目录
1. logistic(逻辑斯蒂)函数
2.二分类任务(binary classification)损失函数
3.二分类任务(binary classification)最小批量损失函数
4.逻辑斯蒂回归代码实现
附:pytorch提供的数据集
推荐课程:06.逻辑斯蒂回归_哔哩哔哩_bilibili
回归是对连续变量预测。
分类是对离散变量预测。通过比较分类的概率来判断预测的结果。
回归&分类
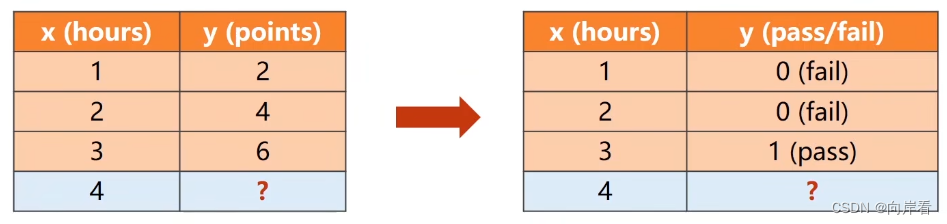
以学生学习为例,回归任务:学习时间预测学习成绩,分类任务:学习时间预测通过考试的概率,两个类别标签,通过与不通过,这是一个二分类任务。
逻辑斯蒂回归是一种分类任务。
1. logistic(逻辑斯蒂)函数
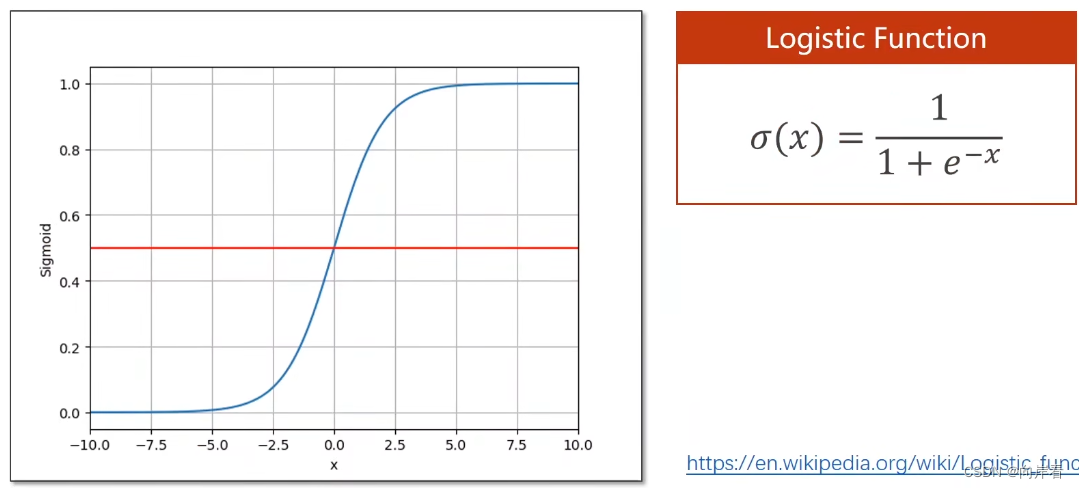
这里的x更换为。
适用于线性模型将输出值由实数空间映射到[0,1]之间,以此进行分类。与线性回归模型相比logistic(逻辑斯蒂)回归模型,多增加了一个映射函数。
映射:
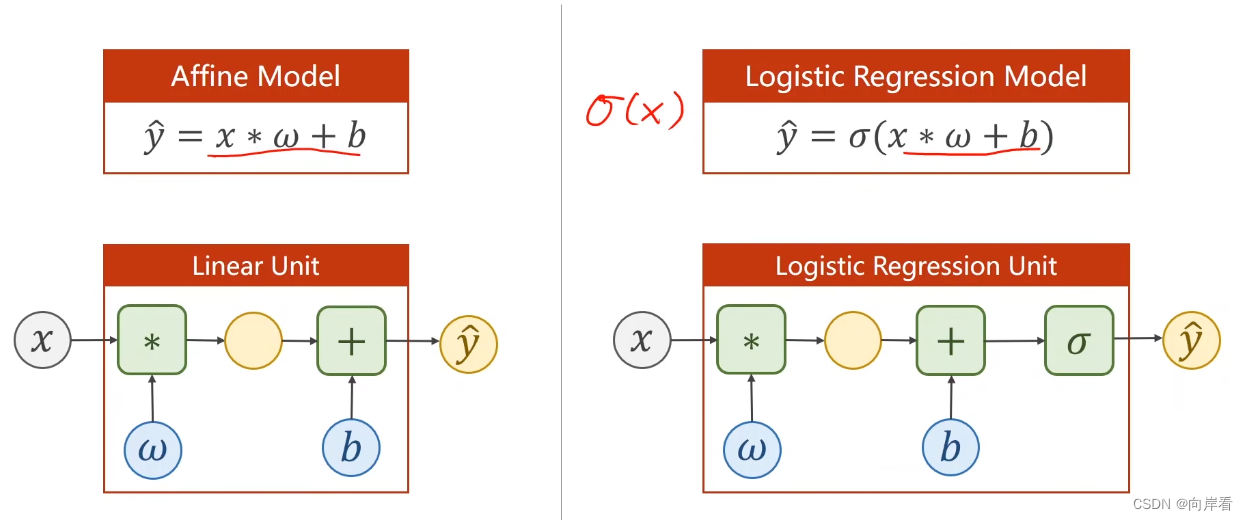
注:只要满足饱和函数的规定,都属于sigmoid函数,如logistic(逻辑斯蒂)函数。所以logistic回归有时也叫sigmoid。
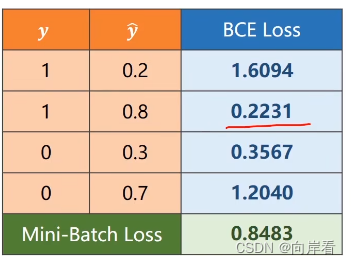
2.二分类任务(binary classification)损失函数
也称为BCELoss()函数,二分类交叉熵(cross entorpy)

在二分类任务中,为class=1的概率, 1-
为class=0的概率。
为交叉熵表示log前后两个分布概率的差异大小。如果y=0表示class=0的概率为1,class=1的概率为0。如果y=1表示class=1的概率为1,class=0的概率为0。
当y=1时,loss=-log,表示
值越大越接近class=1的概率为1的真实分布概率,损失值越小。当y=0时, loss=-log(1 -
), 表示
值越小,class=0的概率越大,越接近class=0的概率为1的真实分布概率,损失值越小。可见下图。
3.二分类任务(binary classification)最小批量损失函数
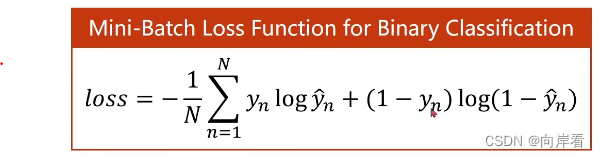
求损失量均值。
4.逻辑斯蒂回归代码实现
1.数据准备
2.设计模型
3.构造损失函数和优化器
4.训练周期(前馈—>反馈—>更新)
逻辑斯蒂回归完整代码:
import torch
import torch.nn.functional as F
#…1.准备数据………………………………………………………………………………………………………………………………………#
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
