第11章_数据处理之增删改
讲师:尚硅谷
-
宋红康(江湖人称:康师傅)
官网:
http://www.atguigu.com
1. 插入数据
1.1 实际问题
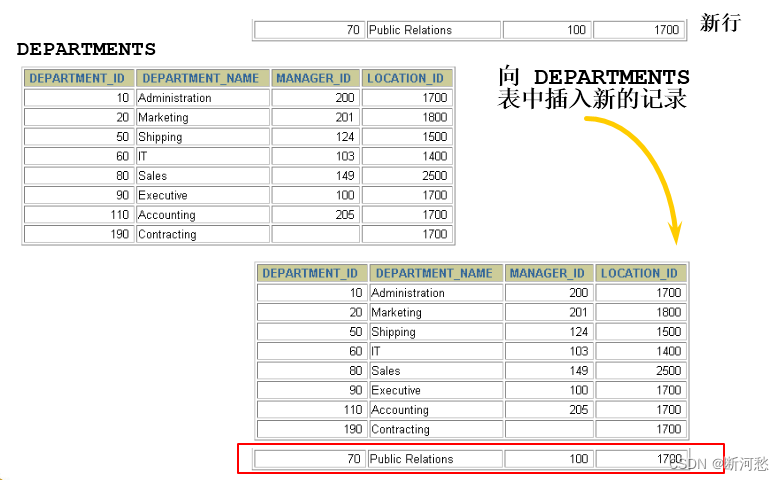
解决方式:使用
INSERT
语句向表中插入数据。
1.2 方式1:VALUES的方式添加
使用这种语法一次只能向表中插入
一条
数据。
情况
1
:为表的所有字段按默认顺序插入数据
INSERT INTO 表名VALUES (value1,value2,....);
值列表中需要为表的每一个字段指定值,并且值的顺序必须和数据表中字段定义时的顺序相同。
举例:
INSERT INTO departmentsVALUES ( 70 , 'Pub' , 100 , 1700 );
INSERT INTO departmentsVALUES ( 100 , 'Finance' , NULL , NULL );
情况
2
:为表的指定字段插入数据
INSERT INTO 表名 (column1 [, column2, …, columnn])VALUES (value1 [,value2, …, valuen]);
为表的指定字段插入数据,就是在
INSERT
语句中只向部分字段中插入值,而其他字段的值为表定义时的默认值。
在
INSERT
子句中随意列出列名,但是一旦列出,
VALUES
中要插入的
value1,....valuen
需要与
column1,...columnn
列一一对应。如果类型不同,将无法插入,并且
MySQL
会产生错误。
举例:
INSERT INTO departments(department_id, department_name)VALUES ( 80 , 'IT' );
情况
3
:同时插入多条记录
INSERT
语句可以同时向数据表中插入多条记录,插入时指定多个值列表,每个值列表之间用逗号分隔开,基本语法格式如下:
INSERT INTO table_nameVALUES(value1 [,value2, …, valuen]),(value1 [,value2, …, valuen]),……(value1 [,value2, …, valuen]);
或者
INSERT INTO table_name (column1 [, column2, …, columnn])VALUES(value1 [,value2, …, valuen]),(value1 [,value2, …, valuen]),……(value1 [,value2, …, valuen]);
举例:
mysql> INSERT INTO emp(emp_id,emp_name)-> VALUES ( 1001 , 'shkstart' ),-> ( 1002 , 'atguigu' ),-> ( 1003 , 'Tom' );Query OK, 3 rows affected ( 0.00 sec)Records: 3 Duplicates: 0 Warnings : 0
使用
INSERT
同时插入多条记录时,
MySQL
会返回一些在执行单行插入时没有的额外信息,这些信息的含义如下: ● Records
:表明插入的记录条数。 ●
Duplicates
:表明插入时被忽略的记录,原因可能是这些记录包含了重复的主键值。 ● Warnings
:表明有问题的数据值,例如发生数据类型转换。
一个同时插入多行记录的 INSERT 语句等同于多个单行插入的 INSERT 语句,但是多行的 INSERT 语句在处理过程中 效率更高 。因为 MySQL 执行单条 INSERT 语句插入多行数据比使用多条 INSERT 语句快,所以在插入多条记录时最好选择使用单条INSERT 语句的方式插入。
小结:
- VALUES 也可以写成 VALUE ,但是VALUES是标准写法。
- 字符和日期型数据应包含在单引号中。
