一、背景
Prometheus单实例,可用性低,可靠性低,不能存储更多数据。
- 解决业务问题
- 如:当前QKE是一个集群+一个项目一个prometheus实例,那么当我一个应用分多个集群部署的时候,查询数据时就得从三个prometheus去查,然后聚合,比较麻烦。用mimir就不存在这个问题
二、介绍
二、Grafana Mimir 核心优势
1、易维护性
Grafana Mimir 的核心优势之一便是易于“安装和维护”。该项目的大量文档、教程和部署工具使其入门起来既快速又简单。Grafana Mimir 的整体模式允许只使用一个二进制文件,不需要额外的依赖项。此外,与 Grafana Mimir 一起打包的最佳实践仪表板、警报和运行手册可以轻松监控系统的健康状况并保持其平稳运行。
2、可扩展性
同时,Grafana Mimir 的水平可扩展架构使其能够处理大量时间序列数据。内部测试表明,该系统可以处理多达 10 亿个活动时间序列,从而实现大规模的可扩展性。这意味着 Grafana Mimir 可以跨多台机器运行,从而能够处理比单个 Prometheus 实例多几个数量级的时间序列。
3、全局视图
除此之外,Grafana Mimir 的另一个关键优势是它能够提供全局的指标视图。该系统使用户能够运行聚合来自多个 Prometheus 实例的系列的查询,从而提供所有系统的全面视图。查询引擎还广泛并行化查询执行,即使是最高基数的查询也能以极快的速度执行。
4、数据持久性
Grafana Mimir 使用对象存储来进行长期数据存储,利用了这种无处不在的、高性价比、高耐久性的技术。该系统与多个对象存储实现兼容,包括 AWS S3、谷歌云存储、Azure Blob 存储、OpenStack Swift 以及任何与 S3 兼容的对象存储。这为用户提供了一种廉价、耐用的方式来存储用于长期分析的指标。
5、通过复制实现高可用性
高可用性是 Grafana Mimir 的另一个关键特性。系统复制传入的指标,确保在机器发生故障时不会丢失任何数据。其水平可扩展架构还意味着它可以在零停机的情况下重启、升级或降级,确保指标摄取或查询不会中断。
6、原生多租户
最后,Grafana Mimir 的原生多租户允许独立团队或业务部门的数据和查询隔离,使这些组可以共享同一个集群。高级限制和服务质量控制确保容量在租户之间公平共享,使其成为拥有多个团队和部门的大型组织的绝佳选择。
二、Prometheus为什么是单实例?
Prometheus一直强调,只做核心功能。
另外,Prometheus 结合 Go 语言的特性和优势,使得 Prometheus 能够以更小的代价抓取并存储更多数据,而 Elasticsearch 或 Cassandra 等 Java 实现的大数据项目处理同样的数据量会消耗更多的资源。也就是说,单实例、不可扩展的 Prometheus 已强大到可以满足大部分用户的需求。
看下:
1.grafana查mimir这个promerheus数据源,看下配置的查询地址是什么,我想知道是不是查的query组件,端口是什么。另外可以f12看看是否有调用请求
* 数据持久化到硬盘的方案里,VictoriaMetrics 是更好的选择
* 数据持久化到对象存储的方案中,Thanos 更受欢迎,Grafana Mimir 更有潜力。
对象存储与本地盘存储
Mimir需要etcd吗?