# 二分类
y_data = torch.Tensor([[0], [0], [1]])
#…2.设计模型………………………………………………………………………………………………………………………………………#
# 继承torch.nn.Module,定义自己的计算模块,neural network
class LogisticRegressionModel(torch.nn.Module):
# 构造函数
def __init__(self):
# 调用父类构造
super(LogisticRegressionModel, self).__init__()
# 定义输入样本和输出样本的维度
self.linear = torch.nn.Linear(1, 1)
# 前馈函数
def forward(self, x):
# 返回x线性计算后的预测值
# sigmoid()作映射变化
y_pred = F.sigmoid(self.linear(x))
return y_pred
#……3.构造损失函数和优化器……………………………………………………………………………………………………………#
# 实例化自定义模型,返回做logistic变化(也叫sigmoid)的预测值
model = LogisticRegressionModel()
# 实例化损失函数,返回损失值
criterion = torch.nn.BCELoss(size_average=False)
# 实例化优化器,优化权重w
# model.parameters(),取出模型中的参数
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
#……4.训练周期………………………………………………………………………………………………………………………………………#
for epoch in range(1000):
# 获得预测值
y_pred = model(x_data)
# 获得损失值
loss = criterion(y_pred, y_data)
# 不会产生计算图,因为__str()__
print(epoch, loss.item())
# 梯度归零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 更新权重w
optimizer.step()
# 打印权重和偏值
print('w = ', model.linear.weight.item())
print('b = ', model.linear.bias.item())
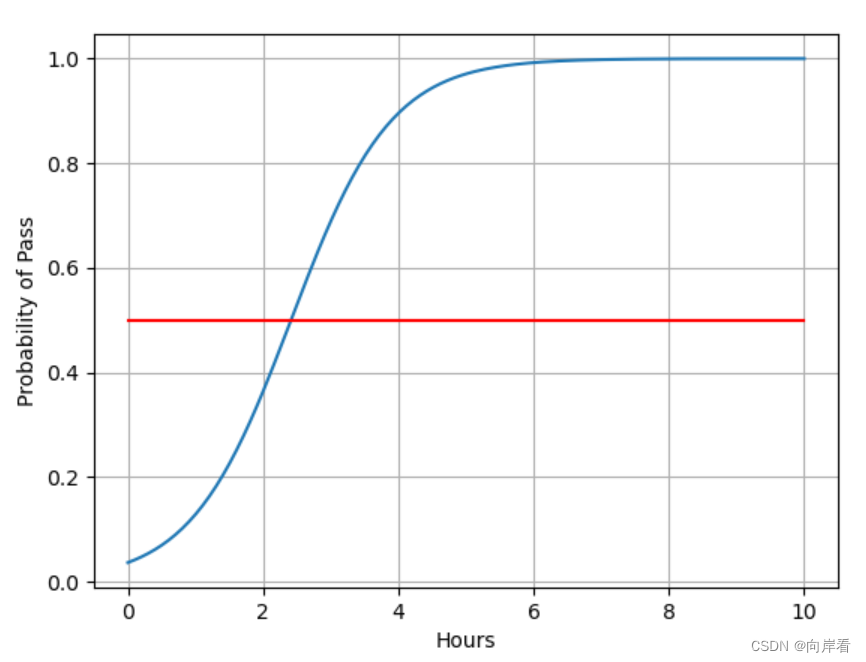
#……5.绘图………………………………………………………………………………………………………………………………………#
#用于在大型、多维数组上执行数值运算
import numpy as np