1.3 方式2:将查询结果插入到表中
INSERT
还可以将
SELECT
语句查询的结果插入到表中,此时不需要把每一条记录的值一个一个输入,只需要使用一条INSERT
语句和一条
SELECT
语句组成的组合语句即可快速地从一个或多个表中向一个表中插入多行。
基本语法格式如下:
INSERT INTO 目标表名(tar_column1 [, tar_column2, …, tar_columnn])SELECT(src_column1 [, src_column2, …, src_columnn])FROM 源表名[ WHERE condition ]
- 在 INSERT 语句中加入子查询。
- 不必书写 VALUES 子句。
- 子查询中的值列表应与 INSERT 子句中的列名对应。
举例:
INSERT INTO emp2SELECT *FROM employeesWHERE department_id = 90 ;
INSERT INTO sales_reps(id, name, salary, commission_pct)SELECT employee_id, last_name, salary, commission_pctFROM employeesWHERE job_id LIKE '%REP%' ;
2. 更新数据
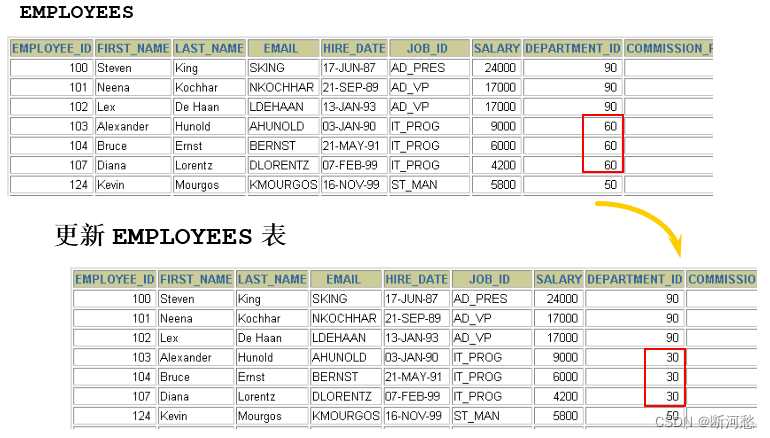
- 使用 UPDATE 语句更新数据。语法如下:
UPDATE table_nameSET column1=value1, column2=value2, … , column=valuen[WHERE condition]
- 可以一次更新多条数据。
- 如果需要回滚数据,需要保证在DML前,进行设置:SET AUTOCOMMIT = FALSE;
- 使用 WHERE 子句指定需要更新的数据。
UPDATE employeesSET department_id = 70WHERE employee_id = 113 ;
- 如果省略 WHERE 子句,则表中的所有数据都将被更新。
UPDATE copy_empSET department_id = 110 ;
- 更新中的数据完整性错误
UPDATE employeesSET department_id = 55WHERE department_id = 110 ;
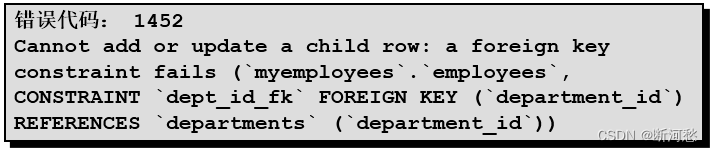
说明:不存在 55 号部门
3. 删除数据
- 使用 DELETE 语句从表中删除数据

DELETE FROM table_name [WHERE <condition>];
table_name
指定要执行删除操作的表;
“[WHERE ]”
为可选参数,指定删除条件,如果没有
WHERE
子句,DELETE语句将删除表中的所有记录。
- 使用 WHERE 子句删除指定的记录。
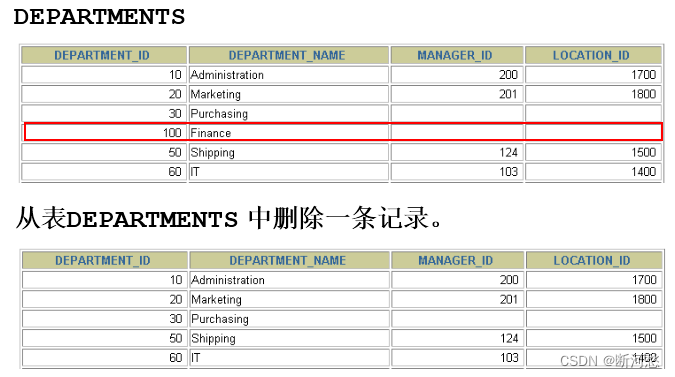
DELETE FROM departmentsWHERE department_name = 'Finance' ;
- 如果省略 WHERE 子句,则表中的全部数据将被删除
DELETE FROM copy_emp;
- 删除中的数据完整性错误
DELETE FROM departmentsWHERE department_id = 60 ;
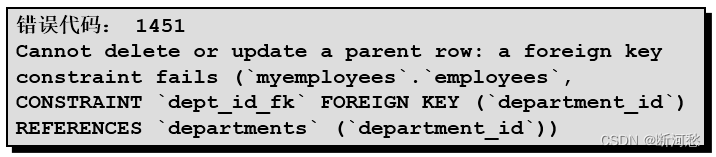
说明: You cannot delete a row that contains a primary key that is used as a foreign key in another table.
4. MySQL8新特性:计算列
什么叫计算列呢?简单来说就是某一列的值是通过别的列计算得来的。例如,
a
列值为
1
、
b
列值为
2
,
c