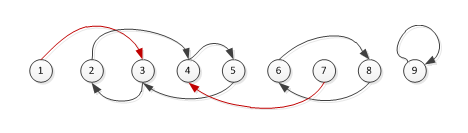
三、Grafana Mimir 分布式架构
Grafana Mimir 的分布式架构可参考如下示意图:

从上图可以看出 Mimir 有 7 个不同的组件,给人的第一印象是一个复杂的系统。值得庆幸的是,helm chart 使事情变得更容易,而且还有根据有效负载提供了资源分配建议。
针对架构中的不同组件功能解析,可以参考如下文件以及源码进行探究,具体如下:
serviceMonitor:
enabled: true
# disabled, external ruler is used
ruler:
enabled: false
# disabled, external alertmanager is used
alertmanager:
enabled: false
# disabled, blocks_storage is used
minio:
enabled: false
compactor:
nodeSelector:
app: mimir
tolerations:
- key: app
value: compactor
operator: Equal
effect: NoSchedule
persistentVolume:
storageClass: standard-rwo
size: 50Gi
resources:
limits:
cpu: 1200m
memory: 2Gi
requests:
cpu: 1200m
memory: 2Gi
distributor:
extraArgs:
distributor.ingestion-rate-limit: "10000000000000"
replicas: 5
nodeSelector:
app: mimir
tolerations:
- key: app
value: distributor
operator: Equal
effect: NoSchedule
resources:
limits:
memory: 4Gi
cpu: 2
requests:
memory: 4Gi
cpu: 2
ingester:
extraArgs:
ingester.max-global-series-per-user: "0"
ingester.max-global-series-per-metric: "0"
nodeSelector:
app: mimir
tolerations:
- key: app
value: ingester
operator: Equal
effect: NoSchedule
persistentVolume:
size: 150Gi
storageClass: standard-rwo
replicas: 5
resources:
limits:
memory: 25Gi
cpu: 4
requests:
memory: 25Gi
cpu: 4
chunks-cache:
nodeSelector:
app: mimir
enabled: true
replicas: 2
index-cache:
nodeSelector:
app: mimir
enabled: true
replicas: 3
metadata-cache:
nodeSelector:
app: mimir
enabled: true
results-cache:
nodeSelector:
app: mimir
enabled: true
overrides_exporter:
nodeSelector:
app: mimir
replicas: 1
resources:
limits:
memory: 256Mi
requests:
cpu: 100m
memory: 128Mi
querier:
extraArgs:
querier.max-fetched-chunks-per-query: "8000000"
replicas: 4
nodeSelector:
app: mimir
tolerations:
- key: app
operator: Equal
value: querier
effect: NoSchedule
resources:
limits:
memory: 24Gi
cpu: 2
requests:
memory: 24Gi
cpu: 2
query_frontend:
replicas: 1
nodeSelector:
app: mimir
tolerations:
- key: app
operator: Equal
value: query-frontend
effect: NoSchedule
resources:
limits:
memory: 6Gi
cpu: 2
requests:
memory: 6Gi
cpu: 2
store_gateway:
persistentVolume:
size: 50Gi
replicas: 1
