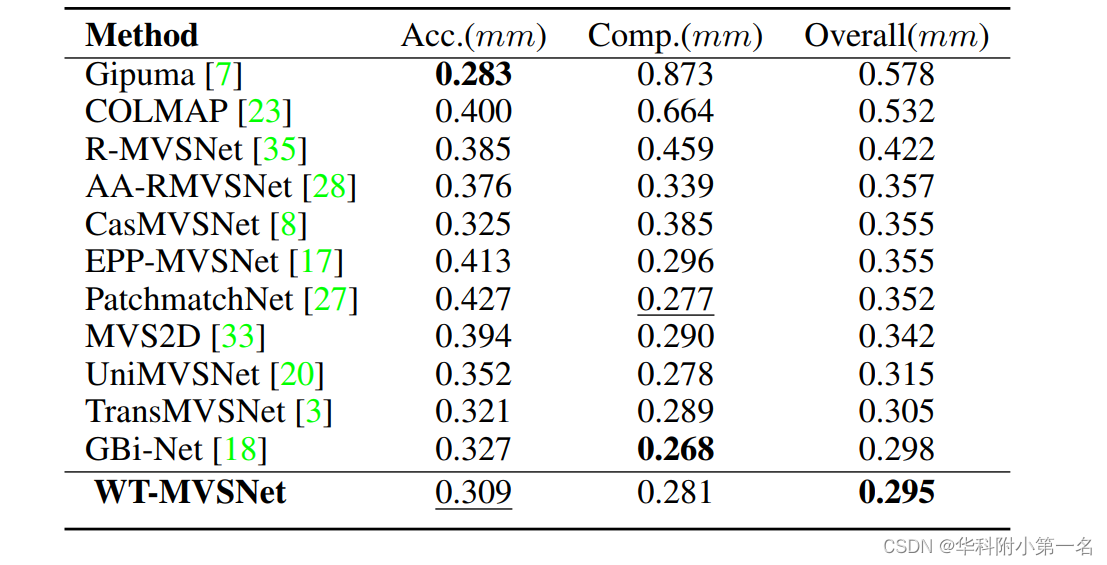
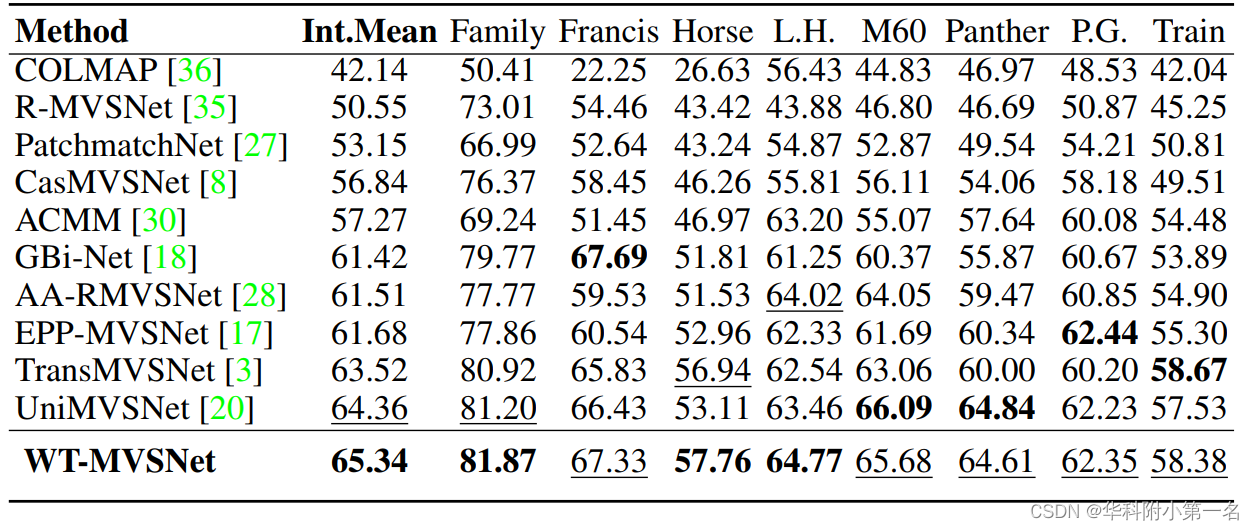

5.3. 限制
在跨注意力模块中,固定地从参考特征中选warp后的点,不考虑中心点的重要性。此外,Transformer的引入不可避免地会在训练阶段产生较高的内存成本,并降低推理速度。