列不需要手动插入,定义a+b
的结果为
c
的值,那么
c
就是计算列,是通过别的列计算得来的。
在
MySQL 8.0
中,
CREATE TABLE
和
ALTER TABLE
中都支持增加计算列。下面以
CREATE TABLE
为例进行讲解。
举例:定义数据表
tb1
,然后定义字段
id
、字段
a
、字段
b
和字段
c
,其中字段
c
为计算列,用于计算
a+b
的值。 首先创建测试表tb1
,语句如下:
CREATE TABLE tb1(id INT ,a INT ,b INT ,c INT GENERATED ALWAYS AS (a + b) VIRTUAL);
插入演示数据,语句如下:
INSERT INTO tb1(a,b) VALUES ( 100 , 200 );
查询数据表tb1中的数据,结果如下:
mysql> SELECT * FROM tb1;+------+------+------+------+| id | a | b | c |+------+------+------+------+| NULL | 100 | 200 | 300 |+------+------+------+------+1 row in set ( 0.00 sec)
mysql> UPDATE tb1 SET a = 500 ;Query OK, 0 rows affected ( 0.00 sec)Rows matched: 1 Changed : 0 Warnings : 0
5. 综合案例
# 1 、创建数据库 test01_library# 2 、创建表 books ,表结构如下:
|
字段名
|
字段说明
|
数据类型
|
|
id
|
书编号
|
INT
|
|
name
|
书名
|
VARCHAR(50)
|
|
authors
|
作者
|
VARCHAR(100)
|
|
price
|
价格
|
FLOAT
|
|
pubdate
|
出版日期
|
YEAR
|
|
note
|
说明
|
VARCHAR(100)
|
|
num
|
库存
|
INT
|
# 3 、向 books 表中插入记录# 1 )不指定字段名称,插入第一条记录# 2 )指定所有字段名称,插入第二记录# 3 )同时插入多条记录(剩下的所有记录)
|
id
|
name
|
authors
|
price
|
pubdate
|
note
|
num
|
| 1 |
Tal of AAA
|
Dickes
|
23
|
1995
|
novel
|
11
|
| 2 |
EmmaT
|
Jane lura
|
35
|
1993
|
joke
|
22
|
| 3 |
Story of Jane
|
Jane Tim
|
40
|
2001
|
novel
|
0
|
| 4 |
Lovey Day
|
George Byron
|
20
|
2005
|
novel
|
30
|
| 5 |
Old land
|
Honore Blade
|
30
|
2010
|
law
|
0
|
| 6 |
The Battle
|
Upton Sara
|
30
|
1999
|
medicine
|
40
|
| 7 |
Rose Hood
|
Richard haggard
|
28
|
2008
|
cartoon
|
28
|
# 4 、将小说类型 (novel) 的书的价格都增加 5 。# 5 、将名称为 EmmaT 的书的价格改为 40 ,并将说明改为 drama 。# 6 、删除库存为 0 的记录。