nodeSelector:
app: mimir
tolerations:
- key: app
operator: Equal
value: store-gateway
effect: NoSchedule
resources:
limits:
cpu: 1
memory: 6Gi
requests:
cpu: 1
memory: 6Gi
mimir:
structuredConfig:
limits:
out_of_order_time_window: 1h
blocks_storage:
backend: gcs
gcs:
bucket_name: <bucket_name>
service_account: |
{<secret>}
metaMonitoring:
serviceMonitor:
enabled: true四、规划 Grafana Mimir 容量
1、估算所需的 CPU 和内存:
Distributor
- CPU:每 25000 个样本每秒 1核。
- 内存:每秒 25000 个样本 1GB。
Ingester
- CPU:内存中每30万个series 1核
- 内存:内存中每30万个series 2.5GB
- 磁盘空间:内存中每30万series 5GB
Query-frontend
- CPU:每秒每 250 个查询需要 1核
- 内存:每秒每 250 个查询需要 1GB
Querier
- CPU:每秒每 10 个查询 1核
- 内存:每秒每 10 个查询需要 1核
Store-gateway
- CPU:每秒每 10 个查询 1 个核心
- 内存:每秒每 10 个查询 1GB
- 磁盘:每 100 万个活动系列 13GB
八、性能测试
1、性能与资源要求
到底谁强?Grafana Mimir 和 VictoriaMetrics 之间的性能测试
根据 Grafana 实验室的测试,Mimir 可以扩展到 10 亿个活跃时间序列和 5000 万个样本/秒的摄取率,该基准测试要求运行一个具有 7000 个 CPU 核心和 30TiB 内存的集群,这已经是我听说的最大、最昂贵的时间序列数据库的公共基准测试了。要重现这样规模的基准测试并不那么容易,幸运的是,在大多数情况下,用户的工作负荷要求要低得多,比较容易模拟。
大型工作负载的建议要求大约 140 个 CPU 和 800GB 内存,用于 1000 万个活跃时间序列。
但对于一个简单的基准测试,显然这要求太高了,所以我从针对 100 万个活跃时间序列的小型工作负载的推荐配置开始,资源要求约为 30 个 CPU 和 200GB 内存。
2、
VictoriaMetrics 平均消耗的 CPU 比 Mimir 少 1.7 倍。
与 Mimir 相比,VictoriaMetrics 使用的内存少了大约 5 倍
Prometheus将时间序列数据写到Mimir
1、

十一、租户管理
针对不同租户配置存储周期,写入qps,查询qps
在 Mimir/Cortex 中,默认一份数据从 distributor 会写 3 份到不同 ingester 节点,这样做的目的是想通过多副本复制的方式实现数据存储的高可靠。
HATracker ,同一 cluster 的数据,在 distributor 实现了去重,从而只有一个 agent 的数据写到了 ingester。
十二、告警规则可视化编辑:mimir
十三、组件介绍
Mimir可选组件: alertmanager,ruler,overrides-exporter,query-scheduler
Mimir必选组件:compactor,distributor,ingester,querier,query-frontend,store-gateway
各个组件的作用详细介绍参考:
使用 Grafana Mimir 实现云原生监控报警可视化
https://mp.weixin.qq.com/s?__biz=MzAxODcyNjEzNQ==&mid=2247570788&idx=3&sn=464f12dca1150cb5ce9190246a021b93&chksm=9bd278fcaca5f1eab4247d7875557932eb0b390aae3aa0a7bfc60627d4f6a6c1e5e88a718b17&scene=27#wechat_redirect
十四、distributor(数据分发器)
分发服务器是一个无状态组件,从 Prometheus 或 Grafana 代理接收时间序列数据。分发服务器验证数据的正确性,并确保数据在给定租户的配置限制内。然后,分发服务器将数据分为多个批次,并将其并行发送给多个接收程序,在接收程序之间切分序列,并通过配置的复制因子复制每个序列。默认情况下,配置的复制因子为 3。
工作原理
验证