import matplotlib.pyplot as plt
# 定义均匀间隔创建数值序列,指定间隔起始点、终止端,指定分隔值总数
x = np.linspace(0, 10, 200)
# 重新调整维度为200*1
x_t = torch.Tensor(x).view((200, 1))
y_t = model(x_t)
# 将tensor转化为numpy类型
y = y_t.data.numpy()
# 图线1,x,y 轴上的数值
plt.plot(x, y)
# 图线2,x,y 轴上的数值,设置颜色
plt.plot([0, 10], [0.5, 0.5], c='r')
plt.xlabel('Hours')
plt.ylabel('Probability of Pass')
# 绘制刻度线的网格线
plt.grid()
plt.show()
附:pytorch提供的数据集
pytorch的免费数据集由两个上层的API提供,分别是torchvision和torchtext。
torchvision提供了对照片数据处理相关的API和数据,数据所在位置:torchvision.datasets,比如torchvision.datasets.MNIST(手写数字照片数据),torchvision.datasets.cifar(十类彩色图像数据)。
torchtext提供了对文本数据处理相关的API和数据,数据所在位置:torchtext.datasets,比如torchtext.datasets.IMDB(电影评论文本数据)。
import torchvision
# 训练集
train_set = torchvision.datasets.MNIST(root="../dataset/mnist", train=True, download=True)
# 测试集
test_set = torchvision.datasets.MNIST(root="../dataset/mnist", train=False, download=True)
- root(string)– 数据集的根目录,其中存放
processed/training.pt和processed/test.pt文件。- train(bool, 可选)– 如果设置为True,从
training.pt创建数据集,否则从test.pt创建。- download(bool, 可选)– 如果设置为True, 从互联网下载数据并放到root文件夹下。如果root目录下已经存在数据,不会再次下载。
- transform(可被调用 , 可选)– 一种函数或变换,输入PIL图片,返回变换之后的数据。如:
transforms.RandomCrop。- target_transform (可被调用 , 可选)– 一种函数或变换,输入目标,进行变换。
torchvision.datasets-PyTorch 1.0 中文文档 & 教程