# 7 、统计书名中包含 a 字母的书# 8 、统计书名中包含 a 字母的书的数量和库存总量# 9 、找出 “novel” 类型的书,按照价格降序排列# 10 、查询图书信息,按照库存量降序排列,如果库存量相同的按照 note 升序排列# 11 、按照 note 分类统计书的数量# 12 、按照 note 分类统计书的库存量,显示库存量超过 30 本的# 13 、查询所有图书,每页显示 5 本,显示第二页# 14 、按照 note 分类统计书的库存量,显示库存量最多的# 15 、查询书名达到 10 个字符的书,不包括里面的空格# 16 、查询书名和类型,其中 note 值为 novel 显示小说, law 显示法律, medicine 显示医药, cartoon 显示卡通,joke 显示笑话# 17 、查询书名、库存,其中 num 值超过 30 本的,显示滞销,大于 0 并低于 10 的,显示畅销,为 0 的显示需要无货# 18 、统计每一种 note 的库存量,并合计总量# 19 、统计每一种 note 的数量,并合计总量# 20 、统计库存量前三名的图书# 21 、找出最早出版的一本书# 22 、找出 novel 中价格最高的一本书# 23 、找出书名中字数最多的一本书,不含空格
答案:
#1 、创建数据库 test01_libraryCREATE DATABASE IF NOT EXISTS test01_library CHARACTER SET 'utf8' ;# 指定使用哪个数据库USE test01_library;#2 、创建表 booksCREATE TABLE books(id INT ,name VARCHAR ( 50 ),`authors` VARCHAR ( 100 ) ,price FLOAT ,pubdate YEAR ,note VARCHAR ( 100 ),num INT);#3 、向 books 表中插入记录# 1 )不指定字段名称,插入第一条记录INSERT INTO booksVALUES ( 1 , 'Tal of AAA' , 'Dickes' , 23 , 1995 , 'novel' , 11 );# 2 )指定所有字段名称,插入第二记录INSERT INTO books (id,name, `authors` ,price,pubdate,note,num)VALUES ( 2 , 'EmmaT' , 'Jane lura' , 35 , 1993 , 'Joke' , 22 );# 3 )同时插入多条记录(剩下的所有记录)INSERT INTO books (id,name, `authors` ,price,pubdate,note,num) VALUES( 3 , 'Story of Jane' , 'Jane Tim' , 40 , 2001 , 'novel' , 0 ),( 4 , 'Lovey Day' , 'George Byron' , 20 , 2005 , 'novel' , 30 ),( 5 , 'Old land' , 'Honore Blade' , 30 , 2010 , 'Law' , 0 ),( 6 , 'The Battle' , 'Upton Sara' , 30 , 1999 , 'medicine' , 40 ),( 7 , 'Rose Hood' , 'Richard haggard' , 28 , 2008 , 'cartoon' , 28 );# 4 、将小说类型 (novel) 的书的价格都增加 5 。UPDATE books SET price=price+ 5 WHERE note = 'novel' ;# 5 、将名称为 EmmaT 的书的价格改为 40 ,并将说明改为 drama 。UPDATE books SET price= 40 ,note= 'drama' WHERE name= 'EmmaT' ;# 6 、删除库存为 0 的记录。DELETE FROM books WHERE num= 0 ;