分发服务器在将数据写入 ingester 之前验证其接收的数据。因为单个请求可以包含有效和无效的度量、样本、元数据和样本,所以分发服务器只将有效数据传递给 ingester。分发服务器在其对接收程序的请求中不包含无效数据。如果请求包含无效数据,分发服务器将返回 400 HTTP 状态代码,详细信息将显示在响应正文中。关于第一个无效数据的详细信息无论是普罗米修斯还是格拉夫纳代理通常由发送方记录。分发器验证包括以下检查:
* 度量元数据和标签符合普罗米修斯公开格式。
* 度量元数据(名称、帮助和单位)的长度不超过通过 validation.max-metadata-length 定义的长度
* 每个度量的标签数不高于-validation.max-label-names-per-series
* 每个度量标签名称不得长于-validation.max-length-label-name
* 每个公制标签值不长于-validation.max-length-label-value
* 每个样本时间戳都不晚于-validation.create-grace-period
* 每个示例都有一个时间戳和至少一个非空标签名称和值对。
* 每个样本不超过 128 个标签。
速率限制
分发器包括适用于每个租户的两种不同类型的费率限制。
* 请求速率
每个租户每秒可以跨 Grafana Mimir 集群处理的最大请求数。
* 接受速率
每个租户在 Grafana Mimir 集群中每秒可接收的最大样本数。如果超过其中任何一个速率,分发服务器将丢弃请求并返回 HTTP 429 响应代码。
在内部,这些限制是使用每个分发器的本地速率限制器实现的。每个分发服务器的本地速率限制器都配置了 limit/N,其中 N 是正常分发服务器副本的数量。如果分发服务器副本的数量发生变化,分发服务器会自动调整请求和接收速率限制。因为这些速率限制是使用每个分发服务器的本地速率限制器实现的,所以它们要求写入请求在分发服务器池中均匀分布。可以通过下面的这几个参数进行限制:
-distributor.request-rate-limit
-distributor.request-burst-size
-distributor.ingestion-rate-limit
-distributor.ingestion-burst-size
高可用跟踪器
远程写发送器(如 Prometheus)可以成对配置,这意味着即使其中一个远程写发送机停机进行维护或由于故障而不可用,度量也会继续被擦除并写入 Grafana Mimir。我们将此配置称为高可用性(HA)对。分发服务器包括一个 HA 跟踪器。启用 HA 跟踪器后,分发服务器会对来自 Prometheus HA 对的传入序列进行重复数据消除。这使您能够拥有同一 Prometheus 服务器的多个 HA 副本,将同一系列写入 Mimir,然后在 Mimir 分发服务器中对该系列进行重复数据消除。
切分和复制
分发服务器在 ingester 之间切分和复制传入序列。您可以通过-ingester.ring.replication-factor 配置每个系列写入的摄取器副本的数量。复制因子默认为 3。分发者使用一致哈希和可配置的复制因子来确定哪些接收者接收给定序列。切分和复制使用 ingester 的哈希环。对于每个传入的序列,分发服务器使用度量名称、标签和租户 ID 计算哈希。计算的哈希称为令牌。分发服务器在哈希环中查找令牌,以确定向哪个接收程序写入序列。
十五、ingester(数据接收器)
接收程序是一个有状态组件,它将传入序列写入长期存储的写路径,并返回读取路径上查询的序列样本。
工作原理
来自分发服务器的传入序列不会立即写入长期存储,而是保存在接收服务器内存中或卸载到接收服务器磁盘。最终,所有系列都会写入磁盘,并定期(默认情况下每两小时)上传到长期存储。因此,查询器可能需要在读取路径上执行查询时,从接收器和长期存储中获取样本。任何调用接收器的 Mimir 组件都首先查找哈希环中注册的接收器,以确定哪些接收器可用。每个接收器可能处于以下状态之一:
pending
joining
active
leaving
unhealthy
写放大
Ingers 将最近收到的样本存储在内存中,以便执行写放大。如果接收器立即将收到的样本写入长期存储,由于长期存储的高压,系统将很难缩放。由于这个原因,接收器在内存中对样本进行批处理和压缩,并定期将它们上传到长期存储。写反放大是 Mimir 低总体拥有成本(TCO)的主要来源。
接收失败和数据丢失
如果接收程序进程崩溃或突然退出,则所有尚未上载到长期存储的内存中序列都可能丢失。有以下方法可以缓解这种故障模式:
* Replication
* Write-ahead log (WAL)
* Write-behind log (WBL), out-of-order 启用时
区域感知复制
区域感知复制可确保给定时间序列的接收副本跨不同的区域进行划分。分区可以表示逻辑或物理故障域,例如,不同的数据中心。跨多个区域划分副本可防止在整个区域发生停机时发生数据丢失和服务中断。
十六、querier(数据查询器)
1、介绍
查询器是一个无状态组件,它通过在读取路径上获取时间序列和标签来评估 PromQL 表达式,使用存储网关组件查询长期存储,使用接收组件查询最近写入的数据。
工作原理
为了在查询时查找正确的块,查询器需要一个关于长期存储中存储桶的最新视图。查询器只需要来自 bucket 的元数据信息的,元数据包括块内样本的最小和最大时间戳。查询器执行以下操作之一,以确保更新 bucket 视图:
定期下载 bucket 索引(默认)
定期扫描 bucket
二、案例
地址:http://10.41.26.131:9009/prometheus/api/v1/query?query=up

十七、query-frontend(查询前端)
查询前端是一个无状态组件,它提供与查询器相同的 API,并可用于加快读取路径。尽管查询前端不是必需的,但我们建议您部署它。部署查询前端时,应该向查询前端而不是查询器发出查询请求。集群中需要查询器来执行查询,在内部队列中保存查询。在这种情况下,查询器充当从队列中提取作业、执行作业并将结果返回到查询前端进行聚合的工作者。要将查询器与查询前端连接,通过-querier.frontend-address 配置,在使用高可用情况下建议部署至少 2 个查询前端。
拆分
查询前端可以将远程查询拆分为多个查询。默认情况下,分割间隔为 24 小时。查询前端在下游查询器中并行执行这些查询,并将结果组合在一起。拆分可防止大型多天或多月查询导致查询器内存不足错误,并加快查询执行速度。
store-gateway(数据存储网关)
存储网关组件是有状态的,它查询来自长期存储的块。在读取路径上,querier 和 ruler 在处理查询时使用存储网关,无论查询来自用户还是来自正在评估的规则。为了在查询时找到要查找的正确块,存储网关需要一个关于长期存储中存储桶的最新视图。
十八、Alertmanager
Mimir Alertmanager 为 Prometheus Alertmanagers 添加了多租户支持和水平伸缩性。Mimir Alertmanager 是一个可选组件,它接受来自 Mimir 标尺的警报通知。Alertmanager 对警报通知进行重复数据消除和分组,并将其路由到通知通道,如电子邮件、PagerDuty 或 OpsGenie。
十九、query-scheduler
查询调度程序是一个可选的无状态组件,它保留要执行的查询队列,并将工作负载分配给可用的查询器。
Override-exporter
Mimir 支持按租户应用覆盖。许多覆盖配置了限制,以防止单个租户使用过多资源。覆盖导出器组件将限制公开为普罗米修斯度量,以便运营商了解租户与其限制的接近程度。
指定配置文件:
/usr/local/mimir/mimir-darwin-amd64 --config.file /usr/local/mimir/mimir.yaml
Mimir alertmanager:
$ mimirtool alertmanager load ./alertmanager.yaml --address http://127.0.0.1:8080 --id annoymous
下面这就是报警规则前端,可以界面方式创建告警规则:
思考下,查询也是用grafana吧?
多租户配置:
更改配置文件中 multitenancy_enabled: true
上传 alertmanager 配置文件 (instance_id 一般为配置的 node 名称 , 可以自定义)
mimirtool作用?研究下
$ mimirtool alertmanager load ./alertmanager.yaml --address http://127.0.0.1:8080 --id instance_id
找一些微信或qq交流群
对opentelemetry支持主要是对oltp协议支持,即一般是用户程序使用了opentelemetry的SDK采集数据后不用非得上报到opentelemetry collector,也可以直接上报到mimir,这样用户就不用搭建多种收集服务了。
Mimir 原生支持 Oltp 协议后,我们可以使用 OpenTelemetry SDK 统一导出为 OLTP,后面无论推送到 Mimir ,还是经过 collector 进行 OTLP 的转发,应用侧始终只有一种数据格式
配置下target试试,然后看下配置的效果
通过 Mimir 我们非常方便实现 Prometheus 规则评估和告警管理的高可用,它不仅提供了开箱即用的 mimir-tool 实现日常运维管理,还打通了 Grafana 看板,方便租户通过 Grafana 看板进行自定义配置,这样一来 Grafana 看板完全成为一个无状态服务,其规则和告警管理配置数据持续化和一致性由 Mimir 来保障。


![[附源码]计算机毕业设计基于SSM和UNIAPP的选课APP](https://img-blog.csdnimg.cn/46e7ec135d0d432f842f0bfa4d94af5b.jpeg)