# 7 、统计书名中包含 a 字母的书SELECT * FROM books WHERE name LIKE '%a%' ;# 8 、统计书名中包含 a 字母的书的数量和库存总量SELECT COUNT (*), SUM (num) FROM books WHERE name LIKE '%a%' ;# 9 、找出 “novel” 类型的书,按照价格降序排列SELECT * FROM books WHERE note = 'novel' ORDER BY price DESC ;# 10 、查询图书信息,按照库存量降序排列,如果库存量相同的按照 note 升序排列SELECT * FROM books ORDER BY num DESC ,note ASC ;# 11 、按照 note 分类统计书的数量SELECT note, COUNT (*) FROM books GROUP BY note;# 12 、按照 note 分类统计书的库存量,显示库存量超过 30 本的SELECT note, SUM (num) FROM books GROUP BY note HAVING SUM (num)> 30 ;# 13 、查询所有图书,每页显示 5 本,显示第二页SELECT * FROM books LIMIT 5 , 5 ;# 14 、按照 note 分类统计书的库存量,显示库存量最多的SELECT note, SUM (num) sum_num FROM books GROUP BY note ORDER BY sum_num DESC LIMIT 0 , 1 ;# 15 、查询书名达到 10 个字符的书,不包括里面的空格SELECT * FROM books WHERE CHAR_LENGTH( REPLACE (name, ' ' , '' ))>= 10 ;/*16 、查询书名和类型,其中 note 值为 novel 显示小说, law 显示法律, medicine 显示医药, cartoon 显示卡通, joke 显示笑话*/SELECT name AS " 书名 " ,note, CASE noteWHEN 'novel' THEN ' 小说 'WHEN 'law' THEN ' 法律 'WHEN 'medicine' THEN ' 医药 'WHEN 'cartoon' THEN ' 卡通 'WHEN 'joke' THEN ' 笑话 'END AS " 类型 "FROM books;# 17 、查询书名、库存,其中 num 值超过 30 本的,显示滞销,大于 0 并低于 10 的,显示畅销,为 0 的显示需要无货SELECT name,num, CASEWHEN num> 30 THEN ' 滞销 'WHEN num> 0 AND num< 10 THEN ' 畅销 'WHEN num= 0 THEN ' 无货 'ELSE ' 正常 'END AS " 库存状态 "FROM books;# 18 、统计每一种 note 的库存量,并合计总量SELECT IFNULL(note, ' 合计总库存量 ' ) AS note, SUM (num) FROM books GROUP BY note WITHROLLUP ;# 19 、统计每一种 note 的数量,并合计总量SELECT IFNULL(note, ' 合计总数 ' ) AS note, COUNT (*) FROM books GROUP BY note WITH ROLLUP ;# 20 、统计库存量前三名的图书SELECT * FROM books ORDER BY num DESC LIMIT 0 , 3 ;# 21 、找出最早出版的一本书SELECT * FROM books ORDER BY pubdate ASC LIMIT 0 , 1 ;# 22 、找出 novel 中价格最高的一本书SELECT * FROM books WHERE note = 'novel' ORDER BY price DESC LIMIT 0 , 1 ;# 23 、找出书名中字数最多的一本书,不含空格SELECT * FROM books ORDER BY CHAR_LENGTH( REPLACE (name, ' ' , '' )) DESC LIMIT 0 , 1 ;